onnxt5
ve model
ONNX에서 구현 된 T5 버전을 사용하여 요약, 번역, Q & A, 텍스트 생성 등을 사용하여 더 많은 속도로.
이 패키지는 여전히 알파 단계에 있으므로 빔 검색과 같은 일부 기능이 여전히 개발 중입니다.
ONNX-T5는 PYPI에서 사용할 수 있습니다.
pip install onnxt5DEV 버전의 경우 다음을 실행할 수 있습니다.
git clone https://github.com/abelriboulot/onnxt5
cd onnxt5
pip install -e . 세대를 시작하는 가장 간단한 방법은 패키지에 포함 된 ONNX에서 기본 미리 훈련 된 T5 버전을 사용하는 것입니다.
참고 : 처음으로 get_encoder_decoder_tokenizer를 호출 할 때는 1 분 또는 2 분이 걸릴 수있는 모델을 다운로드하고 있습니다.
from onnxt5 import GenerativeT5
from onnxt5 . api import get_encoder_decoder_tokenizer
decoder_sess , encoder_sess , tokenizer = get_encoder_decoder_tokenizer ()
generative_t5 = GenerativeT5 ( encoder_sess , decoder_sess , tokenizer , onnx = True )
prompt = 'translate English to French: I was a victim of a series of accidents.'
output_text , output_logits = generative_t5 ( prompt , max_length = 100 , temperature = 0. )
# output_text: "J'ai été victime d'une série d'accidents."다른 작업은 요약을 위해 프롬프트에서 접두사를 변경하면됩니다.
prompt = 'summarize: <PARAGRAPH>'
output_text , output_logits = generative_t5 ( prompt , max_length = 100 , temperature = 0. )텍스트의 포함을 받으려면 다음을 실행할 수 있습니다.
from onnxt5 . api import get_encoder_decoder_tokenizer , run_embeddings_text
