RAG Enhanced NCERT Tutor
1.0.0
This project implements a Retrieval-Augmented Generation (RAG) system for NCERT books using Ollama for text embedding and vector database, and Groq API for the language model response.
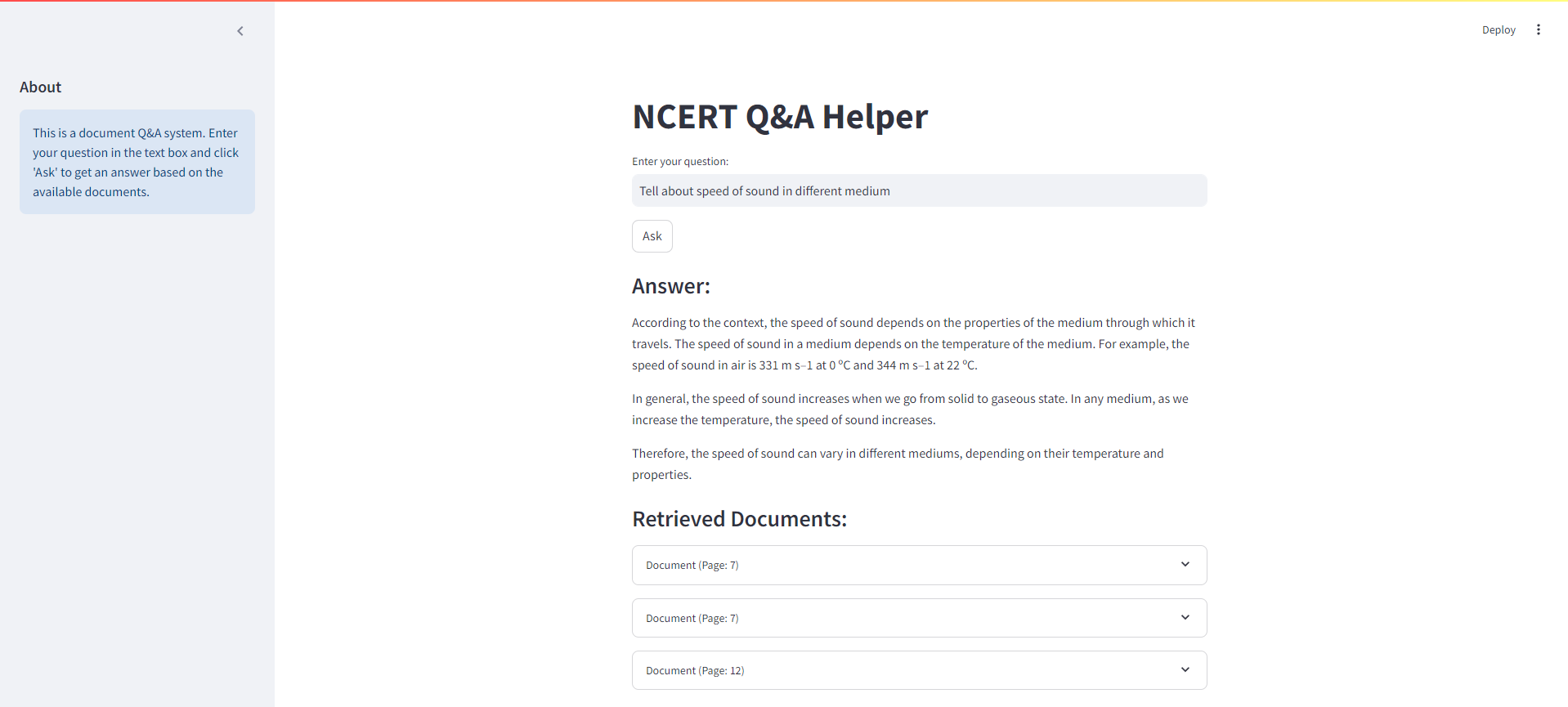
Below is a screenshot of the Streamlit interface for our NCERT Books RAG system:
Here's an overview of the NCERT Books RAG system architecture:
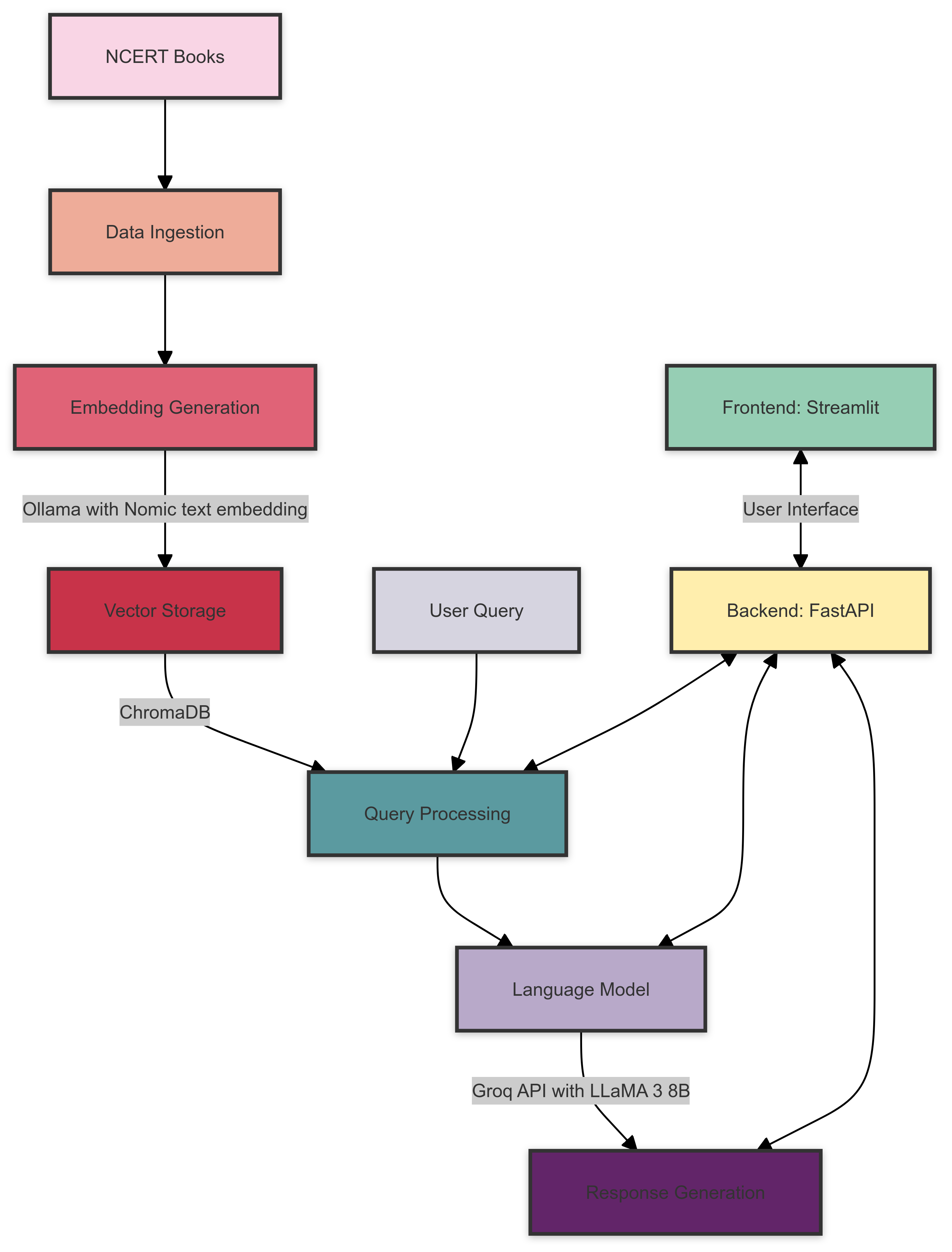
The system architecture consists of the following components:
Before you begin, ensure you have met the following requirements:
Clone the repository:
git clone https://github.com/yourusername/ncert-rag-system.git
cd ncert-rag-system
