RAG Enhanced NCERT Tutor
1.0.0
Este projeto implementa um sistema de geração de recuperação de recuperação (RAG) para livros NCERT usando o Ollama para incorporação de texto e banco de dados de vetores e API GROQ para a resposta do modelo de idioma.
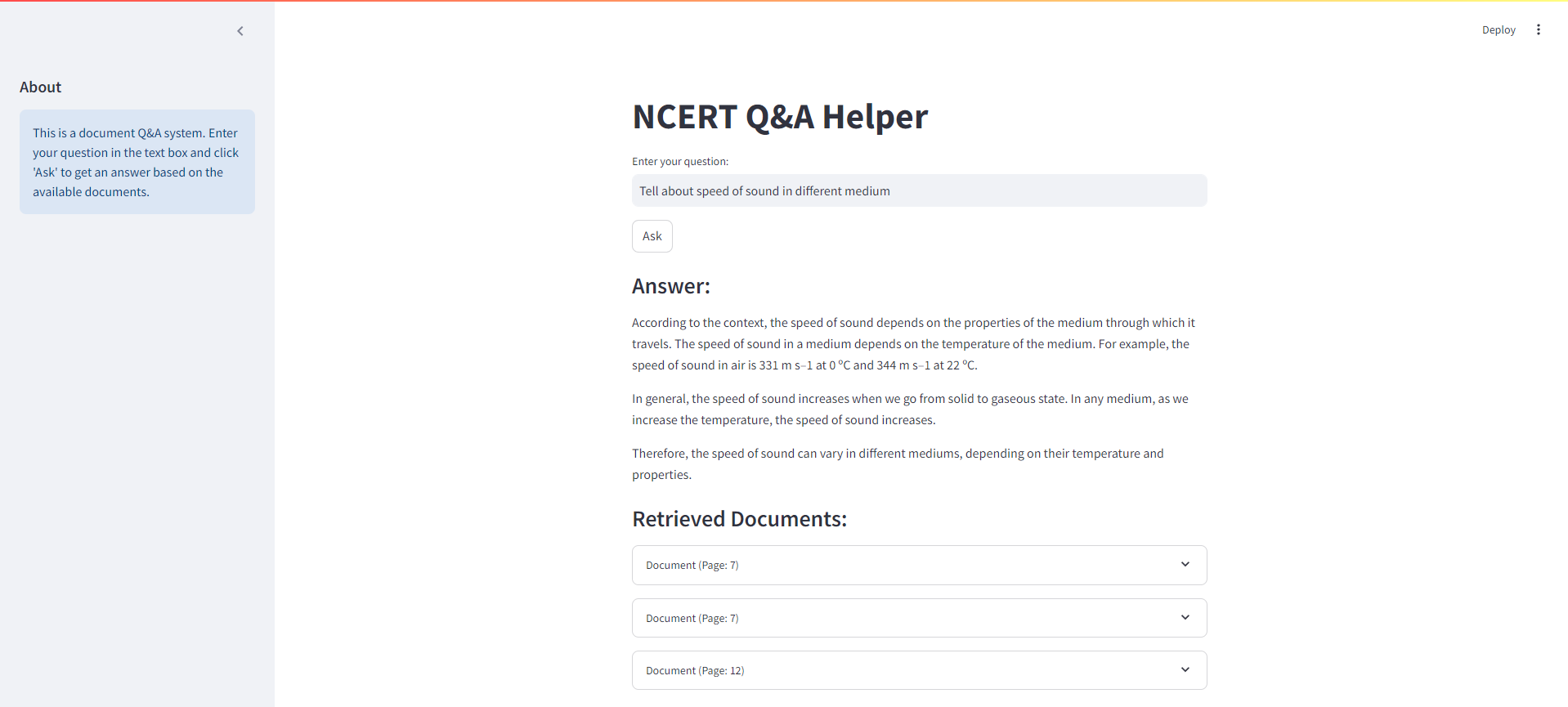
Abaixo está uma captura de tela da interface Streamlit para o nosso sistema de trapos de livros NCERT:
Aqui está uma visão geral da arquitetura do sistema de trapos do NCERT Books:
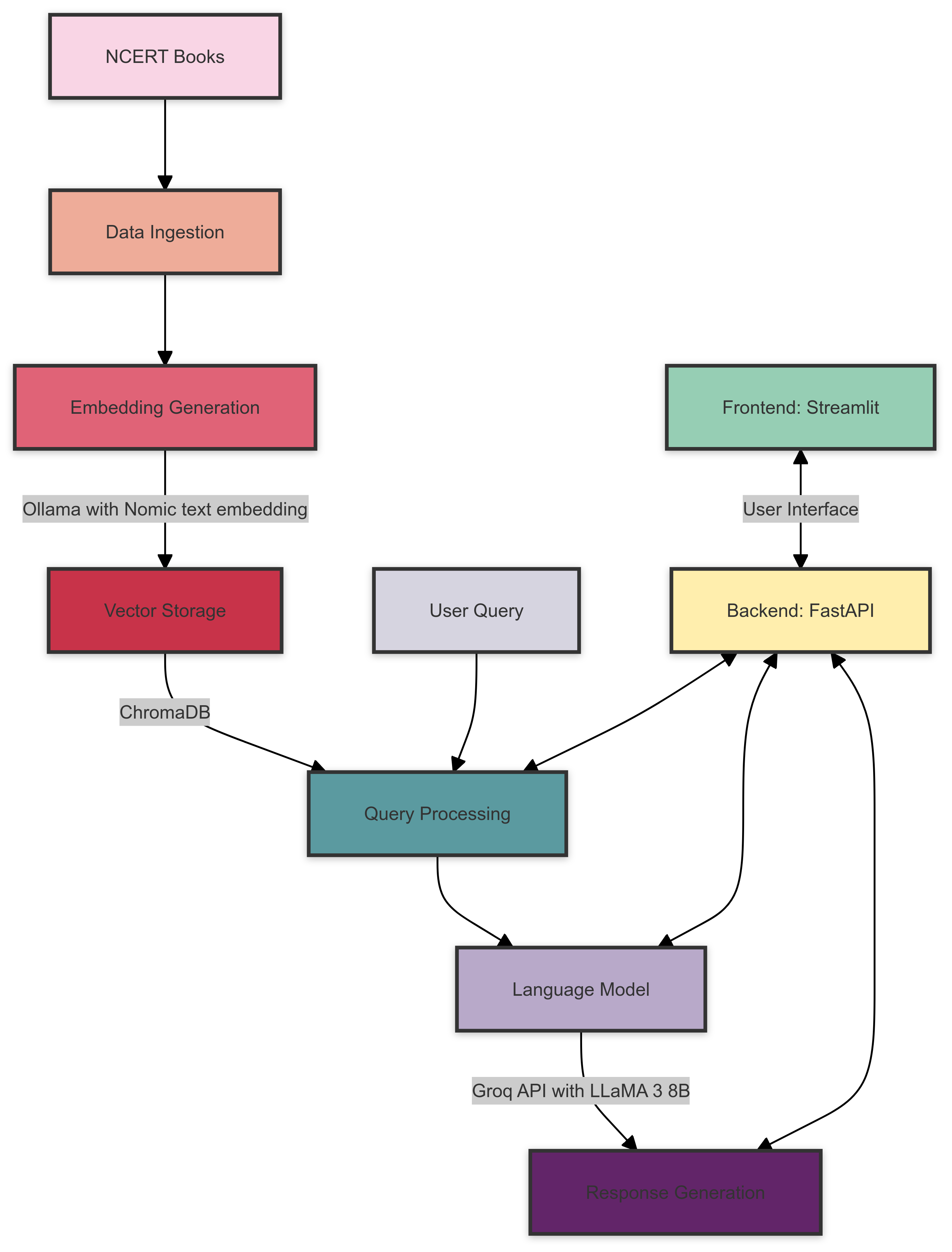
A arquitetura do sistema consiste nos seguintes componentes:
Antes de começar, verifique se você atendeu aos seguintes requisitos:
Clone o repositório:
git clone https://github.com/yourusername/ncert-rag-system.git
cd ncert-rag-system
