Transformers4Rec
v23.12.00
Transformers4Rec es una biblioteca flexible y eficiente para recomendaciones secuenciales y basadas en sesiones y puede funcionar con Pytorch.
La biblioteca funciona como un puente entre el procesamiento del lenguaje natural (PNL) y los sistemas de recomendación (RECSYS) integrándose con uno de los marcos de NLP más populares, abrazando transformadores faciales (HF). Transformers4REC pone a disposición arquitecturas de transformadores de vanguardia para investigadores y profesionales de la industria de RECSY.
La siguiente figura muestra el uso de la biblioteca en un sistema de recomendación. Los datos de entrada suelen ser una secuencia de interacciones, como elementos que se navegan en una sesión web o elementos que se colocan en un carrito. La biblioteca lo ayuda a procesar y modelar las interacciones para que pueda obtener mejores recomendaciones para el siguiente elemento.
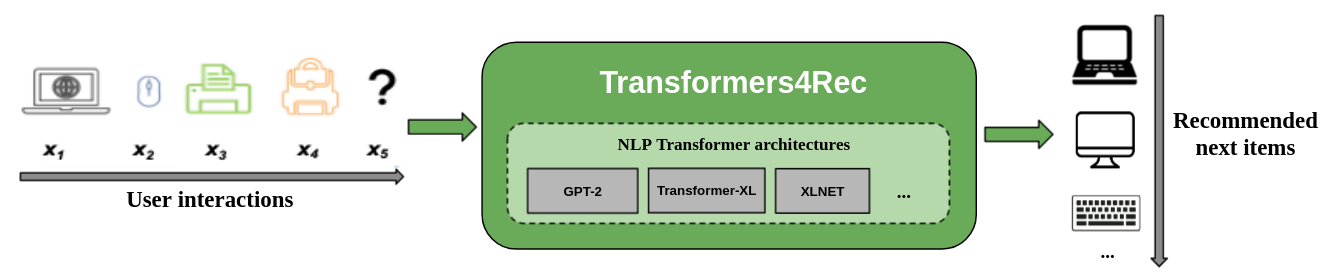
Los algoritmos de recomendación tradicionales generalmente ignoran la dinámica temporal y la secuencia de interacciones al tratar de modelar el comportamiento del usuario. En general, la próxima interacción del usuario está relacionada con la secuencia de las opciones anteriores del usuario. En algunos casos, podría ser una compra repetida o reproducción de canciones. Los intereses de los usuarios también pueden sufrir una deriva de interés porque las preferencias pueden cambiar con el tiempo. Esos desafíos se abordan mediante la tarea de recomendación secuencial .
Un caso de uso especial de recomendación secuencial es la tarea de recomendación basada en la sesión, donde solo tiene acceso a la secuencia corta de interacciones dentro de la sesión actual. Esto es muy común en los servicios en línea como el comercio electrónico, las noticias y los portales de medios donde el usuario puede elegir navegar de forma anónima debido al cumplimiento de GDPR que restringe las cookies o porque el usuario es nuevo en el sitio. Esta tarea también es relevante para escenarios en los que los intereses de los usuarios cambian mucho con el tiempo, según el contexto o la intención del usuario. En este caso, aprovechar las interacciones para la sesión actual es más prometedor que las interacciones antiguas para proporcionar recomendaciones relevantes.
Para hacer frente a la recomendación secuencial y basada en la sesión, se han explorado muchos algoritmos de aprendizaje de secuencias aplicados previamente en el aprendizaje automático y la investigación de PNL para RECSYS basadas en vecinos K-nears, minería de patrones frecuentes, modelos ocultos de Markov, redes neuronales recurrentes y más recientemente arquitecturas neuronales utilizando el mecanismo de autoenitimiento y las arquitecturas transformadoras. A diferencia de Transformers4REC, estos marcos solo aceptan secuencias de ID de elemento como entrada y no proporcionan una implementación modularizada y escalable para el uso de producción.
Transformers4Rec ofrece los siguientes beneficios:
Flexibilidad : Transformers4REC proporciona bloques de construcción modularizados que son configurables y compatibles con los módulos Pytorch estándar. Este diseño de bloques de edificios le permite crear arquitecturas personalizadas con múltiples torres, múltiples cabezas/tareas y pérdidas.
