onnxt5
ve model
Zusammenfassung, Übersetzung, Fragen und Antworten, Textgenerierung und mehr mit Blazing -Geschwindigkeit unter Verwendung einer T5 -Version, die in ONNX implementiert ist.
Dieses Paket befindet sich noch in der Alpha -Stufe, daher sind einige Funktionen wie Strahlsuche noch in der Entwicklung.
ONNX-T5 ist auf PYPI erhältlich.
pip install onnxt5Für die Dev -Version können Sie Folgendes ausführen.
git clone https://github.com/abelriboulot/onnxt5
cd onnxt5
pip install -e . Der einfachste Weg, um die Generation zu erzeugen, besteht darin, die im Paket enthaltene Standardversion von T5 auf ONNX zu verwenden.
HINWEIS: Bitte beachten Sie, dass Sie beim ersten Mal get_encoder_decoder_tokenizer abgeladen werden, die möglicherweise ein oder zwei Minuten dauern.
from onnxt5 import GenerativeT5
from onnxt5 . api import get_encoder_decoder_tokenizer
decoder_sess , encoder_sess , tokenizer = get_encoder_decoder_tokenizer ()
generative_t5 = GenerativeT5 ( encoder_sess , decoder_sess , tokenizer , onnx = True )
prompt = 'translate English to French: I was a victim of a series of accidents.'
output_text , output_logits = generative_t5 ( prompt , max_length = 100 , temperature = 0. )
# output_text: "J'ai été victime d'une série d'accidents."Andere Aufgaben müssen nur das Präfix in Ihrer Eingabeaufforderung ändern, beispielsweise für die Zusammenfassung:
prompt = 'summarize: <PARAGRAPH>'
output_text , output_logits = generative_t5 ( prompt , max_length = 100 , temperature = 0. )Wenn Sie die Einbettungen des Textes erhalten möchten, können Sie Folgendes ausführen
from onnxt5 . api import get_encoder_decoder_tokenizer , run_embeddings_text
decoder_sess , encoder_sess , tokenizer = get_encoder_decoder_tokenizer ()
