RAG Enhanced NCERT Tutor
1.0.0
Dieses Projekt implementiert ein RAG-System (Abruf-Augmented-Generation) für NCERT-Bücher, die Ollama für Texteinbettung und Vektordatenbank sowie die GROQ-API für die Reaktion des Sprachmodells verwenden.
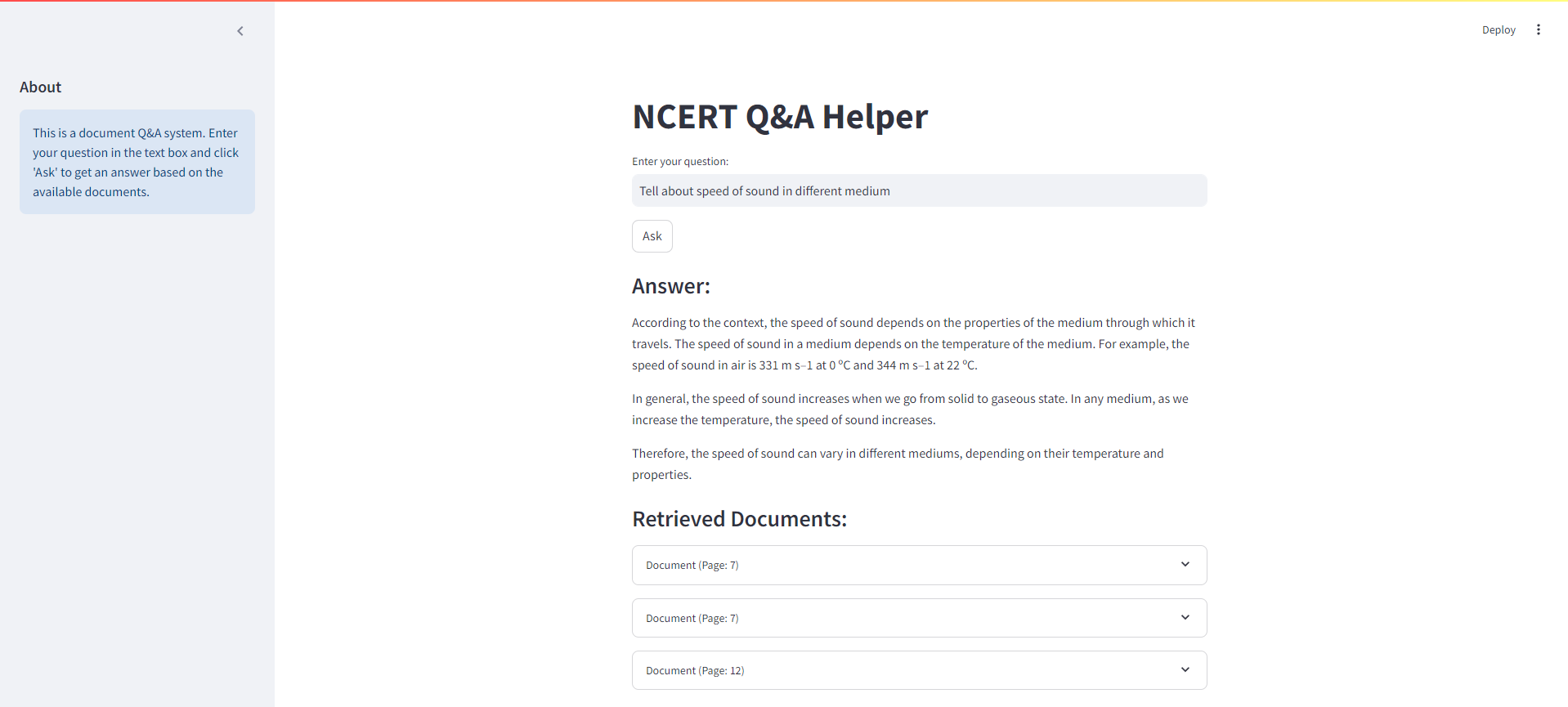
Unten finden Sie einen Screenshot der optimistischen Schnittstelle für unser NCERT -Bücher -Rag -System:
Hier ist ein Überblick über die NCERT Books Rag -Systemarchitektur:
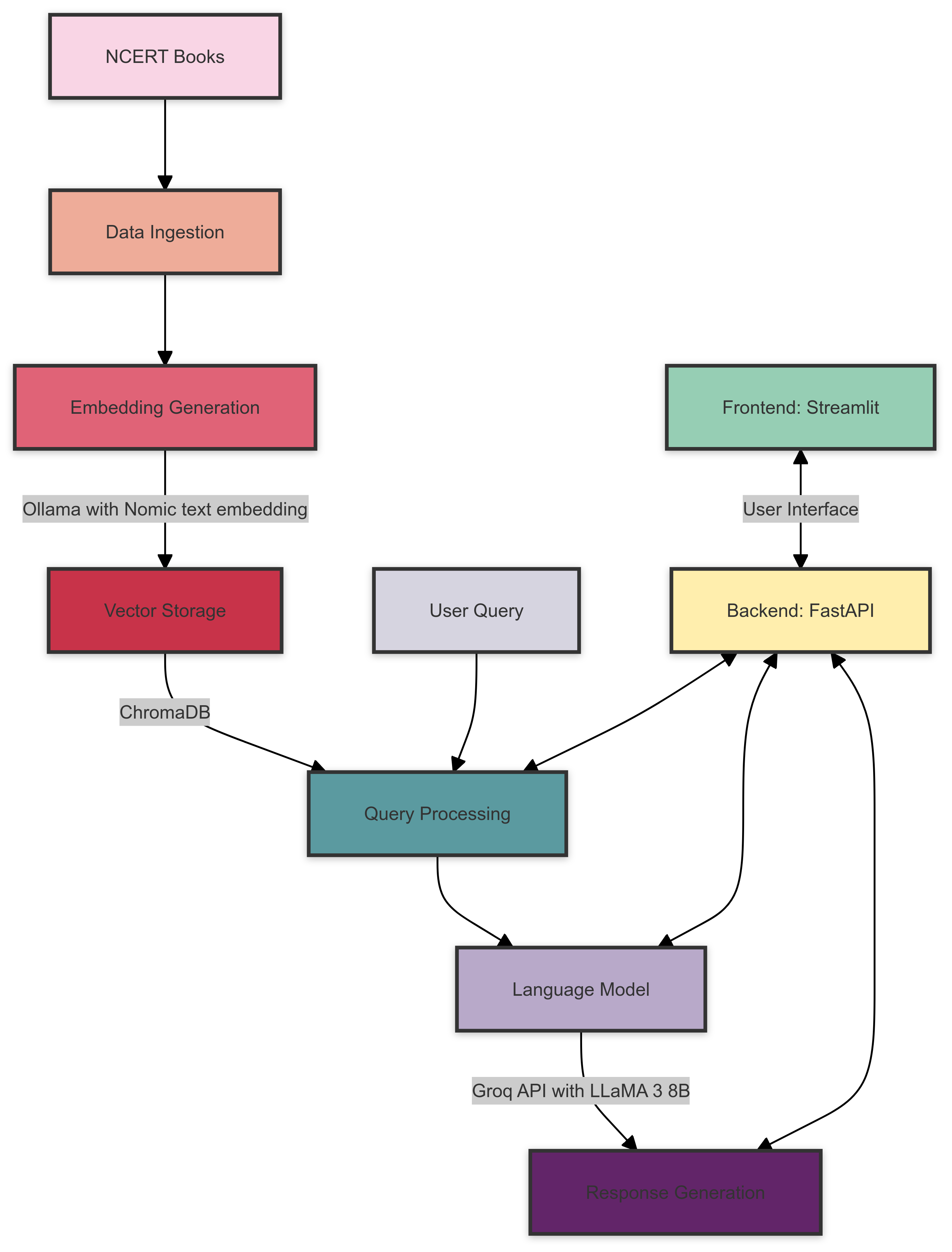
Die Systemarchitektur besteht aus den folgenden Komponenten:
Stellen Sie vor Beginn sicher, dass Sie die folgenden Anforderungen erfüllt haben:
Klonen Sie das Repository:
git clone https://github.com/yourusername/ncert-rag-system.git
cd ncert-rag-system
Installieren Sie die erforderlichen Abhängigkeiten:
