Transformers4Rec
v23.12.00
Transformers4Rec est une bibliothèque flexible et efficace pour la recommandation séquentielle et basée sur la session et peut fonctionner avec Pytorch.
La bibliothèque fonctionne comme un pont entre le traitement du langage naturel (NLP) et les systèmes de recommandation (RECSYS) en s'intégrant à l'un des cadres NLP les plus populaires, les transformateurs de visage étreintes (HF). Transformers4rec rend les architectures de transformateurs de pointe disponibles pour les chercheurs de Recsys et les praticiens de l'industrie.
La figure suivante montre l'utilisation de la bibliothèque dans un système de recommandation. Les données d'entrée sont généralement une séquence d'interactions telles que les éléments qui sont parcourus dans une session Web ou des éléments placés dans un panier. La bibliothèque vous aide à traiter et à modéliser les interactions afin de pouvoir publier de meilleures recommandations pour l'élément suivant.
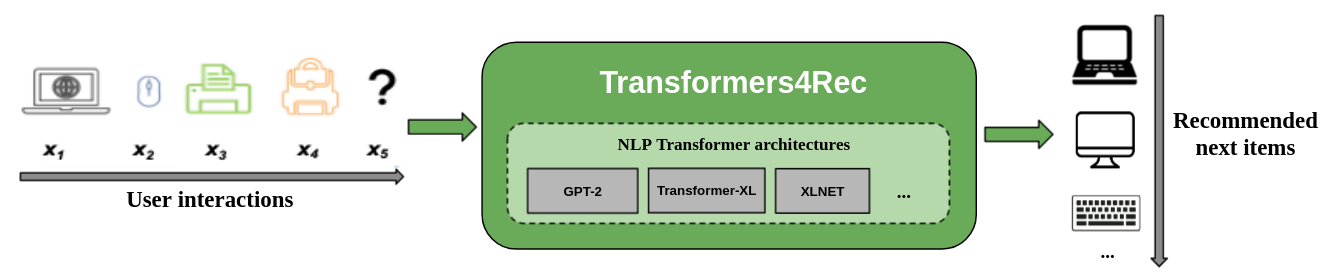
Les algorithmes de recommandation traditionnels ignorent généralement la dynamique temporelle et la séquence des interactions lorsque vous essayez de modéliser le comportement de l'utilisateur. Généralement, la prochaine interaction utilisateur est liée à la séquence des choix précédents de l'utilisateur. Dans certains cas, il pourrait s'agir d'un achat ou d'un jeu de chansons répété. Les intérêts des utilisateurs peuvent également souffrir de dérive d'intérêts car les préférences peuvent changer avec le temps. Ces défis sont relevés par la tâche de recommandation séquentielle .
Un cas d'utilisation spécial de recommandation séquentielle est la tâche de recommandation basée sur la session où vous n'avez accès qu'à la courte séquence d'interactions au sein de la session en cours. Ceci est très courant dans les services en ligne comme le commerce électronique, les actualités et les portails de médias où l'utilisateur peut choisir de parcourir de manière anonyme en raison de la conformité du RGPD qui restreint la collecte de cookies ou parce que l'utilisateur est nouveau sur le site. Cette tâche est également pertinente pour les scénarios où les intérêts des utilisateurs changent beaucoup au fil du temps en fonction du contexte ou de l'intention de l'utilisateur. Dans ce cas, tirer parti des interactions de la session en cours est plus prometteur que les anciennes interactions pour fournir des recommandations pertinentes.
Pour faire face à des recommandations séquentielles et basées sur des sessions, de nombreux algorithmes d'apprentissage de séquences précédemment appliqués dans l'apprentissage automatique et la recherche sur les PNL ont été explorés pour RecSys sur la base des voisins K-Dearest, des modèles de modèles fréquents, des modèles de Markov cachés, des réseaux neuronaux récurrents et plus récemment des architectures neuronales en utilisant le mécanisme d'auto-addition et les architectures de transformateurs. Contrairement à Transformers4REC, ces cadres n'acceptent que les séquences d'IDS d'élément en entrée et ne fournissent pas une implémentation modularisée et évolutive pour l'utilisation de la production.
Transformers4rec offre les avantages suivants:
Flexibilité : Transformers4REC fournit des blocs de construction modularisés configurables et compatibles avec les modules Pytorch standard. Cette conception de blocs de construction vous permet de créer des architectures personnalisées avec plusieurs tours, plusieurs têtes / tâches et pertes.
