onnxt5
ve model
Resumo, tradução, perguntas e respostas, geração de texto e muito mais em velocidade em chamas usando uma versão T5 implementada no ONNX.
Este pacote ainda está em estágio alfa; portanto, algumas funcionalidades, como pesquisas de feixe, ainda estão em desenvolvimento.
Onnx-T5 está disponível no Pypi.
pip install onnxt5Para a versão de desenvolvimento, você pode executar o seguinte.
git clone https://github.com/abelriboulot/onnxt5
cd onnxt5
pip install -e . A maneira mais simples de começar para a geração é usar a versão pré-treinada padrão do T5 OnNX incluída no pacote.
NOTA: Observe que a primeira vez que você chama get_encoder_decoder_tokenizer, os modelos estão sendo baixados, o que pode levar um ou dois minutos.
from onnxt5 import GenerativeT5
from onnxt5 . api import get_encoder_decoder_tokenizer
decoder_sess , encoder_sess , tokenizer = get_encoder_decoder_tokenizer ()
generative_t5 = GenerativeT5 ( encoder_sess , decoder_sess , tokenizer , onnx = True )
prompt = 'translate English to French: I was a victim of a series of accidents.'
output_text , output_logits = generative_t5 ( prompt , max_length = 100 , temperature = 0. )
# output_text: "J'ai été victime d'une série d'accidents."Outras tarefas precisam apenas alterar o prefixo em seu prompt, por exemplo, para resumo:
prompt = 'summarize: <PARAGRAPH>'
output_text , output_logits = generative_t5 ( prompt , max_length = 100 , temperature = 0. )Se você quiser obter as incorporações do texto, você pode executar o seguinte
from onnxt5 . api import get_encoder_decoder_tokenizer , run_embeddings_text
decoder_sess , encoder_sess , tokenizer = get_encoder_decoder_tokenizer ()
prompt = 'Listen, Billy Pilgrim has come unstuck in time.'