pip install -r requirements.txt
Download und einrichten Ollama:
ollama pull nomic-embed-text
Richten Sie Ihren COQ -API -Schlüssel ein:
.env -Datei im Projektstamm GROQ_API_KEY=your_api_key_here
Starten Sie das Fastapi -Backend:
uvicorn main:app --reload
Starten Sie die optimistische Benutzeroberfläche:
streamlit run streamlit_app.py
Öffnen Sie Ihren Webbrowser und navigieren Sie zur Stromlit -App -URL (normalerweise http://localhost:8501 )
Verwenden Sie die Schnittstelle, um mit dem NCERT Books Rag -System zu interagieren
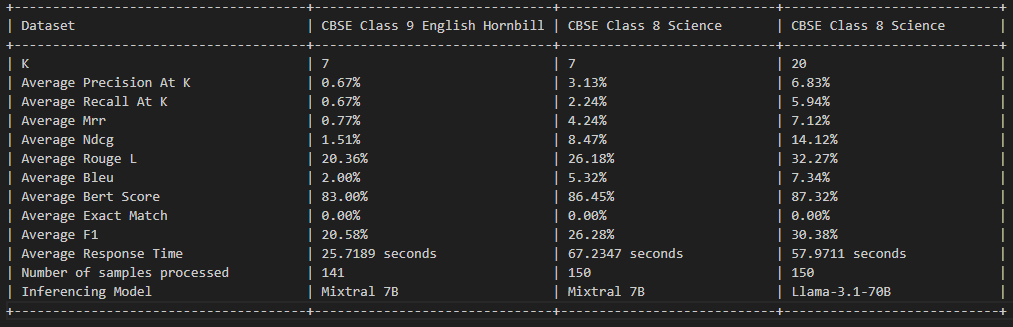
Dieses Projekt ist unter der MIT -Lizenz lizenziert - Einzelheiten finden Sie in der Lizenzdatei.
Beiträge sind willkommen! Bitte zögern Sie nicht, eine Pull -Anfrage einzureichen.