Acceso a los transformadores HF : se pueden utilizar más de 64 arquitecturas de transformadores diferentes para evaluar su tarea de recomendación secuencial y basada en la sesión como resultado de la integración de transformadores de la cara abrazada.
Soporte para múltiples características de entrada : los transformadores HF solo admiten secuencias de ID de token como entrada porque se diseñó originalmente para PNL. Transformers4Rec le permite usar otros tipos de datos tabulares secuenciales como entrada con transformadores de HF debido a las características ricas que están disponibles en los conjuntos de datos RECSYS. Transformers4REC utiliza un esquema para configurar las características de entrada y crea automáticamente las capas necesarias, como las tablas de incrustación, las capas de proyección y las capas de salida en función del objetivo sin requerir cambios en el código para incluir nuevas características. Puede normalizar y combinar las funciones de entrada de interacción y secuencia de manera configurable.
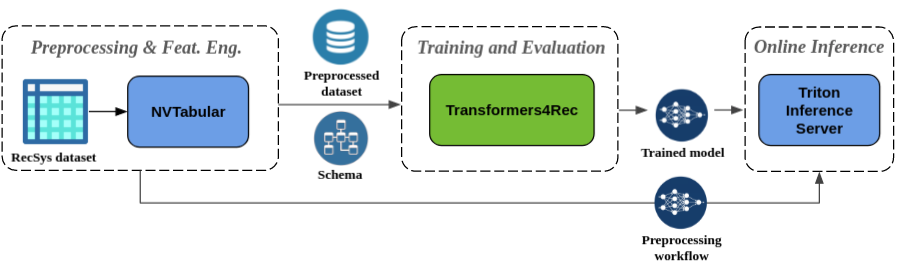
Preprocesamiento sin interrupciones e ingeniería de características : como parte del ecosistema de Merlin, Transformers4REC está integrado con el servidor de inferencia NVTabular y Triton. Estos componentes le permiten construir una tubería totalmente acelerada por GPU para una recomendación secuencial y basada en la sesión. Nvtabular tiene operaciones de preprocesamiento comunes para recomendaciones basadas en sesiones y exporta un esquema de conjunto de datos. El esquema es compatible con Transformers4REC para que las funciones de entrada se puedan configurar automáticamente. Puede exportar sus modelos capacitados para servir con Triton Inference Server en una sola tubería que incluye preprocesamiento de características en línea e inferencia de modelos. Para obtener más información, consulte la tubería de extremo a extremo con Nvidia Merlin.
Transformers4Rec recientemente ganó dos concursos de recomendaciones basados en sesiones: WSDM WebTour Workshop Challenge 2021 (organizado por Booking.com) y Sigir Ecommerce Workshop Data Challenge 2021 (organizado por Coveo). La biblioteca proporciona una mayor precisión para la recomendación basada en la sesión que los algoritmos de línea de base y realizamos un análisis empírico extenso sobre la precisión. Estas observaciones se publican en nuestro artículo ACM Recsys'21.
Entrenar un modelo con Transformers4Rec generalmente requiere realizar los siguientes pasos de alto nivel:
Proporcione el esquema y construya un módulo de entrada.
Si encuentra problemas de recomendación basados en la sesión, generalmente desea utilizar la clase TabularSequenceFeatures porque combina características de contexto con características secuenciales.
Proporcionar las tareas de predicción.
Las tareas que se proporcionan de inmediato están disponibles en nuestra documentación de API.
Construya un cuerpo de transformador y convierta esto en un modelo.
La siguiente muestra de código muestra cómo definir y entrenar un modelo XLNet con Pytorch para la tarea de predicción de próxima ítem:
from transformers4rec import torch as tr
from transformers4rec . torch . ranking_metric import NDCGAt , RecallAt
# Create a schema or read one from disk: tr.Schema().from_json(SCHEMA_PATH).
schema : tr . Schema = tr . data . tabular_sequence_testing_data . schema
max_sequence_length , d_model = 20 , 64
# Define the input module to process the tabular input features.
input_module = tr . TabularSequenceFeatures . from_schema (
schema ,
max_sequence_length = max_sequence_length ,
continuous_projection = d_model ,
aggregation = "concat" ,
masking = "causal" ,
)
