Transformers4Rec
v23.12.00
Transformers4Rec-это гибкая и эффективная библиотека для последовательной и сеансовой рекомендации и может работать с Pytorch.
Библиотека работает как мост между обработкой естественного языка (NLP) и рекомендательными системами (Recsys), интегрируясь с одной из самых популярных фреймворков NLP, обнимающих трансформаторы лица (HF). Transformers4rec делает современные архитектуры трансформатора доступными для исследователей Recsys и практикующих отраслевых.
На следующем рисунке показано использование библиотеки в системе рекомендации. Входные данные, как правило, представляют собой последовательность взаимодействий, таких как элементы, которые просмотрены в веб -сеансе или элементах, помещенных в корзину. Библиотека помогает вам обрабатывать и моделировать взаимодействия, чтобы вы могли выводить более высокие рекомендации для следующего элемента.
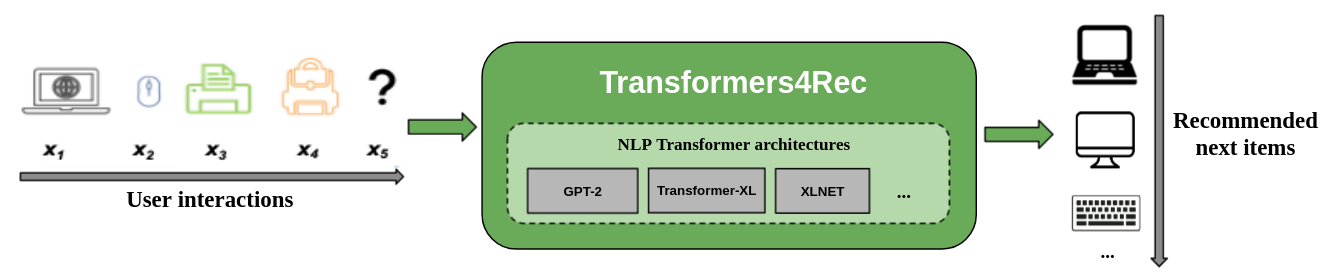
Традиционные алгоритмы рекомендаций обычно игнорируют временную динамику и последовательность взаимодействий при попытке моделировать поведение пользователя. Как правило, следующее взаимодействие с пользователем связано с последовательности предыдущих вариантов пользователя. В некоторых случаях это может быть повторная игра на покупке или песню. Интересы пользователей также могут страдать от дрейфа процентов, поскольку предпочтения могут со временем меняться. Эти проблемы решаются с помощью задачи последовательной рекомендации .
Специальным использованием случая последовательной рекорджина является задача рекомендации на основе сеанса, в которой у вас есть доступ только к короткой последовательности взаимодействий в текущем сеансе. Это очень часто встречается в онлайн-сервисах, таких как электронная коммерция, новости и медиа-порталы, где пользователь может выбрать анонимно просмотреть из-за соответствия GDPR, что ограничивает сбор файлов cookie или потому что пользователь является новым на сайте. Эта задача также имеет отношение к сценариям, когда интересы пользователей сильно меняются с течением времени в зависимости от контекста или намерения пользователя. В этом случае использование взаимодействий для текущего сеанса является более перспективным, чем старые взаимодействия, чтобы дать соответствующие рекомендации.
Чтобы справиться с последовательными и сеансовыми рекомендациями, многие алгоритмы обучения последовательностях, ранее применяемые в области машинного обучения и исследований НЛП, были изучены для Recsys, основанных на K-ближайших соседях, частых майнингах, скрытых моделях Маркова, повторяющихся нейронных сетях и в последнее время нейронных архитектур с использованием механизма самостоятельного соблюдения и архитектуры трансформаторов. В отличие от Transformers4Rec, эти рамки принимают только последовательности идентификаторов элементов в качестве входных и не обеспечивают модульной, масштабируемой реализации для использования производства.
Transformers4rec предлагает следующие преимущества:
Гибкость : Transformers4Rec предоставляет модульные строительные блоки, которые настраиваются и совместимы со стандартными модулями Pytorch. Этот дизайн блока здания позволяет создавать пользовательские архитектуры с несколькими башнями, несколькими головками/задачами и потерями.
