onnxt5
ve model
Résumé, traduction, questions-réponses, génération de texte et plus à une vitesse flamboyante à l'aide d'une version T5 implémentée dans ONNX.
Cet ensemble est toujours au stade alpha, donc certaines fonctionnalités telles que les recherches de faisceaux sont toujours en développement.
ONNX-T5 est disponible sur PYPI.
pip install onnxt5Pour la version Dev, vous pouvez exécuter ce qui suit.
git clone https://github.com/abelriboulot/onnxt5
cd onnxt5
pip install -e . Le moyen le plus simple de commencer pour la génération est d'utiliser la version pré-formée par défaut de T5 sur ONNX incluse dans le package.
Remarque: veuillez noter que la première fois que vous appelez get_encoder_decoder_tokenizer, les modèles sont téléchargés qui pourraient prendre une minute ou deux.
from onnxt5 import GenerativeT5
from onnxt5 . api import get_encoder_decoder_tokenizer
decoder_sess , encoder_sess , tokenizer = get_encoder_decoder_tokenizer ()
generative_t5 = GenerativeT5 ( encoder_sess , decoder_sess , tokenizer , onnx = True )
prompt = 'translate English to French: I was a victim of a series of accidents.'
output_text , output_logits = generative_t5 ( prompt , max_length = 100 , temperature = 0. )
# output_text: "J'ai été victime d'une série d'accidents."D'autres tâches nécessitent simplement de modifier le préfixe dans votre invite, par exemple pour le résumé:
prompt = 'summarize: <PARAGRAPH>'
output_text , output_logits = generative_t5 ( prompt , max_length = 100 , temperature = 0. )Si vous souhaitez obtenir les intégres de texte, vous pouvez exécuter ce qui suit
from onnxt5 . api import get_encoder_decoder_tokenizer , run_embeddings_text
decoder_sess , encoder_sess , tokenizer = get_encoder_decoder_tokenizer ()
prompt = 'Listen, Billy Pilgrim has come unstuck in time.'
encoder_embeddings , decoder_embeddings = run_embeddings_text ( encoder_sess , decoder_sess , tokenizer , prompt ) ONNXT5 vous permet également d'exporter et d'utiliser vos propres modèles. Voir le dossier examples pour des exemples plus détaillés.
T5 travaille avec des jetons tels que summarize: , translate English to German: ou question: ... context: . Vous pouvez voir une liste des tâches et des jetons pré-entraînés à l'annexe D du papier d'origine.
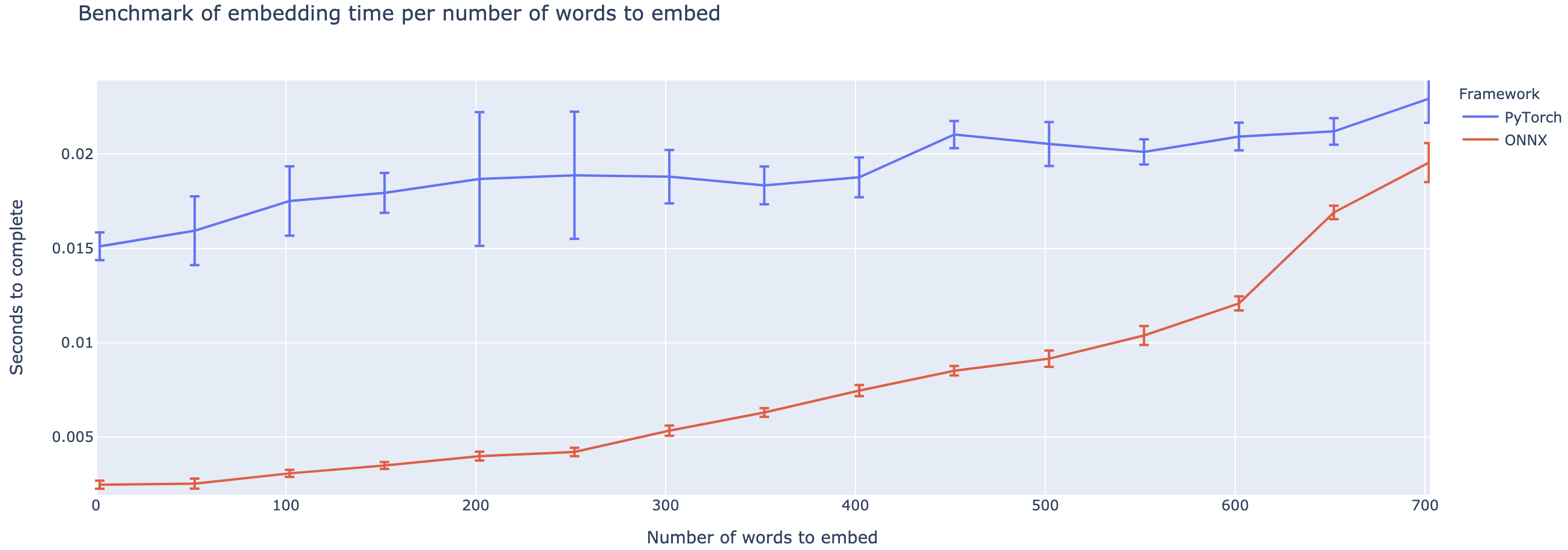
La surperformance varie fortement en fonction de la longueur du contexte. Pour les contextes inférieurs à ~ 500 mots, ONNX surpasse grandement, atteignant une accélération 4X par rapport à Pytorch. Cependant, plus le contexte est long, plus la vitesse de l'ONNX est petite, Pytorch étant plus rapide au-dessus de 500 mots.