prompt = 'Listen, Billy Pilgrim has come unstuck in time.'
encoder_embeddings , decoder_embeddings = run_embeddings_text ( encoder_sess , decoder_sess , tokenizer , prompt ) Mit OnNXT5 können Sie auch Ihre eigenen Modelle exportieren und verwenden. Weitere detailliertere Beispiele finden Sie im Ordner examples .
T5 arbeitet mit Token wie summarize: translate English to German: oder question: ... context: . Sie können eine Liste der vorbereiteten Aufgaben und Token im Anhang D des Originalpapiers sehen.
Die Outperformance variiert stark von der Länge des Kontextes. Für Kontexte weniger als ~ 500 Wörter übertrifft Onnx stark und steigt im Vergleich zu Pytorch auf eine 4 -fache beschleunigte. Je länger der Kontext ist, desto kleiner ist die Beschleunigung von ONNX, wobei Pytorch schneller über 500 Wörtern ist.
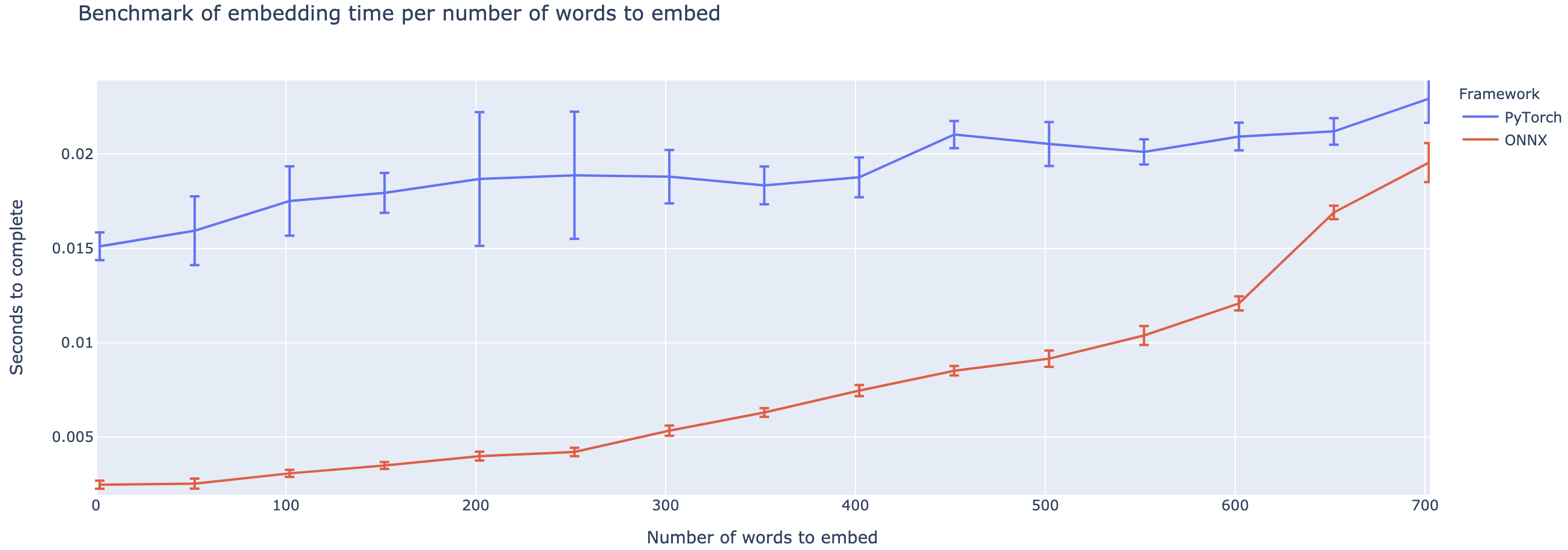
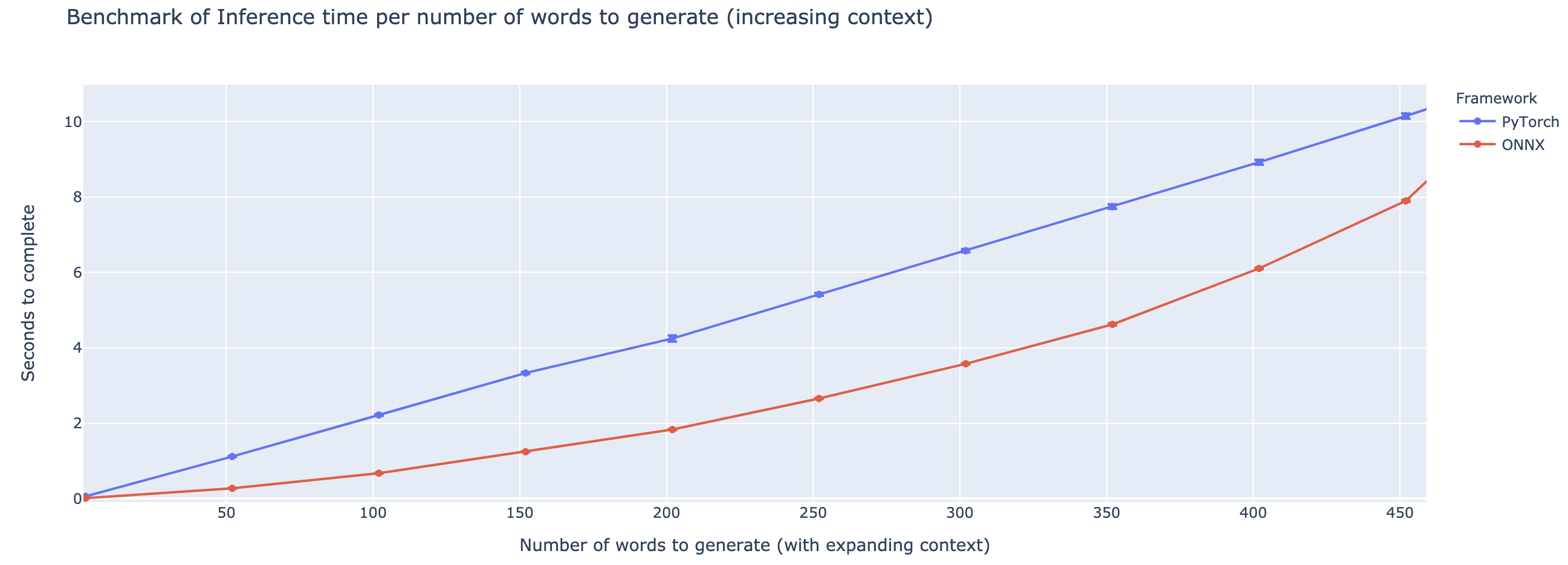
Das Projekt steckt noch in den Kinderschuhen, daher würde ich Ihr Feedback lieben, zu wissen, welche Probleme Sie lösen möchten, Probleme hören, die Sie begegnen, und Funktionen zu besprechen, die Ihnen helfen würden. Daher fühle ich mir gerne eine E-Mail (siehe mein Profil für die Adresse!) Oder treten Sie unserer Slack-Community bei.
This repo is based on the work of Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu from Google, as well as the implementation of T5 from the huggingface team, the work of the Microsoft ONNX and onnxruntime teams, in particular Tianlei Wu, and the work of Thomas Wolf on generation of Text.
Originales T5 -Papier
@article{2019t5,
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
journal = {arXiv e-prints},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.10683},
}
Microsoft OnnxRuntime Repo
Umarmung der Implementierung von T5