encoder_embeddings , decoder_embeddings = run_embeddings_text ( encoder_sess , decoder_sess , tokenizer , prompt ) Onnxt5 também permite exportar e usar seus próprios modelos. Veja os examples Pasta para obter exemplos mais detalhados.
T5 trabalha com tokens como summarize: , translate English to German: ou question: ... context: . Você pode ver uma lista das tarefas pré -treinadas e token no apêndice D do artigo original.
O desempenho superior varia fortemente com base na duração do contexto. Para contextos inferiores a ~ 500 palavras, o ONNX supera bastante, subindo a uma aceleração 4x em comparação com o pytorch. No entanto, quanto maior o contexto, menor a aceleração do ONNX, com Pytorch sendo mais rápido acima de 500 palavras.
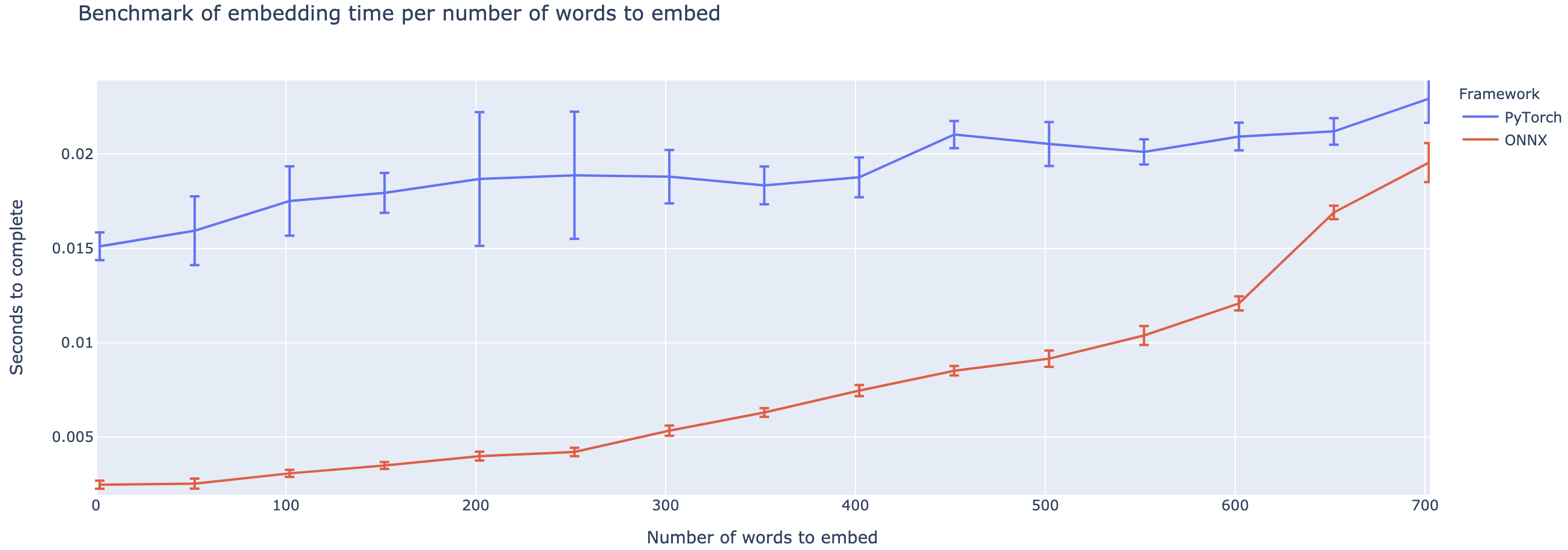
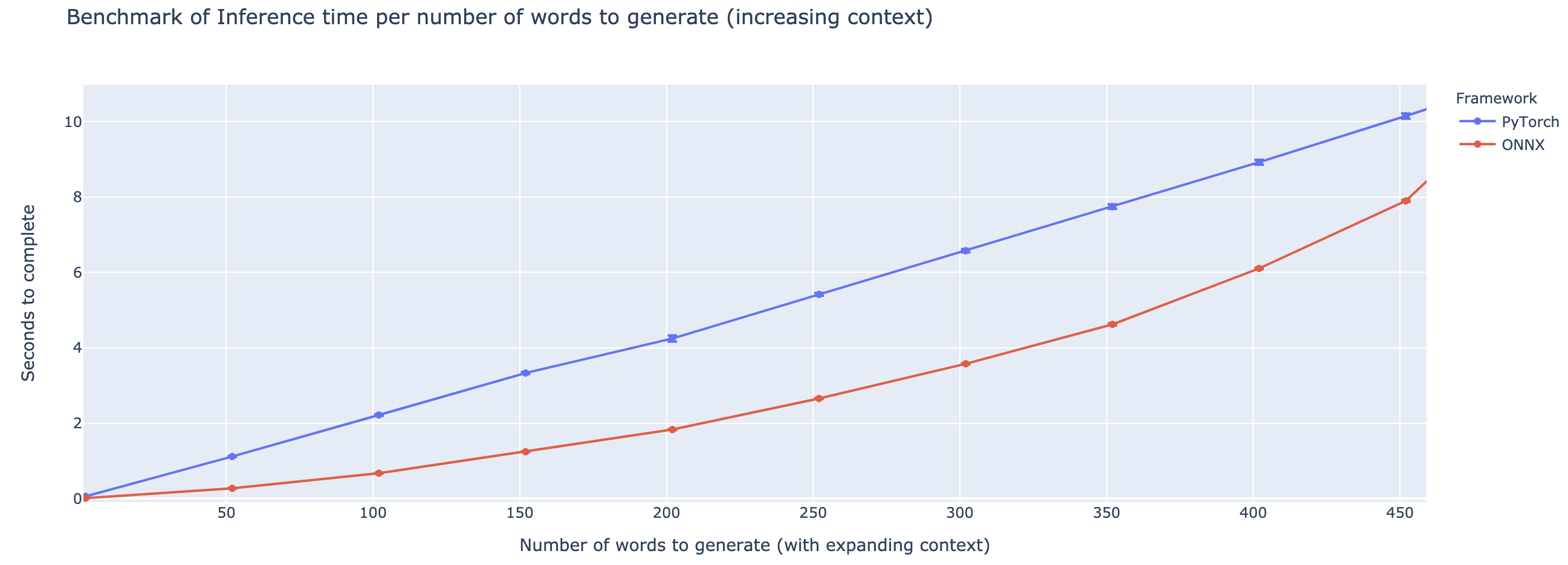
O projeto ainda está em sua infância, então eu adoraria seu feedback, para saber quais problemas você está tentando resolver, ouvir problemas que está encontrando e discutir recursos que o ajudariam. Portanto, fique à vontade para me enviar um e-mail (veja meu perfil para o endereço!) Ou junte-se à nossa comunidade Slack.
Este repositório é baseado no trabalho de Colin Raffel e Noam Orheador e Adam Roberts e Katherine Lee e Sharan Narang e Michael Matena e Yanqi Zhou e Wei Li e Peter J. Liu, do Google, e da implementação do T5 da equipe de Hugging, a equipe de Microsoft Onnx e o OnNxrimes de texto.
Papel T5 original
@article{2019t5,
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
journal = {arXiv e-prints},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.10683},
}
Microsoft OnnxRuntime Repo
Implementação de Huggingface de T5