Доступ к трансформаторам HF : более 64 различных архитектур трансформаторов могут использоваться для оценки вашей задачи рекомендаций на основе последовательных и сеансов в результате интеграции Transformers Transformers.
Поддержка нескольких входных функций : HF -трансформаторы поддерживают только последовательности токенов идентификаторов токенов в качестве входных данных, потому что он был первоначально разработан для NLP. Transformers4Rec позволяет использовать другие типы последовательных табличных данных в качестве ввода с трансформаторами HF из -за богатых функций, которые доступны в наборах данных Recsys. Transformers4Rec использует схему для настройки входных функций и автоматически создает необходимые слои, такие как встроенные таблицы, проекционные слои и выходные слои на основе цели, не требуя изменений кода, чтобы включить новые функции. Вы можете нормализовать и комбинировать функции ввода взаимодействия и на уровне последовательности настраиваемыми способами.
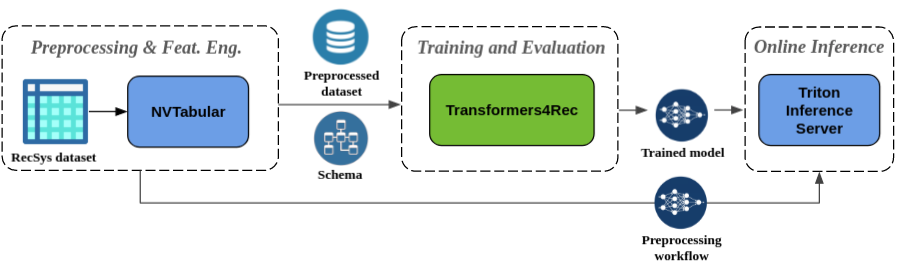
Бесплатная предварительная обработка и инженерия функции : как часть экосистемы Merlin, Transformers4Rec интегрирована с сервером вывода NVTabular и Triton. Эти компоненты позволяют вам создать полностью ускоренный графический процесс трубопровод для последовательной и сеансовой рекомендации. NVTabular имеет общие операции предварительной обработки для рекомендации на основе сеансов и экспортирует схему набора данных. Схема совместима с Transformers4Rec, так что входные функции можно настроить автоматически. Вы можете экспортировать свои обученные модели для обслуживания с сервером вывода Triton в одном трубопроводе, который включает в себя предварительную обработку функций и вывод модели. Для получения дополнительной информации обратитесь к сквозному трубопроводу с Nvidia Merlin.
Transformers4Rec недавно выиграл два сессионных рекомендационных соревнования: WSDM Webtour Workshop Challenge 2021 (организованный Booking.com) и Sigir Ecommerce Workshop Data Challenge 2021 (организованный Coveo). Библиотека обеспечивает более высокую точность для рекомендации на основе сеансов, чем базовые алгоритмы, и мы провели обширный эмпирический анализ о точности. Эти наблюдения опубликованы в нашей статье ACM Recsys'21.
Обучение модели с Transformers4Rec обычно требует выполнения следующих шагов высокого уровня:
Обеспечить схему и построить входной модуль.
Если вы сталкиваетесь с проблемами рекомендаций, основанных на сеансе, вы обычно хотите использовать класс Tabular SextenceFeatures, потому что он объединяет функции контекста с последовательными функциями.
Обеспечить задачи прогноза.
Задачи, которые предоставляются прямо из коробки, доступны в нашей документации API.
Создайте трансформаторное тело и преобразуйте это в модель.
Следующий образец кода показывает, как определить и обучить модель XLnet с помощью Pytorch для задачи прогнозирования следующего пункта:
from transformers4rec import torch as tr
from transformers4rec . torch . ranking_metric import NDCGAt , RecallAt
# Create a schema or read one from disk: tr.Schema().from_json(SCHEMA_PATH).
schema : tr . Schema = tr . data . tabular_sequence_testing_data . schema
max_sequence_length , d_model = 20 , 64
# Define the input module to process the tabular input features.
input_module = tr . TabularSequenceFeatures . from_schema (
schema ,
max_sequence_length = max_sequence_length ,
continuous_projection = d_model ,
aggregation = "concat" ,
masking = "causal" ,
)