decoder_sess , encoder_sess , tokenizer = get_encoder_decoder_tokenizer ()
prompt = 'Listen, Billy Pilgrim has come unstuck in time.'
encoder_embeddings , decoder_embeddings = run_embeddings_text ( encoder_sess , decoder_sess , tokenizer , prompt ) ONNXT5를 사용하면 자신의 모델을 내보내고 사용할 수 있습니다. 자세한 내용은 examples 폴더를 참조하십시오.
T5는 summarize: , translate English to German: 것과 같은 토큰과 함께 작동합니다 : 또는 question: ... context: . 원래 논문의 부록 D에서 사전에 사전 된 작업과 토큰 목록을 볼 수 있습니다.
성능은 컨텍스트의 길이에 따라 크게 다릅니다. ~ 500 단어 미만의 컨텍스트의 경우 Onnx는 Pytorch에 비해 4 배 속도로 올라가는 성능이 뛰어납니다. 그러나 컨텍스트가 길수록 Onnx의 속도가 작고 Pytorch는 500 단어 이상으로 빠릅니다.
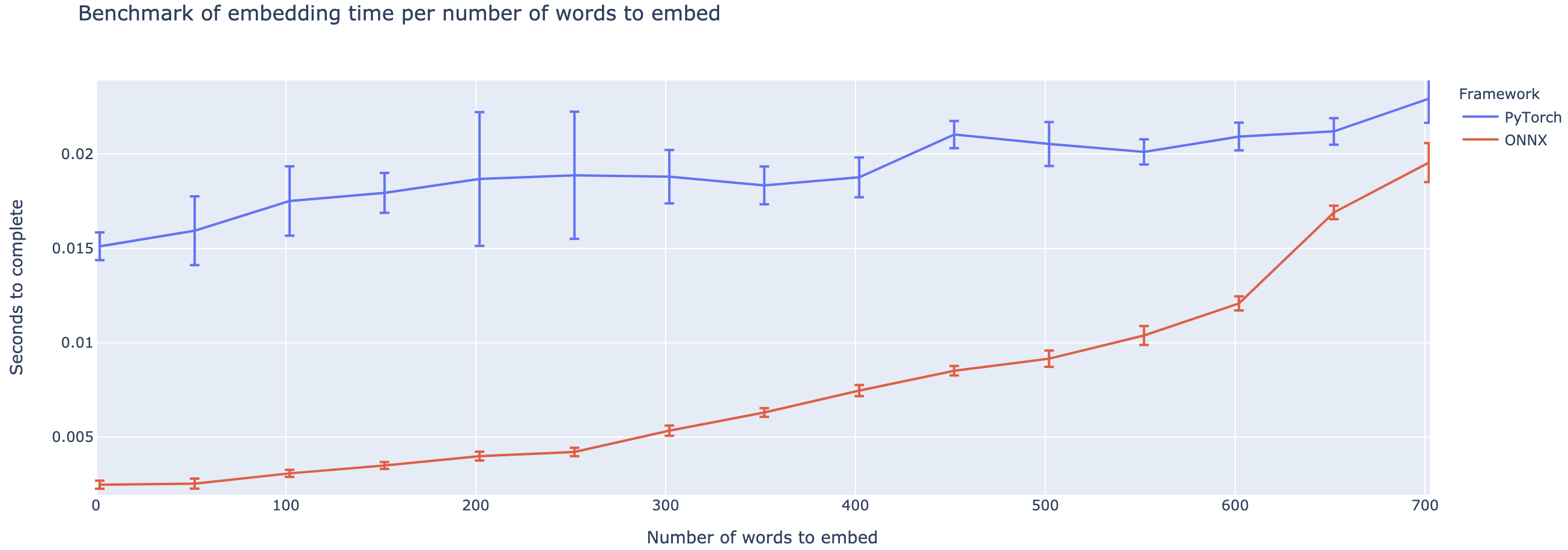
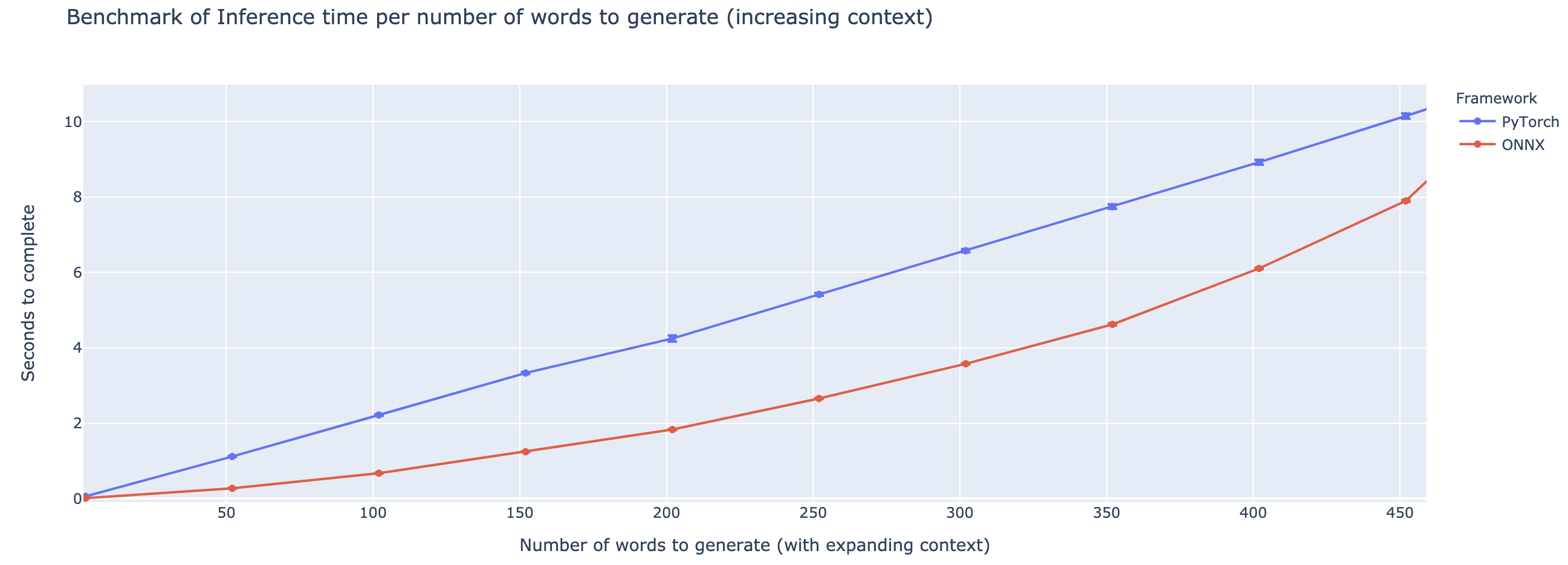
이 프로젝트는 아직 초기 단계에 있으므로 피드백을 좋아하고, 해결하려는 문제를 알고, 발생하는 문제를 듣고, 도움이되는 기능에 대해 논의하기를 원합니다. 그러므로 저에게 이메일을 보내거나 (주소에 대한 나의 프로필 참조) 슬랙 커뮤니티에 가입하십시오.
이 저장소는 Colin Raffel과 Noam Shazeer와 Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou와 Wei Li와 Peter J. Liu의 작품과 Google의 Huggingface 팀의 T5를 구현 한 것입니다.
원래 T5 용지
@article{2019t5,
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
journal = {arXiv e-prints},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.10683},
}
Microsoft OnnxRuntime Repo
T5의 Huggingface 구현


