onnxt5
ve model
Ringkasan, terjemahan, T&J, pembuatan teks dan lebih banyak lagi dengan kecepatan Blazing menggunakan versi T5 yang diimplementasikan dalam ONNX.
Paket ini masih dalam tahap alfa, oleh karena itu beberapa fungsi seperti pencarian balok masih dalam pengembangan.
ONNX-T5 tersedia di PYPI.
pip install onnxt5Untuk versi dev Anda dapat menjalankan yang berikut.
git clone https://github.com/abelriboulot/onnxt5
cd onnxt5
pip install -e . Cara paling sederhana untuk memulai pembuatan adalah dengan menggunakan versi pra-terlatih default dari T5 pada ONNX yang termasuk dalam paket.
Catatan: Harap dicatat bahwa pertama kali Anda menelepon get_encoder_decoder_tokenizer, model sedang diunduh yang mungkin memakan waktu satu atau dua menit.
from onnxt5 import GenerativeT5
from onnxt5 . api import get_encoder_decoder_tokenizer
decoder_sess , encoder_sess , tokenizer = get_encoder_decoder_tokenizer ()
generative_t5 = GenerativeT5 ( encoder_sess , decoder_sess , tokenizer , onnx = True )
prompt = 'translate English to French: I was a victim of a series of accidents.'
output_text , output_logits = generative_t5 ( prompt , max_length = 100 , temperature = 0. )
# output_text: "J'ai été victime d'une série d'accidents."Tugas lain hanya perlu mengubah awalan di prompt Anda, misalnya untuk meringkas:
prompt = 'summarize: <PARAGRAPH>'
output_text , output_logits = generative_t5 ( prompt , max_length = 100 , temperature = 0. )Jika Anda ingin mendapatkan embeddings teks, Anda dapat menjalankan yang berikut
from onnxt5 . api import get_encoder_decoder_tokenizer , run_embeddings_text
decoder_sess , encoder_sess , tokenizer = get_encoder_decoder_tokenizer ()
prompt = 'Listen, Billy Pilgrim has come unstuck in time.'