Accès aux transformateurs HF : plus de 64 architectures de transformateurs différentes peuvent être utilisées pour évaluer votre tâche de recommandation séquentielle et basée sur la session en raison de l'intégration des transformateurs de face étreintes.
Prise en charge de plusieurs fonctionnalités d'entrée : les transformateurs HF ne prennent en charge que les séquences d'ID de jeton en entrée car il a été initialement conçu pour la PNL. Transformers4Rec vous permet d'utiliser d'autres types de données tabulaires séquentielles en entrée avec les transformateurs HF en raison des fonctionnalités riches disponibles dans les ensembles de données RecSys. Transformers4Rec utilise un schéma pour configurer les fonctionnalités d'entrée et crée automatiquement les couches nécessaires, telles que les tables d'intégration, les couches de projection et les couches de sortie en fonction de la cible sans nécessiter de modifications de code pour inclure de nouvelles fonctionnalités. Vous pouvez normaliser et combiner l'interaction et les fonctionnalités d'entrée au niveau de la séquence de manière configurable.
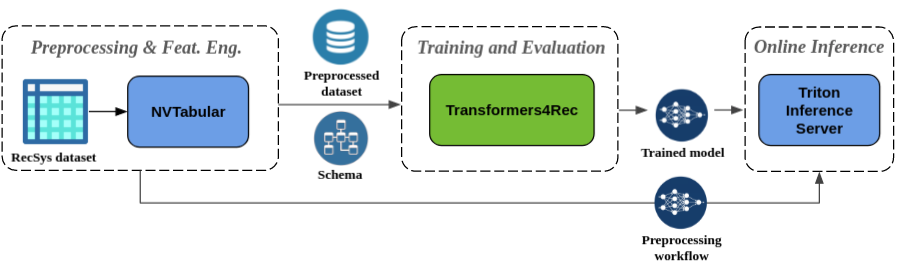
Prétraitement transparent et ingénierie des fonctionnalités : Dans le cadre de l'écosystème Merlin, Transformers4REC est intégré au serveur d'inférence NVTABULAR et TRITON. Ces composants vous permettent de créer un pipeline accéléré entièrement GPU pour une recommandation séquentielle et basée sur des sessions. NVTABULAR possède des opérations de prétraitement communes pour la recommandation basée sur la session et exporte un schéma de jeu de données. Le schéma est compatible avec Transformers4REC afin que les fonctionnalités d'entrée puissent être configurées automatiquement. Vous pouvez exporter vos modèles formés pour servir avec Triton Inference Server en un seul pipeline qui comprend le prétraitement des fonctionnalités en ligne et l'inférence du modèle. Pour plus d'informations, reportez-vous au pipeline de bout en bout avec Nvidia Merlin.
Transformers4Rec a récemment remporté deux compétitions de recommandations basées sur des sessions: WSDM WebTour Workshop Challenge 2021 (organisé par Booking.com) et Sigir Ecommerce Workshop Data Challenge 2021 (organisé par Coveo). La bibliothèque fournit une précision plus élevée pour la recommandation basée sur la session que les algorithmes de base et nous avons effectué une analyse empirique approfondie sur la précision. Ces observations sont publiées dans notre article ACM Recsys'21.
La formation d'un modèle avec Transformers4REC nécessite généralement d'effectuer les étapes de haut niveau suivantes:
Fournissez le schéma et construisez un module d'entrée.
Si vous rencontrez des problèmes de recommandation basés sur la session, vous souhaitez généralement utiliser la classe TabularSenceFeatures car il fusionne les fonctionnalités de contexte avec des fonctionnalités séquentielles.
Fournir les tâches de prédiction.
Les tâches fournies dès la sortie de la boîte sont disponibles à partir de notre documentation API.
Construisez un corps transformateur et convertissez-le en modèle.
