Transformers4Rec
v23.12.00
Transformers4Rec é uma biblioteca flexível e eficiente para recomendação sequencial e baseada em sessão e pode trabalhar com o Pytorch.
A biblioteca funciona como uma ponte entre o processamento da linguagem natural (PNL) e os sistemas de recomendação (RECSYS), integrando -se a uma das estruturas de PNL mais populares, abraçando transformadores de rosto (HF). O Transformers4Rec disponibiliza arquiteturas de transformador de última geração para pesquisadores e profissionais da indústria da RECSYS.
A figura a seguir mostra o uso da biblioteca em um sistema de recomendação. Os dados de entrada geralmente são uma sequência de interações, como itens que são navegados em uma sessão ou itens da web colocados em um carrinho. A biblioteca ajuda a processar e modelar as interações para que você possa gerar melhores recomendações para o próximo item.
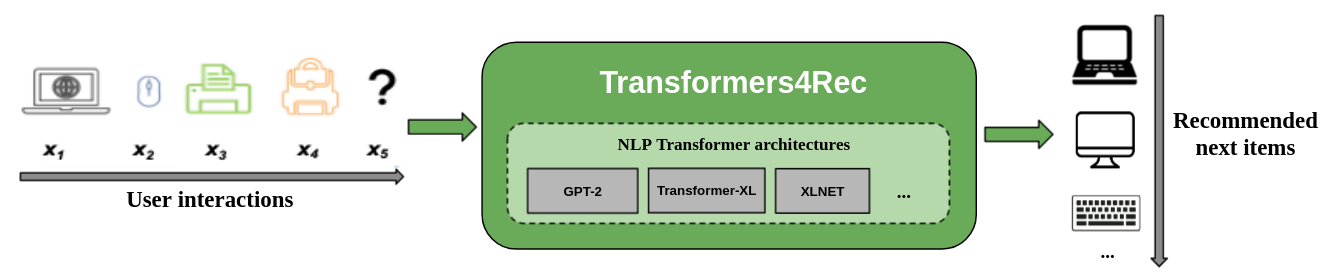
Os algoritmos de recomendação tradicional geralmente ignoram a dinâmica temporal e a sequência de interações ao tentar modelar o comportamento do usuário. Geralmente, a próxima interação do usuário está relacionada à sequência das opções anteriores do usuário. Em alguns casos, pode ser uma compra repetida ou reprodução de música. Os interesses do usuário também podem sofrer de desvio de juros, porque as preferências podem mudar com o tempo. Esses desafios são abordados pela tarefa de recomendação seqüencial .
Um caso de uso especial de recomendação sequencial é a tarefa de recomendação baseada em sessão, na qual você só tem acesso à curta sequência de interações na sessão atual. Isso é muito comum em serviços on-line, como comércio eletrônico, notícias e portais de mídia, onde o usuário pode optar por navegar anonimamente devido à conformidade com o GDPR que restringe a coleta de cookies ou porque o usuário é novo no site. Essa tarefa também é relevante para cenários em que os interesses dos usuários mudam muito ao longo do tempo, dependendo do contexto ou da intenção do usuário. Nesse caso, alavancar as interações para a sessão atual é mais promissor do que as interações antigas para fornecer recomendações relevantes.
Para lidar com a recomendação seqüencial e baseada em sessões, muitos algoritmos de aprendizado de sequência aplicados anteriormente em aprendizado de máquina e pesquisa de PNL foram explorados para o RECSYS baseado em vizinhos mais parecidos, mineração de padrões frequentes, modelos de Markov ocultos, redes neurais recorrentes e arquiteturas neurais mais recentemente usando o mecanismo de auto-distribuição e arquiteturas transformadoras. Ao contrário do Transformers4Rec, essas estruturas aceitam apenas sequências de IDs de itens como entrada e não fornecem uma implementação escalável e modularizada para o uso da produção.
Transformers4Rec oferece os seguintes benefícios:
Flexibilidade : o Transformers4Rec fornece blocos de construção modularizados configuráveis e compatíveis com módulos Pytorch padrão. Esse design de blocos de construção permite criar arquiteturas personalizadas com várias torres, várias cabeças/tarefas e perdas.
