onnxt5
ve model
Resumen, traducción, preguntas y respuestas, generación de texto y más a velocidad de aroma utilizando una versión T5 implementada en ONNX.
Este paquete todavía está en la etapa alfa, por lo tanto, algunas funcionalidades, como las búsquedas de haz, todavía están en desarrollo.
ONNX-T5 está disponible en PYPI.
pip install onnxt5Para la versión de desarrollo puede ejecutar lo siguiente.
git clone https://github.com/abelriboulot/onnxt5
cd onnxt5
pip install -e . La forma más sencilla de comenzar para la generación es usar la versión predeterminada de T5 en T5 en ONNX incluida en el paquete.
Nota: Tenga en cuenta que la primera vez que llame a get_encoder_decoder_tokenizer, se están descargando los modelos que pueden tomar uno o dos minutos.
from onnxt5 import GenerativeT5
from onnxt5 . api import get_encoder_decoder_tokenizer
decoder_sess , encoder_sess , tokenizer = get_encoder_decoder_tokenizer ()
generative_t5 = GenerativeT5 ( encoder_sess , decoder_sess , tokenizer , onnx = True )
prompt = 'translate English to French: I was a victim of a series of accidents.'
output_text , output_logits = generative_t5 ( prompt , max_length = 100 , temperature = 0. )
# output_text: "J'ai été victime d'une série d'accidents."Otras tareas solo requieren cambiar el prefijo en su mensaje, por ejemplo, para resumir:
prompt = 'summarize: <PARAGRAPH>'
output_text , output_logits = generative_t5 ( prompt , max_length = 100 , temperature = 0. )Si desea obtener las incrustaciones de texto, puede ejecutar lo siguiente
from onnxt5 . api import get_encoder_decoder_tokenizer , run_embeddings_text
decoder_sess , encoder_sess , tokenizer = get_encoder_decoder_tokenizer ()
prompt = 'Listen, Billy Pilgrim has come unstuck in time.'