encoder_embeddings , decoder_embeddings = run_embeddings_text ( encoder_sess , decoder_sess , tokenizer , prompt ) Onnxt5 juga memungkinkan Anda mengekspor dan menggunakan model Anda sendiri. Lihat examples folder untuk contoh yang lebih rinci.
T5 bekerja dengan token seperti summarize: , translate English to German: atau question: ... context: . Anda dapat melihat daftar tugas dan token pretrained di Lampiran D dari kertas asli.
Kinerja yang lebih besar bervariasi berdasarkan panjang konteksnya. Untuk konteks yang kurang dari ~ 500 kata, OnNX sangat mengungguli, naik ke speedup 4X dibandingkan dengan Pytorch. Namun, semakin lama konteksnya, semakin kecil speedup ONNX, dengan Pytorch lebih cepat di atas 500 kata.
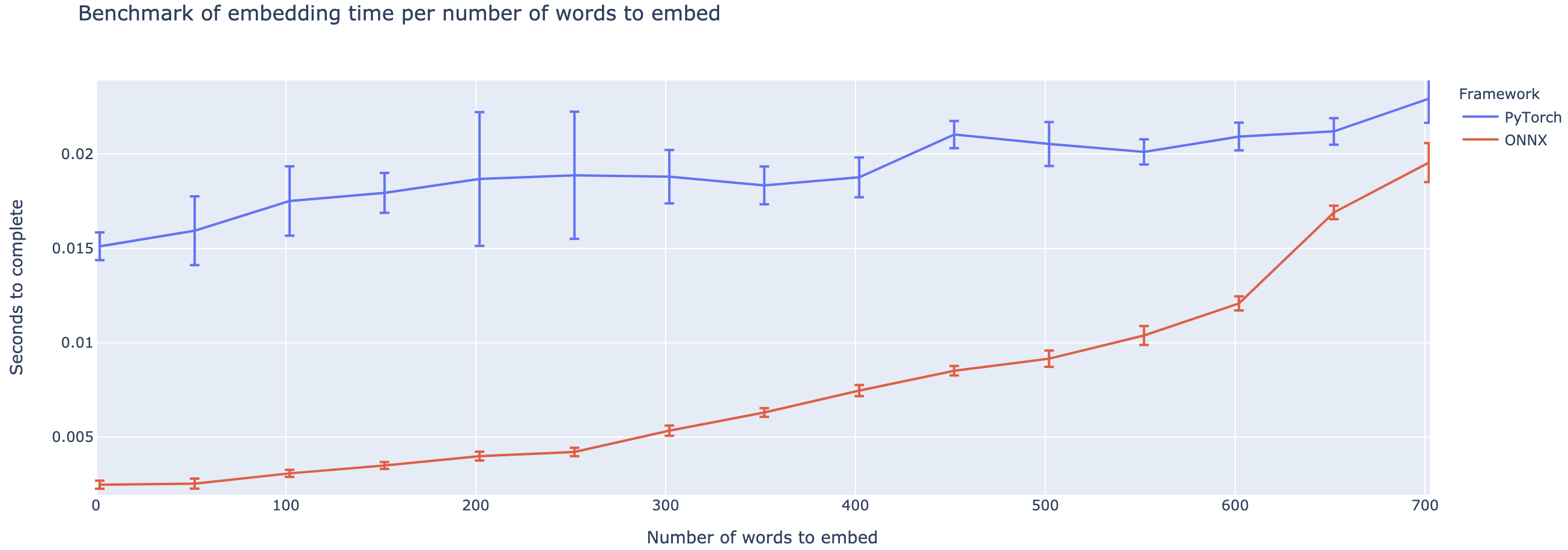
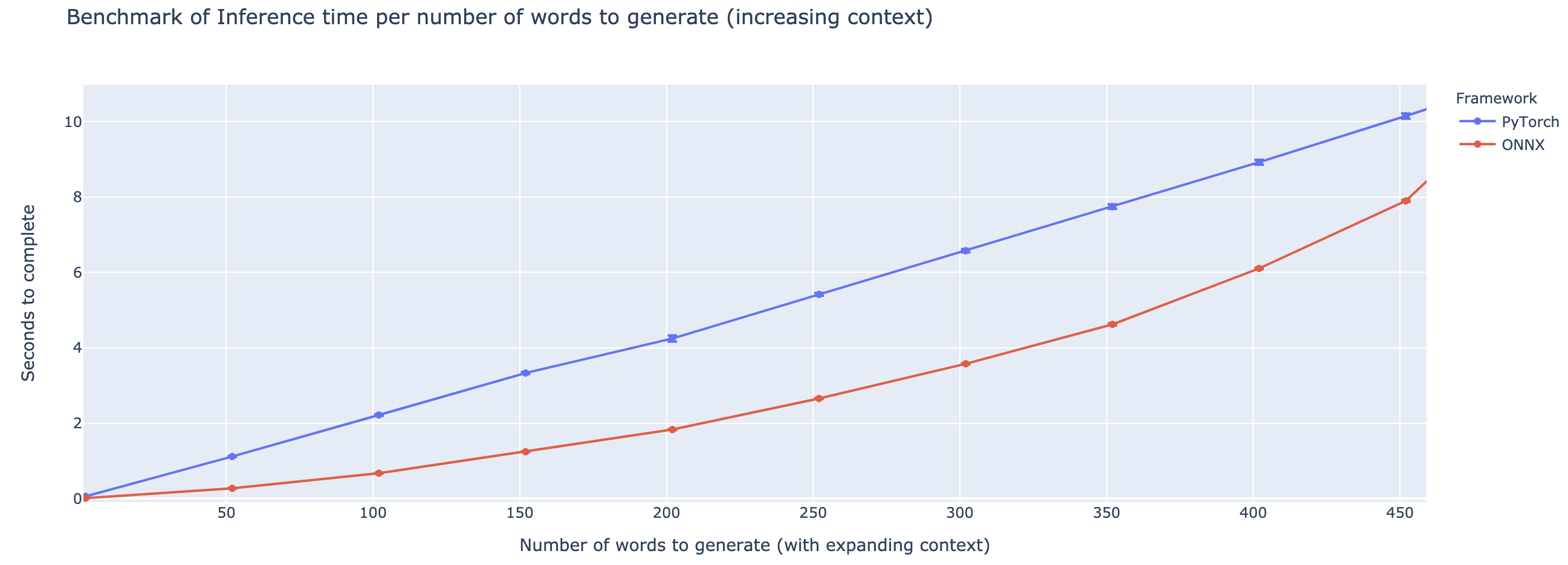
Proyek ini masih dalam masa pertumbuhan, jadi saya akan menyukai umpan balik Anda, untuk mengetahui masalah apa yang Anda coba selesaikan, dengarkan masalah yang Anda hadapi, dan mendiskusikan fitur yang akan membantu Anda. Oleh karena itu jangan ragu untuk menembak saya email (lihat profil saya untuk alamatnya!) Atau bergabunglah dengan komunitas Slack kami.
This repo is based on the work of Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu from Google, as well as the implementation of T5 from the huggingface team, the work of the Microsoft ONNX and onnxruntime teams, in particular Tianlei Wu, and the work of Thomas Wolf on generation of teks.
Kertas T5 asli
@article{2019t5,
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
journal = {arXiv e-prints},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.10683},
}
Repo Microsoft Onnxruntime
Implementasi huggingface dari T5