L'exemple de code suivant montre comment définir et former un modèle XLNET avec Pytorch pour la tâche de prédiction de l'élément suivant:
from transformers4rec import torch as tr
from transformers4rec . torch . ranking_metric import NDCGAt , RecallAt
# Create a schema or read one from disk: tr.Schema().from_json(SCHEMA_PATH).
schema : tr . Schema = tr . data . tabular_sequence_testing_data . schema
max_sequence_length , d_model = 20 , 64
# Define the input module to process the tabular input features.
input_module = tr . TabularSequenceFeatures . from_schema (
schema ,
max_sequence_length = max_sequence_length ,
continuous_projection = d_model ,
aggregation = "concat" ,
masking = "causal" ,
)
# Define a transformer-config like the XLNet architecture.
transformer_config = tr . XLNetConfig . build (
d_model = d_model , n_head = 4 , n_layer = 2 , total_seq_length = max_sequence_length
)
# Define the model block including: inputs, masking, projection and transformer block.
body = tr . SequentialBlock (
input_module ,
tr . MLPBlock ([ d_model ]),
tr . TransformerBlock ( transformer_config , masking = input_module . masking )
)
# Define the evaluation top-N metrics and the cut-offs
metrics = [ NDCGAt ( top_ks = [ 20 , 40 ], labels_onehot = True ),
RecallAt ( top_ks = [ 20 , 40 ], labels_onehot = True )]
# Define a head with NextItemPredictionTask.
head = tr . Head (
body ,
tr . NextItemPredictionTask ( weight_tying = True , metrics = metrics ),
inputs = input_module ,
)
# Get the end-to-end Model class.
model = tr . Model ( head )Vous pouvez modifier le code précédent pour effectuer une classification binaire. Le masquage dans le module d'entrée peut être défini sur
Noneau lieu decausal. Lorsque vous définissez la tête, vous pouvez remplacer leNextItemPredictionTaskpar une instance deBinaryClassificationTask. Voir l'exemple de code dans la documentation de l'API pour la classe.
Vous pouvez installer Transformers4Rec avec PIP, conda ou exécuter un conteneur Docker.
Vous pouvez installer Transformers4REC avec la fonctionnalité pour utiliser le coader Merlin accéléré par GPU. L'installation avec le dataloader est fortement recommandée pour de meilleures performances. Ces composants peuvent être installés comme arguments facultatifs pour la commande pip install .
Pour installer Transformers4Rec à l'aide de PIP, exécutez la commande suivante:
pip install transformers4rec[nvtabular] -> Sachez que l'installation de Transformers4Rec avec pip n'installe pas automatiquement Rapids CUDF. -> CUDF est requis pour les versions accélérées par le GPU des transformations NVTABULALES et le Merlin Dataloader.
Les instructions pour l'installation du CUDF avec PIP sont disponibles ici: https://docs.rapids.ai/install#pip-install
pip install cudf-cu11 dask-cudf-cu11 --extra-index-url=https://pypi.nvidia.com Pour installer Transformers4Rec à l'aide de Conda, exécutez la commande suivante avec conda ou mamba pour créer un nouvel environnement.
mamba create -n transformers4rec-23.04 -c nvidia -c rapidsai -c pytorch -c conda-forge
transformers4rec=23.04 ` # NVIDIA Merlin `
nvtabular=23.04 ` # NVIDIA Merlin - Used in example notebooks `
python=3.10 ` # Compatible Python environment `
cudf=23.02 ` # RAPIDS cuDF - GPU accelerated DataFrame `
cudatoolkit=11.8 pytorch-cuda=11.8 ` # NVIDIA CUDA version ` Transformers4Rec est préinstallé dans le conteneur merlin-pytorch disponible dans le catalogue NVIDIA GPU Cloud (NGC).
Reportez-vous à la page de documentation des conteneurs Merlin pour plus d'informations sur les noms de conteneurs Merlin, les URL vers les images de conteneur dans le catalogue et les composants Merlin clés.
Le pipeline de bout en bout avec la page NVIDIA Merlin montre comment utiliser Transformers4rec et d'autres bibliothèques Merlin comme NVTABULAR pour créer un système de recommandation complet.
Nous avons plusieurs exemples de cahiers pour vous aider à créer un système de recommandation ou à intégrer Transformers4Rec dans votre système:
Si vous souhaitez apporter une contribution directe à Transformers4REC, reportez-vous à la contribution à Transformers4Rec. Nous sommes particulièrement intéressés par les contributions ou les demandes de fonctionnalités pour nos opérations d'ingénierie et de prétraitement. Pour faire avancer notre feuille de route Merlin, nous vous encourageons à partager tous les détails concernant le pipeline de votre système de recommandation en vous rendant sur https://developer.nvidia.com/merlin-devzone-spurvey.
Si vous souhaitez en savoir plus sur le fonctionnement de Transformers4Rec, reportez-vous à notre documentation Transformers4Rec. Nous avons également une documentation API qui décrit les spécificités des modules et classes disponibles dans Transformers4Rec.