Acesso a Transformadores de HF : Mais de 64 arquiteturas de transformadores diferentes podem ser usadas para avaliar sua tarefa de recomendação sequencial e baseada em sessão como resultado da integração de Hugging Face Transformers.
Suporte para vários recursos de entrada : os transformadores de HF suportam apenas sequências de IDs de token como entrada porque foi originalmente projetado para PNL. O Transformers4Rec permite que você use outros tipos de dados de tabulares seqüenciais como entrada com transformadores de HF devido aos recursos ricos que estão disponíveis nos conjuntos de dados RECSYS. O Transformers4Rec usa um esquema para configurar os recursos de entrada e cria automaticamente as camadas necessárias, como incorporação de tabelas, camadas de projeção e camadas de saída com base no destino sem exigir alterações de código para incluir novos recursos. Você pode normalizar e combinar a interação e os recursos de entrada no nível da sequência de maneiras configuráveis.
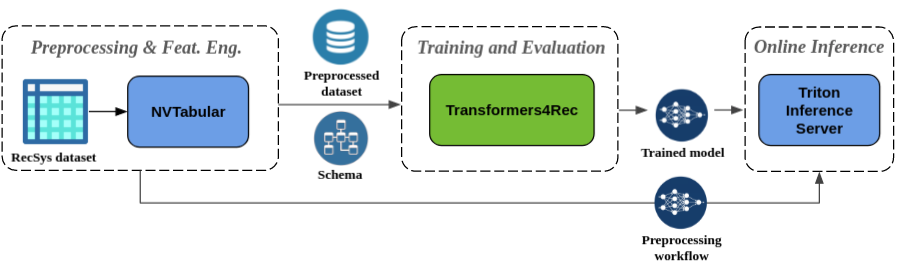
Engenharia de pré -processamento e recursos sem costura : como parte do ecossistema Merlin, o Transformers4Rec é integrado ao NVTabular e Triton Inference Server. Esses componentes permitem criar um pipeline totalmente acelerado por GPU para recomendação sequencial e baseada em sessão. A NVTabular possui operações comuns de pré-processamento para recomendação baseada em sessão e exporta um esquema de conjunto de dados. O esquema é compatível com o Transformers4Rec para que os recursos de entrada possam ser configurados automaticamente. Você pode exportar seus modelos treinados para servir com o Triton Inference Server em um único pipeline que inclui o pré -processamento de recursos on -line e a inferência do modelo. Para obter mais informações, consulte o pipeline de ponta a ponta com a Nvidia Merlin.
O Transformers4Rec venceu recentemente duas competições de recomendação baseadas em sessões: WSDM WebTour Workshop Challenge 2021 (organizado por booking.com) e Sigir Ecommerce Workshop Data Challenge 2021 (Organizado pela Coveo). A biblioteca fornece maior precisão para recomendação baseada em sessão do que os algoritmos de linha de base e realizamos uma extensa análise empírica sobre a precisão. Essas observações são publicadas em nosso artigo da ACM Recsys'21.
Treinar um modelo com Transformers4Rec normalmente requer executar as seguintes etapas de alto nível:
Forneça o esquema e construa um módulo de entrada.
Se você encontrar problemas de recomendação baseados em sessões, normalmente deseja usar a classe TabularSequenceFeatures, pois mescla os recursos de contexto com recursos seqüenciais.
Forneça as tarefas de previsão.
As tarefas fornecidas diretamente estão disponíveis na nossa documentação da API.
Construa um corpo de transformador e converta isso em um modelo.
A amostra de código a seguir mostra como definir e treinar um modelo XLNET com Pytorch para a Tarefa de Previsão de Item Next:
from transformers4rec import torch as tr
from transformers4rec . torch . ranking_metric import NDCGAt , RecallAt
# Create a schema or read one from disk: tr.Schema().from_json(SCHEMA_PATH).
schema : tr . Schema = tr . data . tabular_sequence_testing_data . schema
max_sequence_length , d_model = 20 , 64
# Define the input module to process the tabular input features.
input_module = tr . TabularSequenceFeatures . from_schema (
schema ,
max_sequence_length = max_sequence_length ,
continuous_projection = d_model ,
aggregation = "concat" ,
masking = "causal" ,
)