encoder_embeddings , decoder_embeddings = run_embeddings_text ( encoder_sess , decoder_sess , tokenizer , prompt ) ONNXT5 también le permite exportar y usar sus propios modelos. Consulte la carpeta examples para ver ejemplos más detallados.
T5 funciona con tokens como summarize: translate English to German: o question: ... context: . Puede ver una lista de las tareas y tokens previos al detenido en el Apéndice D del documento original.
El rendimiento superior varía en gran medida en función de la longitud del contexto. Para contextos de menos de ~ 500 palabras, ONNX supera enormemente, subiendo a una aceleración 4x en comparación con Pytorch. Sin embargo, cuanto más tiempo sea el contexto, más pequeña es la aceleración de ONNX, con Pytorch siendo más rápido por encima de 500 palabras.
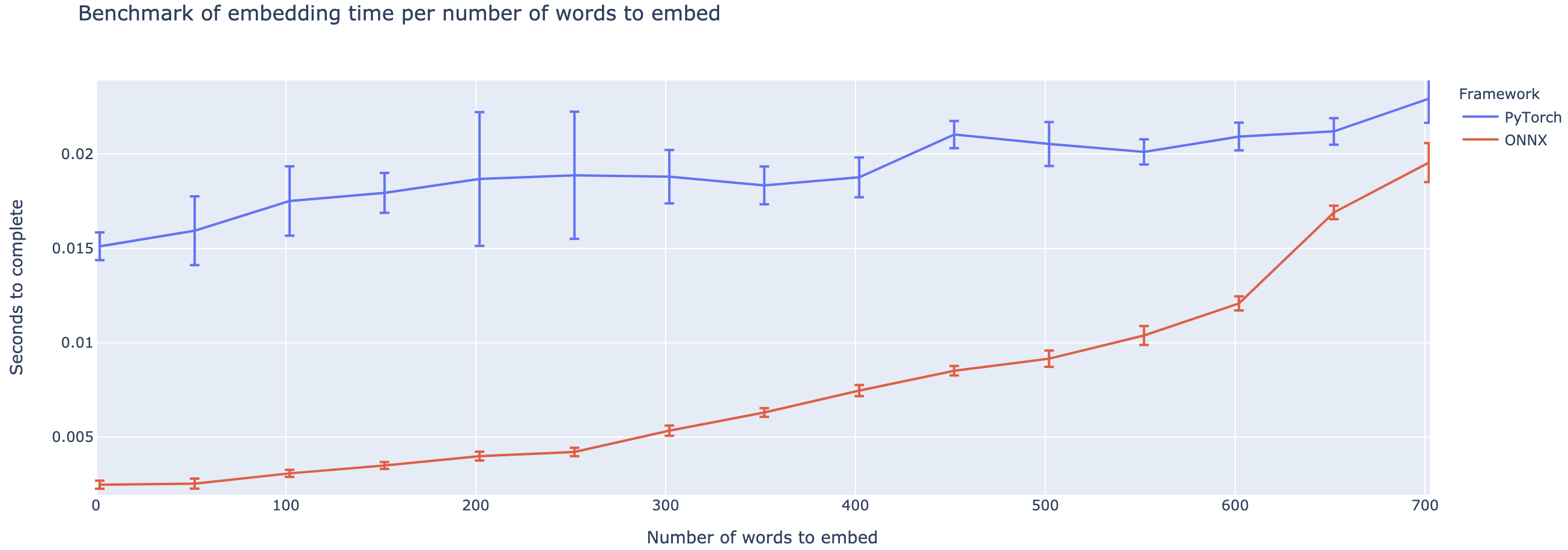
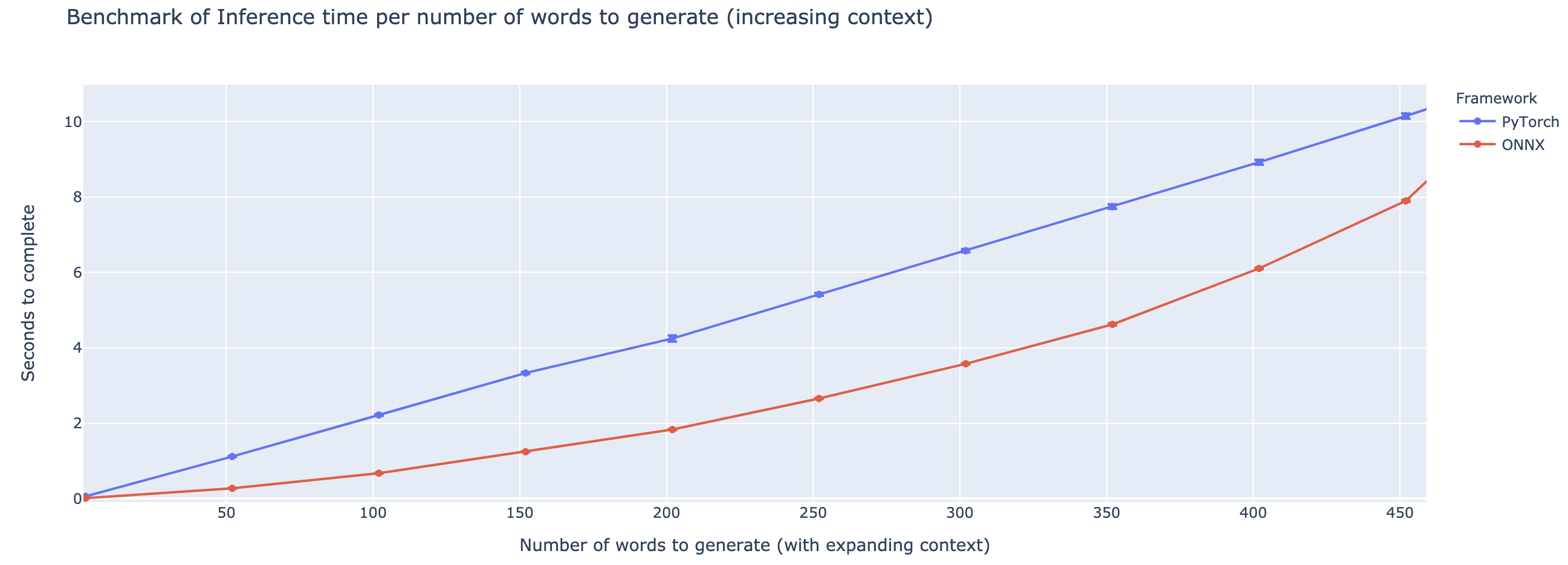
El proyecto todavía está en su infancia, por lo que me encantaría sus comentarios, para saber qué problemas está tratando de resolver, escuchar problemas que está encontrando y discutir características que lo ayudarían. Por lo tanto, no dude en enviarme un correo electrónico (¡vea mi perfil para la dirección!) O únase a nuestra comunidad Slack.
Este repositorio se basa en el trabajo de Colin Raffel y Noam Shazeer y Adam Roberts y Katherine Lee y Sharan Narang y Michael Matena y Yanqi Zhou y Wei Li y Peter J. Liu de Google, así como la implementación de T5 del equipo de Huggingface, el trabajo del Microsoft Onnx y Onnxruntime Teams, en particular texto.
Papel T5 original
@article{2019t5,
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
journal = {arXiv e-prints},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.10683},
}
Repo de Microsoft Onnxruntime
Implementación de Huggingface de T5


