onnxt5
ve model
Суммизация, перевод, вопросы и ответы, генерация текста и многое другое со скоростью плазки с использованием версии T5, реализованной в Onnx.
Этот пакет по -прежнему находится на стадии альфа, поэтому некоторые функции, такие как поиск луча, все еще находятся в разработке.
ONNX-T5 доступен на PYPI.
pip install onnxt5Для версии DEV вы можете запустить следующее.
git clone https://github.com/abelriboulot/onnxt5
cd onnxt5
pip install -e . Самый простой способ начать генерацию-использовать предварительно обученную версию T5 по умолчанию на ONNX, включенную в пакет.
Примечание. Обратите внимание, что в первый раз, когда вы называете get_encoder_decoder_tokenizer, модели загружаются, что может занять минуту или две.
from onnxt5 import GenerativeT5
from onnxt5 . api import get_encoder_decoder_tokenizer
decoder_sess , encoder_sess , tokenizer = get_encoder_decoder_tokenizer ()
generative_t5 = GenerativeT5 ( encoder_sess , decoder_sess , tokenizer , onnx = True )
prompt = 'translate English to French: I was a victim of a series of accidents.'
output_text , output_logits = generative_t5 ( prompt , max_length = 100 , temperature = 0. )
# output_text: "J'ai été victime d'une série d'accidents."Другие задачи просто требуют изменения префикса в вашей подсказке, например, для суммирования:
prompt = 'summarize: <PARAGRAPH>'
output_text , output_logits = generative_t5 ( prompt , max_length = 100 , temperature = 0. )Если вы хотите получить вставки текста, вы можете запустить следующее
from onnxt5 . api import get_encoder_decoder_tokenizer , run_embeddings_text
decoder_sess , encoder_sess , tokenizer = get_encoder_decoder_tokenizer ()
prompt = 'Listen, Billy Pilgrim has come unstuck in time.'