# Define a transformer-config like the XLNet architecture.
transformer_config = tr . XLNetConfig . build (
d_model = d_model , n_head = 4 , n_layer = 2 , total_seq_length = max_sequence_length
)
# Define the model block including: inputs, masking, projection and transformer block.
body = tr . SequentialBlock (
input_module ,
tr . MLPBlock ([ d_model ]),
tr . TransformerBlock ( transformer_config , masking = input_module . masking )
)
# Define the evaluation top-N metrics and the cut-offs
metrics = [ NDCGAt ( top_ks = [ 20 , 40 ], labels_onehot = True ),
RecallAt ( top_ks = [ 20 , 40 ], labels_onehot = True )]
# Define a head with NextItemPredictionTask.
head = tr . Head (
body ,
tr . NextItemPredictionTask ( weight_tying = True , metrics = metrics ),
inputs = input_module ,
)
# Get the end-to-end Model class.
model = tr . Model ( head )Você pode modificar o código anterior para executar a classificação binária. O mascaramento no módulo de entrada pode ser definido como
Noneem vez decausal. Ao definir a cabeça, você pode substituir oNextItemPredictionTaskpor uma instância doBinaryClassificationTask. Consulte o código de amostra na documentação da API para a classe.
Você pode instalar o Transformers4Rec com pip, conda ou executar um contêiner do docker.
Você pode instalar o Transformers4Rec com a funcionalidade para usar o Merlin Dataloader acelerado por GPU. A instalação com o Dataloader é altamente recomendada para melhor desempenho. Esses componentes podem ser instalados como argumentos opcionais para o comando pip install .
Para instalar o Transformers4Rec usando o PIP, execute o seguinte comando:
pip install transformers4rec[nvtabular] -> Esteja ciente de que a instalação do Transformers4Rec com pip não instala automaticamente o Rapids CUDF. -> CUDF é necessário para versões aceleradas por GPU de transformações nvtabulares e o Merlin Dataloader.
As instruções para a instalação do CUDF com PIP estão disponíveis aqui: https://docs.rapids.ai/install#pip-install
pip install cudf-cu11 dask-cudf-cu11 --extra-index-url=https://pypi.nvidia.com Para instalar o Transformers4Rec usando o CONDA, execute o seguinte comando com conda ou mamba para criar um novo ambiente.
mamba create -n transformers4rec-23.04 -c nvidia -c rapidsai -c pytorch -c conda-forge
transformers4rec=23.04 ` # NVIDIA Merlin `
nvtabular=23.04 ` # NVIDIA Merlin - Used in example notebooks `
python=3.10 ` # Compatible Python environment `
cudf=23.02 ` # RAPIDS cuDF - GPU accelerated DataFrame `
cudatoolkit=11.8 pytorch-cuda=11.8 ` # NVIDIA CUDA version ` Transformers4Rec é pré-instalado no contêiner merlin-pytorch , disponível no catálogo NVIDIA GPU Cloud (NGC).
Consulte a página de documentação de contêineres Merlin para obter informações sobre os nomes de contêineres Merlin, as imagens de URLs para contêiner no catálogo e os principais componentes do Merlin.
O pipeline de ponta a ponta com a página NVIDIA Merlin mostra como usar o Transformers4Rec e outras bibliotecas Merlin, como o NVTabular para criar um sistema de recomendação completo.
Temos vários notebooks de exemplo para ajudá -lo a criar um sistema de recomendação ou integrar Transformers4Rec em seu sistema:
Se você deseja fazer contribuições diretas ao Transformers4Rec, consulte a contribuição para o Transformers4Rec. Estamos particularmente interessados em contribuições ou solicitações de recursos para nossas operações de engenharia e pré -processamento de recursos. Para avançar ainda mais nosso roteiro de Merlin, incentivamos você a compartilhar todos os detalhes sobre o seu pipeline do sistema de recomendação, indo para https://developer.nvidia.com/merlin-devzone-survey.
Se você estiver interessado em aprender mais sobre como o Transformers4Rec funciona, consulte nossa documentação Transformers4Rec. Também temos documentação da API que descreve as especificidades dos módulos e classes disponíveis no Transformers4Rec.