Instale as dependências necessárias:
pip install -r requirements.txt
Faça o download e configure o ollama:
ollama pull nomic-embed-text
Configure sua tecla API Groq:
.env na raiz do projeto GROQ_API_KEY=your_api_key_here
Inicie o back -end do FASTAPI:
uvicorn main:app --reload
Inicie a interface do usuário do streamlit:
streamlit run streamlit_app.py
Abra seu navegador da web e navegue até o URL do aplicativo StreamLit (normalmente http://localhost:8501 )
Use a interface para interagir com o NCERT Books Rag System
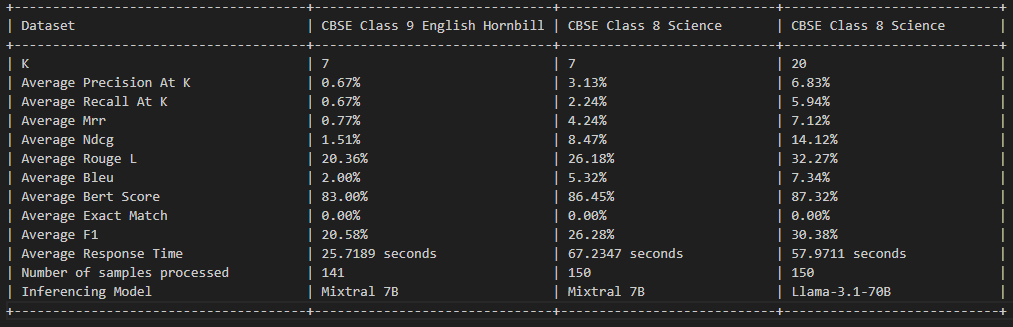
Este projeto está licenciado sob a licença do MIT - consulte o arquivo de licença para obter detalhes.
As contribuições são bem -vindas! Sinta -se à vontade para enviar uma solicitação de tração.


