Transformers4Rec
v23.12.00
Transformers4Rec adalah perpustakaan yang fleksibel dan efisien untuk rekomendasi berbasis sekuensial dan sesi dan dapat bekerja dengan Pytorch.
Perpustakaan bekerja sebagai jembatan antara pemrosesan bahasa alami (NLP) dan sistem rekomendasi (RECSYS) dengan mengintegrasikan dengan salah satu kerangka kerja NLP paling populer, memeluk Face Transformers (HF). Transformers4Rec membuat arsitektur transformator canggih tersedia untuk peneliti dan praktisi industri Recsys.
Gambar berikut menunjukkan penggunaan perpustakaan dalam sistem rekomendasi. Data input biasanya merupakan urutan interaksi seperti item yang diramban dalam sesi web atau item yang dimasukkan ke dalam gerobak. Perpustakaan membantu Anda memproses dan memodelkan interaksi sehingga Anda dapat menghasilkan rekomendasi yang lebih baik untuk item berikutnya.
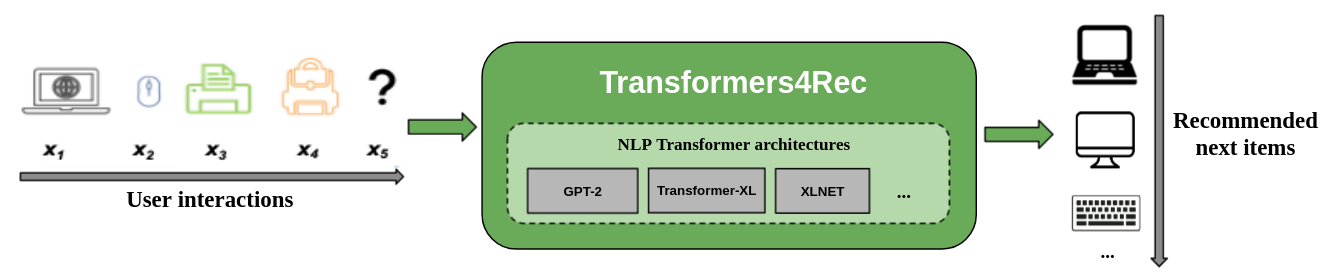
Algoritma rekomendasi tradisional biasanya mengabaikan dinamika temporal dan urutan interaksi ketika mencoba memodelkan perilaku pengguna. Secara umum, interaksi pengguna berikutnya terkait dengan urutan pilihan pengguna sebelumnya. Dalam beberapa kasus, ini mungkin merupakan pembelian atau putaran lagu yang berulang. Minat pengguna juga dapat menderita drift minat karena preferensi dapat berubah seiring waktu. Tantangan -tantangan itu ditangani oleh tugas rekomendasi berurutan .
Kasus penggunaan khusus dari rekomendasi sekuensial adalah tugas rekomendasi berbasis sesi di mana Anda hanya memiliki akses ke urutan interaksi pendek dalam sesi saat ini. Ini sangat umum dalam layanan online seperti e-commerce, berita, dan portal media di mana pengguna dapat memilih untuk menelusuri secara anonim karena kepatuhan GDPR yang membatasi pengumpulan cookie atau karena pengguna baru di situs tersebut. Tugas ini juga relevan untuk skenario di mana minat pengguna banyak berubah dari waktu ke waktu tergantung pada konteks atau niat pengguna. Dalam hal ini, memanfaatkan interaksi untuk sesi saat ini lebih menjanjikan daripada interaksi lama untuk memberikan rekomendasi yang relevan.
Untuk menangani rekomendasi berbasis sekuensial dan sesi, banyak algoritma pembelajaran urutan yang sebelumnya diterapkan dalam pembelajaran mesin dan penelitian NLP telah dieksplorasi untuk recsys berdasarkan tetangga K-Nearest, penambangan pola yang sering, model Markov tersembunyi, jaringan saraf berulang, dan arsitektur saraf yang lebih baru menggunakan mekanisme mandiri dan arsitektur transformator. Tidak seperti Transformers4Rec, kerangka kerja ini hanya menerima urutan ID item sebagai input dan tidak memberikan implementasi yang modularisasi dan dapat diskalakan untuk penggunaan produksi.
Transformers4Rec menawarkan manfaat berikut:
Fleksibilitas : Transformers4Rec menyediakan blok bangunan modularisasi yang dapat dikonfigurasi dan kompatibel dengan modul pytorch standar. Desain blok bangunan ini memungkinkan Anda untuk membuat arsitektur khusus dengan banyak menara, beberapa kepala/tugas, dan kerugian.