encoder_embeddings , decoder_embeddings = run_embeddings_text ( encoder_sess , decoder_sess , tokenizer , prompt ) ONNXT5 также позволяет экспортировать и использовать свои собственные модели. См. examples Папка для более подробных примеров.
T5 работает с токенами, такими как summarize: translate English to German: или question: ... context: . Вы можете увидеть список предварительных задач и токена в приложении D оригинальной статьи.
Превосходство варьируется в значительной степени в зависимости от длины контекста. Для контекстов меньше ~ 500 слов, ONNX значительно превосходит, поднимаясь до 4 -кратного ускорения по сравнению с Pytorch. Тем не менее, чем дольше контекст, тем меньше ускорение ONNX, при этом питор был быстрее выше 500 слов.
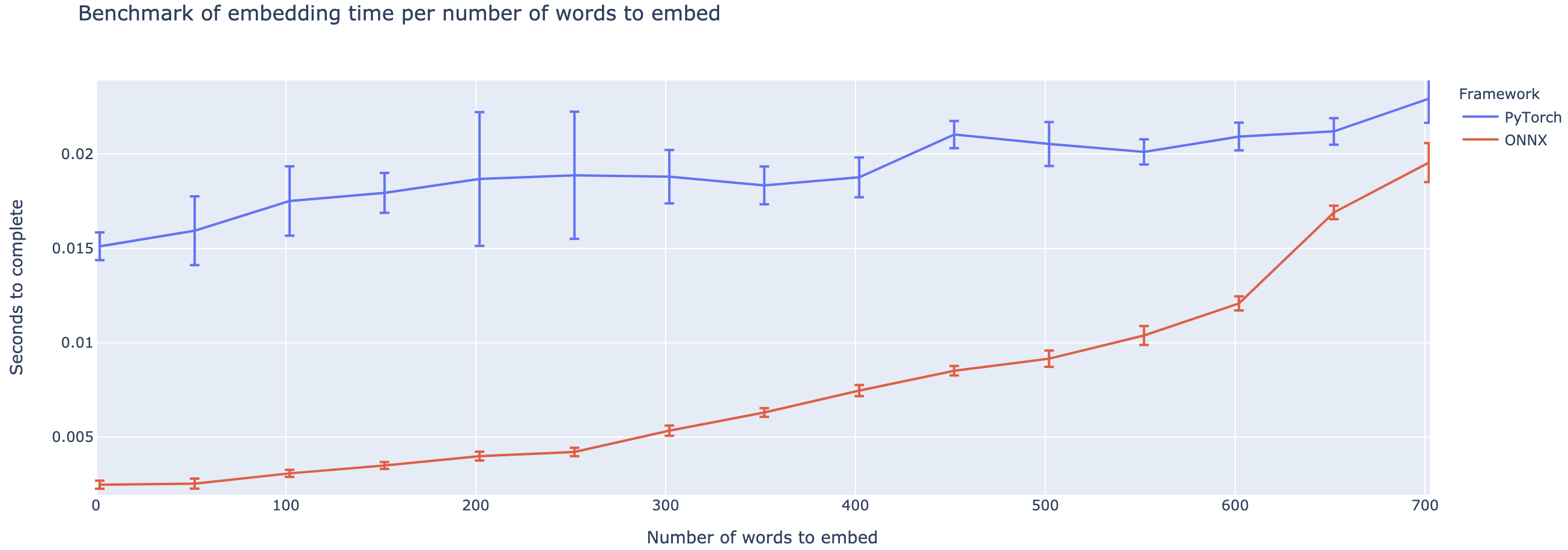
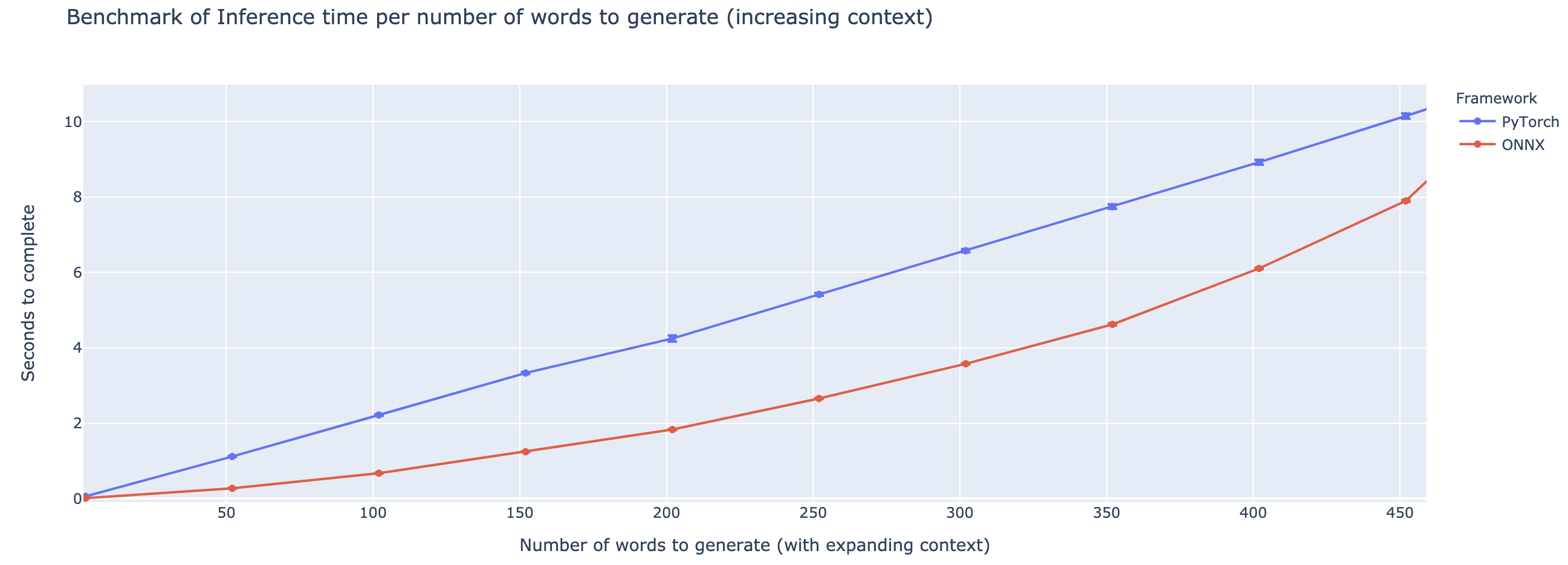
Проект все еще находится в зачаточном состоянии, поэтому я хотел бы получить ваши отзывы, узнать, какие проблемы вы пытаетесь решить, услышать проблемы, с которыми вы сталкиваетесь, и обсудить функции, которые помогут вам. Поэтому не стесняйтесь выстрелить мне по электронной почте (см. Мой профиль по адресу!) Или присоединяйтесь к нашему сообществу Slack.
Этот репо основан на работе Колина Раффела и Ноам Шазира, Адама Робертса, Кэтрин Ли, а также Шарана Наранга, Майкла Матена и Яньки Чжоу и Вей Ли и Питера Дж. Лю из Google, а также в реализации T5 из команды Huggingface, работы Microsoft Onnnx и OnnxRuntime Teams, в частности Tianlei, и в этом и работах.
Оригинальная бумага T5
@article{2019t5,
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
journal = {arXiv e-prints},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.10683},
}
Microsoft Onnxruntime Repo
Реализация объятий T5