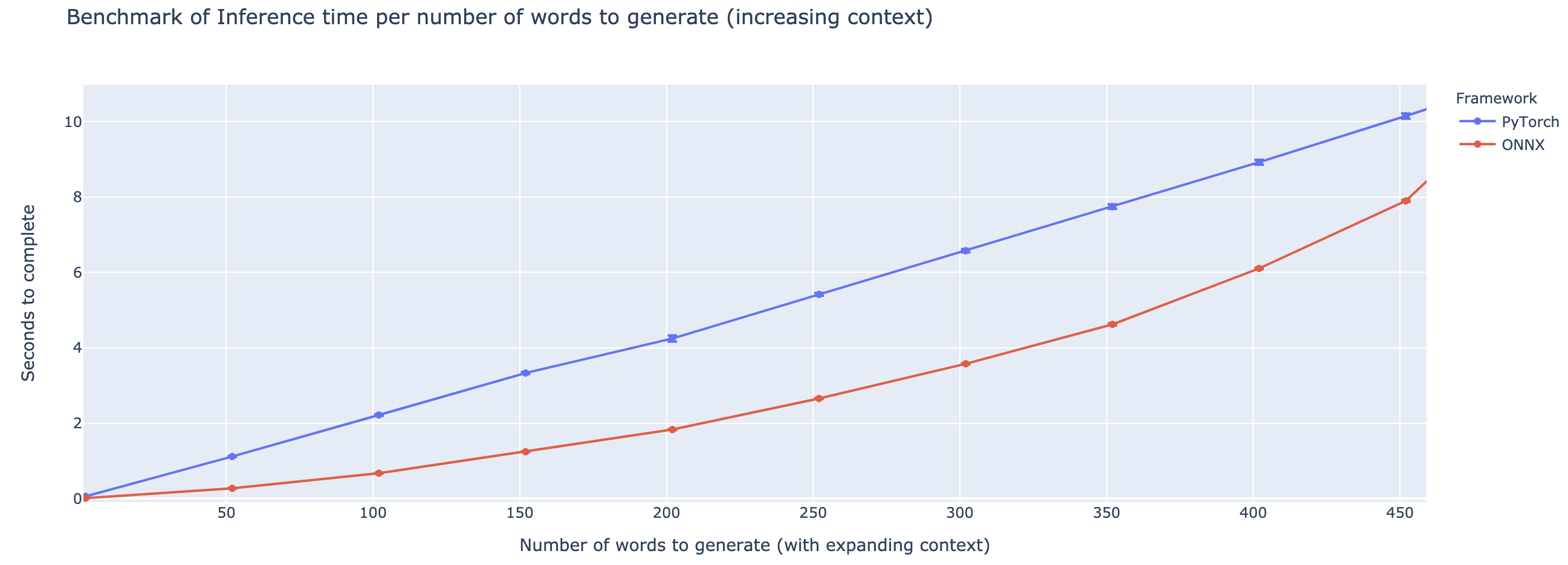
Le projet en est encore à ses balbutiements, donc j'aimerais vos commentaires, pour savoir quels problèmes vous essayez de résoudre, entendre les problèmes que vous rencontrez et discuter des fonctionnalités qui vous aideraient. N'hésitez donc pas à me tirer un e-mail (voir mon profil pour l'adresse!) Ou rejoignez notre communauté Slack.
Ce dépôt est basé sur les travaux de Colin Raffel et Noam Shazeer et Adam Roberts et Katherine Lee et Sharan Narang et Michael Matena et Yanqi Zhou et Wei Li et Peter J. Liu de Google, ainsi que de la mise en œuvre de T5 de l'équipe étreinte, du travail de Microsoft Onnx et ONNXRUNTIM du texte.
Papier T5 d'origine
@article{2019t5,
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
journal = {arXiv e-prints},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.10683},
}
Microsoft onnxruntime Repo
Implémentation de HuggingFace de T5