Install the required dependencies:
pip install -r requirements.txt
Download and set up Ollama:
ollama pull nomic-embed-text
Set up your Groq API key:
.env file in the project rootGROQ_API_KEY=your_api_key_here
Start the FastAPI backend:
uvicorn main:app --reload
Launch the Streamlit UI:
streamlit run streamlit_app.py
Open your web browser and navigate to the Streamlit app URL (typically http://localhost:8501)
Use the interface to interact with the NCERT books RAG system
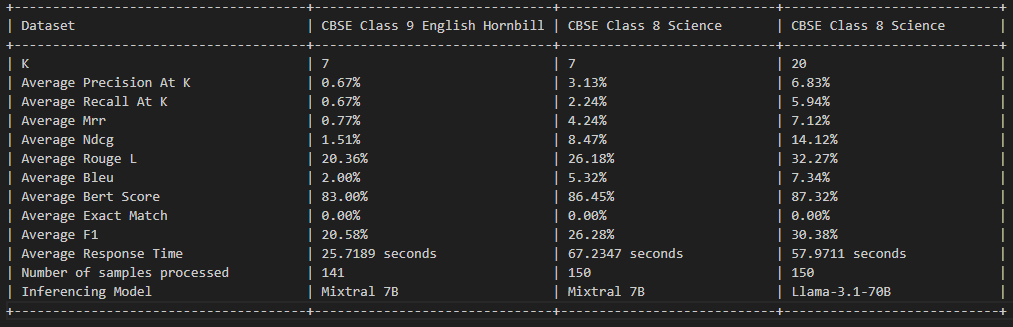
This project is licensed under the MIT License - see the LICENSE file for details.
Contributions are welcome! Please feel free to submit a Pull Request.