Akses ke HF Transformers : Lebih dari 64 arsitektur transformator yang berbeda dapat digunakan untuk mengevaluasi tugas rekomendasi berbasis sekuensial dan sesi Anda sebagai hasil dari integrasi transformator wajah yang memeluk.
Dukungan untuk beberapa fitur input : HF Transformers hanya mendukung urutan ID token sebagai input karena awalnya dirancang untuk NLP. Transformers4Rec memungkinkan Anda untuk menggunakan jenis data tabular berurutan lain sebagai input dengan transformer HF karena fitur kaya yang tersedia dalam kumpulan data Recsys. Transformers4Rec menggunakan skema untuk mengonfigurasi fitur input dan secara otomatis membuat lapisan yang diperlukan, seperti tabel penyematan, lapisan proyeksi, dan lapisan output berdasarkan target tanpa memerlukan perubahan kode untuk memasukkan fitur baru. Anda dapat menormalkan dan menggabungkan interaksi dan fitur input tingkat urutan dengan cara yang dapat dikonfigurasi.
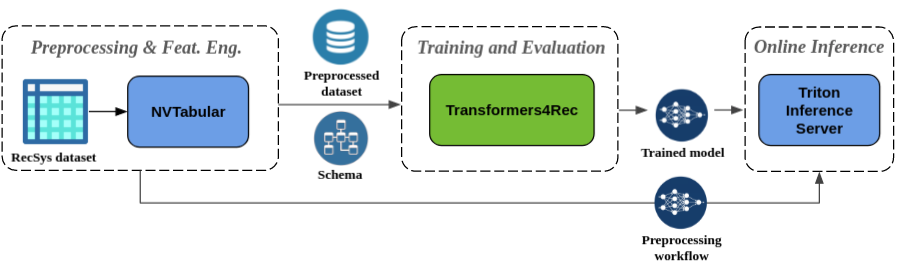
Preprocessing dan rekayasa fitur yang mulus : Sebagai bagian dari ekosistem Merlin, Transformers4Rec diintegrasikan dengan server inferensi nvtabular dan triton. Komponen-komponen ini memungkinkan Anda untuk membangun pipa yang dipercepat GPU untuk rekomendasi berbasis sekuensial dan sesi. NVTabular memiliki operasi preprocessing umum untuk rekomendasi berbasis sesi dan mengekspor skema dataset. Skema ini kompatibel dengan Transformers4Rec sehingga fitur input dapat dikonfigurasi secara otomatis. Anda dapat mengekspor model terlatih Anda untuk melayani dengan Triton Inference Server dalam satu pipa yang mencakup preprocessing fitur online dan inferensi model. Untuk informasi lebih lanjut, lihat pipa ujung ke ujung dengan Nvidia Merlin.
Transformers4Rec baru-baru ini memenangkan dua kompetisi rekomendasi berbasis sesi: WSDM Webtour Workshop Challenge 2021 (diselenggarakan oleh Booking.com) dan Sigir Ecommerce Workshop Data Challenge 2021 (diselenggarakan oleh Coveo). Perpustakaan memberikan akurasi yang lebih tinggi untuk rekomendasi berbasis sesi daripada algoritma dasar dan kami melakukan analisis empiris yang luas tentang akurasi. Pengamatan ini diterbitkan dalam makalah ACM Recsys'21 kami.
Melatih model dengan Transformers4Rec biasanya membutuhkan melakukan langkah-langkah tingkat tinggi berikut:
Berikan skema dan buat modul input.
Jika Anda menghadapi masalah rekomendasi berbasis sesi, Anda biasanya ingin menggunakan kelas TabulareSetenceFeatures karena menggabungkan fitur konteks dengan fitur berurutan.
Memberikan tugas prediksi.
Tugas yang disediakan langsung dari kotak tersedia dari dokumentasi API kami.
Bangun transformator-body dan ubah ini menjadi model.
Sampel kode berikut menunjukkan cara mendefinisikan dan melatih model XLNET dengan pytorch untuk tugas prediksi item berikutnya:
from transformers4rec import torch as tr
from transformers4rec . torch . ranking_metric import NDCGAt , RecallAt
# Create a schema or read one from disk: tr.Schema().from_json(SCHEMA_PATH).
schema : tr . Schema = tr . data . tabular_sequence_testing_data . schema
max_sequence_length , d_model = 20 , 64
# Define the input module to process the tabular input features.
input_module = tr . TabularSequenceFeatures . from_schema (
schema ,
max_sequence_length = max_sequence_length ,
continuous_projection = d_model ,
aggregation = "concat" ,
masking = "causal" ,
)