# Define a transformer-config like the XLNet architecture.
transformer_config = tr . XLNetConfig . build (
d_model = d_model , n_head = 4 , n_layer = 2 , total_seq_length = max_sequence_length
)
# Define the model block including: inputs, masking, projection and transformer block.
body = tr . SequentialBlock (
input_module ,
tr . MLPBlock ([ d_model ]),
tr . TransformerBlock ( transformer_config , masking = input_module . masking )
)
# Define the evaluation top-N metrics and the cut-offs
metrics = [ NDCGAt ( top_ks = [ 20 , 40 ], labels_onehot = True ),
RecallAt ( top_ks = [ 20 , 40 ], labels_onehot = True )]
# Define a head with NextItemPredictionTask.
head = tr . Head (
body ,
tr . NextItemPredictionTask ( weight_tying = True , metrics = metrics ),
inputs = input_module ,
)
# Get the end-to-end Model class.
model = tr . Model ( head )Вы можете изменить предыдущий код для выполнения бинарной классификации. Маскировка в входном модуле может быть установлена ни на
Noneвместоcausal. Когда вы определяете головку, вы можете заменитьNextItemPredictionTaskна экземплярBinaryClassificationTask. См. Пример кода в документации API для класса.
Вы можете установить Transformers4rec с PIP, Conda или запустить контейнер Docker.
Вы можете установить Transformers4Rec с функциональностью для использования ускоренного GPU Merlin DataLoader. Установка с DataLoader настоятельно рекомендуется для повышения производительности. Эти компоненты могут быть установлены в качестве дополнительных аргументов для команды pip install .
Для установки Transformers4rec с помощью PIP запустите следующую команду:
pip install transformers4rec[nvtabular] -> Имейте в виду, что установка Transformers4Rec с pip не устанавливает RAPIDS CUDF. -> CUDF требуется для ускоренных графических данных версий преобразований NVTABULAR и Merlin DataLoader.
Инструкции по установке CUDF с PIP доступны здесь: https://docs.rapids.ai/install#pip-install
pip install cudf-cu11 dask-cudf-cu11 --extra-index-url=https://pypi.nvidia.com Чтобы установить Transformers4rec, используя Conda, запустите следующую команду с conda или mamba , чтобы создать новую среду.
mamba create -n transformers4rec-23.04 -c nvidia -c rapidsai -c pytorch -c conda-forge
transformers4rec=23.04 ` # NVIDIA Merlin `
nvtabular=23.04 ` # NVIDIA Merlin - Used in example notebooks `
python=3.10 ` # Compatible Python environment `
cudf=23.02 ` # RAPIDS cuDF - GPU accelerated DataFrame `
cudatoolkit=11.8 pytorch-cuda=11.8 ` # NVIDIA CUDA version ` Transformers4Rec предварительно установлен в контейнере merlin-pytorch , который доступен в каталоге Nvidia Cloud (NGC).
Обратитесь к странице документации Merlin Containers для получения информации об именах контейнеров Merlin, URL -адресах для изображений контейнеров в каталоге и ключевых компонентах Merlin.
Скромный трубопровод на странице Nvidia Merlin показывает, как использовать Transformers4Rec и другие библиотеки Merlin, такие как NVTabular для создания полной системы рекомендаций.
У нас есть несколько примеров ноутбуков, которые помогут вам создать систему рекомендаций или интегрировать Transformers4Rec в вашу систему:
Если вы хотите внести прямой вклад в Transformers4rec, обратитесь к участию в Transformers4Rec. Мы особенно заинтересованы в взносах или запросах функций для наших функций по проектированию и предварительной обработке. Чтобы продвинуть нашу дорожную карту Merlin, мы рекомендуем вам поделиться всеми подробностями, касающимися вашего конвейера системы рекомендации, отправившись на https://developer.nvidia.com/merlin-devzone-survey.
Если вы заинтересованы в том, чтобы узнать больше о том, как работает Transformers4Rec, обратитесь к нашей документации Transformers4rec. У нас также есть документация по API, в которой описывается особенности доступных модулей и классов в рамках Transformers4Rec.