# Define a transformer-config like the XLNet architecture.
transformer_config = tr . XLNetConfig . build (
d_model = d_model , n_head = 4 , n_layer = 2 , total_seq_length = max_sequence_length
)
# Define the model block including: inputs, masking, projection and transformer block.
body = tr . SequentialBlock (
input_module ,
tr . MLPBlock ([ d_model ]),
tr . TransformerBlock ( transformer_config , masking = input_module . masking )
)
# Define the evaluation top-N metrics and the cut-offs
metrics = [ NDCGAt ( top_ks = [ 20 , 40 ], labels_onehot = True ),
RecallAt ( top_ks = [ 20 , 40 ], labels_onehot = True )]
# Define a head with NextItemPredictionTask.
head = tr . Head (
body ,
tr . NextItemPredictionTask ( weight_tying = True , metrics = metrics ),
inputs = input_module ,
)
# Get the end-to-end Model class.
model = tr . Model ( head )Puede modificar el código anterior para realizar la clasificación binaria. El enmascaramiento en el módulo de entrada se puede establecer en
Noneen lugar decausal. Cuando defina la cabeza, puede reemplazar elNextItemPredictionTaskcon una instancia deBinaryClassificationTask. Consulte el código de muestra en la documentación de la API para la clase.
Puede instalar Transformers4Rec con PIP, conda o ejecutar un contenedor Docker.
Puede instalar Transformers4REC con la funcionalidad para usar el Merlin DataLoader acelerado por GPU. La instalación con DataLoader es muy recomendable para un mejor rendimiento. Esos componentes se pueden instalar como argumentos opcionales para el comando pip install .
Para instalar Transformers4REC usando PIP, ejecute el siguiente comando:
pip install transformers4rec[nvtabular] -> Tenga en cuenta que la instalación de Transformers4REC con pip no instala automáticamente Rapids CUDF. -> Se requiere CUDF para las versiones aceleradas por GPU de transformaciones NVTabulares y el Merlin DataLoader.
Las instrucciones para instalar CUDF con PIP están disponibles aquí: https://docs.rapids.ai/install#pip-install
pip install cudf-cu11 dask-cudf-cu11 --extra-index-url=https://pypi.nvidia.com Para instalar Transformers4REC usando Conda, ejecute el siguiente comando con conda o mamba para crear un nuevo entorno.
mamba create -n transformers4rec-23.04 -c nvidia -c rapidsai -c pytorch -c conda-forge
transformers4rec=23.04 ` # NVIDIA Merlin `
nvtabular=23.04 ` # NVIDIA Merlin - Used in example notebooks `
python=3.10 ` # Compatible Python environment `
cudf=23.02 ` # RAPIDS cuDF - GPU accelerated DataFrame `
cudatoolkit=11.8 pytorch-cuda=11.8 ` # NVIDIA CUDA version ` Transformers4Rec se preinstalan en el contenedor merlin-pytorch que está disponible en el catálogo NVIDIA GPU Cloud (NGC).
Consulte la página de documentación de Merlin Containers para obtener información sobre los nombres de contenedores de Merlin, las URL a las imágenes de contenedores en el catálogo y los componentes clave de Merlin.
La tubería de extremo a extremo con la página Nvidia Merlin muestra cómo usar Transformers4Rec y otras bibliotecas de Merlin como NVTabular para construir un sistema de recomendación completo.
Tenemos varios cuadernos de ejemplo para ayudarlo a construir un sistema de recomendación o integrar Transformers4Rec en su sistema:
Si desea realizar contribuciones directas a Transformers4REC, consulte que contribuya a Transformers4Rec. Estamos particularmente interesados en contribuciones o solicitudes de funciones para nuestras operaciones de ingeniería y preprocesamiento de características. Para avanzar aún más en nuestra hoja de ruta de Merlin, le recomendamos que comparta todos los detalles sobre su canalización del sistema de recomendación yendo a https://developer.nvidia.com/merlin-devzone-survey.
Si está interesado en aprender más sobre cómo funciona Transformers4REC, consulte nuestra documentación Transformers4Rec. También tenemos documentación de API que describe los detalles de los módulos y clases disponibles dentro de Transformers4Rec.