# Define a transformer-config like the XLNet architecture.
transformer_config = tr . XLNetConfig . build (
d_model = d_model , n_head = 4 , n_layer = 2 , total_seq_length = max_sequence_length
)
# Define the model block including: inputs, masking, projection and transformer block.
body = tr . SequentialBlock (
input_module ,
tr . MLPBlock ([ d_model ]),
tr . TransformerBlock ( transformer_config , masking = input_module . masking )
)
# Define the evaluation top-N metrics and the cut-offs
metrics = [ NDCGAt ( top_ks = [ 20 , 40 ], labels_onehot = True ),
RecallAt ( top_ks = [ 20 , 40 ], labels_onehot = True )]
# Define a head with NextItemPredictionTask.
head = tr . Head (
body ,
tr . NextItemPredictionTask ( weight_tying = True , metrics = metrics ),
inputs = input_module ,
)
# Get the end-to-end Model class.
model = tr . Model ( head )Anda dapat memodifikasi kode sebelumnya untuk melakukan klasifikasi biner. Masking dalam modul input dapat diatur ke
Nonealih -alihcausal. Saat Anda mendefinisikan kepala, Anda dapat menggantiNextItemPredictionTaskdengan instanceBinaryClassificationTask. Lihat kode sampel dalam dokumentasi API untuk kelas.
Anda dapat menginstal Transformers4Rec dengan Pip, Conda, atau menjalankan wadah Docker.
Anda dapat menginstal Transformers4Rec dengan fungsionalitas untuk menggunakan Merlin Dataloader yang dipercepat GPU. Instalasi dengan Dataloader sangat disarankan untuk kinerja yang lebih baik. Komponen -komponen tersebut dapat diinstal sebagai argumen opsional untuk perintah pip install .
Untuk menginstal Transformers4Rec menggunakan PIP, jalankan perintah berikut:
pip install transformers4rec[nvtabular] -> Ketahuilah bahwa menginstal Transformers4Rec dengan pip tidak secara otomatis memasang CUDF Rapids. -> CUDF diperlukan untuk versi transformasi NVTabular yang dipercepat GPU dan Merlin Dataloader.
Instruksi untuk menginstal CUDF dengan PIP tersedia di sini: https://docs.rapids.ai/install#pip-install
pip install cudf-cu11 dask-cudf-cu11 --extra-index-url=https://pypi.nvidia.com Untuk menginstal Transformers4Rec menggunakan conda, jalankan perintah berikut dengan conda atau mamba untuk menciptakan lingkungan baru.
mamba create -n transformers4rec-23.04 -c nvidia -c rapidsai -c pytorch -c conda-forge
transformers4rec=23.04 ` # NVIDIA Merlin `
nvtabular=23.04 ` # NVIDIA Merlin - Used in example notebooks `
python=3.10 ` # Compatible Python environment `
cudf=23.02 ` # RAPIDS cuDF - GPU accelerated DataFrame `
cudatoolkit=11.8 pytorch-cuda=11.8 ` # NVIDIA CUDA version ` Transformers4Rec sudah dipasang sebelumnya dalam wadah merlin-pytorch yang tersedia dari katalog NVIDIA GPU Cloud (NGC).
Lihat halaman dokumentasi Merlin Containers untuk informasi tentang nama wadah Merlin, URL ke gambar wadah dalam katalog, dan komponen utama Merlin.
Pipa ujung ke ujung dengan halaman NVIDIA Merlin menunjukkan cara menggunakan Transformers4Rec dan perpustakaan Merlin lainnya seperti NVTabular untuk membangun sistem rekomendasi yang lengkap.
Kami memiliki beberapa contoh notebook untuk membantu Anda membangun sistem rekomendasi atau mengintegrasikan Transformers4Rec ke dalam sistem Anda:
Jika Anda ingin memberikan kontribusi langsung ke Transformers4Rec, lihat berkontribusi pada Transformers4Rec. Kami sangat tertarik dengan kontribusi atau permintaan fitur untuk rekayasa fitur dan operasi preprocessing kami. Untuk lebih memajukan peta jalan Merlin kami, kami mendorong Anda untuk membagikan semua detail mengenai pipa sistem rekomendasi Anda dengan pergi ke https://developer.nvidia.com/merlin-devzone-survey.
Jika Anda tertarik untuk mempelajari lebih lanjut tentang cara kerja Transformers4Rec, lihat dokumentasi Transformers4Rec kami. Kami juga memiliki dokumentasi API yang menguraikan spesifik modul dan kelas yang tersedia dalam Transformers4Rec.


