Transformers4Rec
v23.12.00
Transformers4Rec ist eine flexible und effiziente Bibliothek für sequentielle und Sitzungsbasis und kann mit Pytorch arbeiten.
Die Bibliothek arbeitet als Brücke zwischen natürlicher Sprachverarbeitung (NLP) und Empfehlungssystemen (Recsys), indem sie in einen der beliebtesten NLP -Frameworks, die Face Transformers (HF), integrieren. Transformers4Rec stellt hochmoderne Transformer-Architekturen für Recsys-Forscher und Branchenpraktiker zur Verfügung.
Die folgende Abbildung zeigt die Verwendung der Bibliothek in einem Empfehlungssystem. Eingabedaten sind typischerweise eine Abfolge von Interaktionen, wie z. B. Elemente, die in einer Websitzung oder in Elementen in einen Warenkorb gesteckt werden. Mit der Bibliothek können Sie die Interaktionen verarbeiten und modellieren, damit Sie bessere Empfehlungen für das nächste Element ausgeben können.
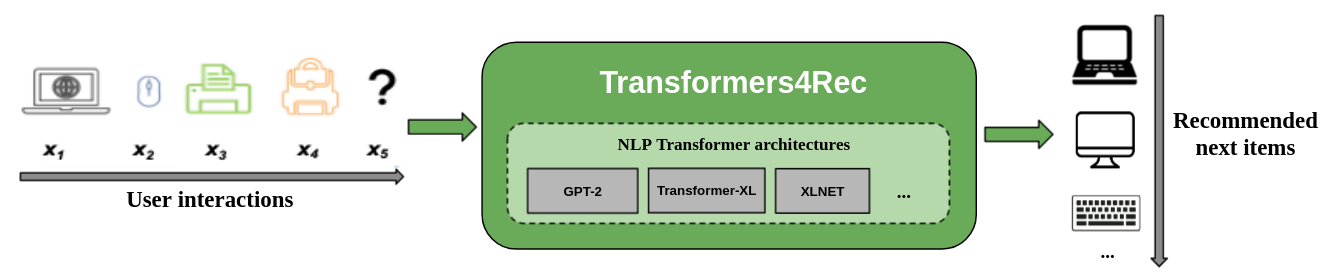
Herkömmliche Empfehlungsalgorithmen ignorieren normalerweise die zeitliche Dynamik und die Abfolge von Interaktionen, wenn Sie versuchen, das Benutzernverhalten zu modellieren. Im Allgemeinen bezieht sich die nächste Benutzerinteraktion mit der Abfolge der früheren Auswahlmöglichkeiten des Benutzers. In einigen Fällen kann es sich um einen wiederholten Kauf oder ein Songspiel handeln. Benutzerinteressen können auch unter Interesse Drift leiden, da sich die Präferenzen im Laufe der Zeit ändern können. Diese Herausforderungen werden von der sequentiellen Empfehlungsaufgabe angegangen.
Ein besonderer Anwendungsfall der sequentiellen Empfehlung ist die Sitzungsbasis-Empfehlungsaufgabe , bei der Sie nur Zugriff auf die kurze Abfolge von Interaktionen innerhalb der aktuellen Sitzung haben. Dies ist in Online-Diensten wie E-Commerce, Nachrichten und Medienportalen weit verbreitet, in denen der Benutzer aufgrund der Einhaltung der DSGVO, die das Sammeln von Cookies einschränkt, oder weil der Benutzer neu auf der Website ist, anonym durchsuchen. Diese Aufgabe ist auch für Szenarien relevant, in denen sich die Interessen der Benutzer je nach Benutzerkontext oder Absicht im Laufe der Zeit stark ändern. In diesem Fall ist die Nutzung der Interaktionen für die aktuelle Sitzung vielversprechender als alte Interaktionen, um relevante Empfehlungen abzugeben.
Um sich mit sequentiellen und Sitzungsbasis zu befassen, wurden viele Sequenzlernalgorithmen, die zuvor in maschinellem Lernen und NLP-Forschung angewendet wurden, für Recsys untersucht, die auf K-Nearest-Nachbarn, häufigem Musterabbau, versteckten Markov-Modellen, wiederkehrenden neuronalen Netzwerken und kürzlich neuronalen Architekturen mit den Mechanismus der Selbstbekämpfung und der Transformer-Architekturen untersucht wurden. Im Gegensatz zu Transformers4REC akzeptieren diese Frameworks nur Sequenzen von Element -IDs als Eingabe und bieten keine modularisierte, skalierbare Implementierung für die Produktionsnutzung.
Transformers4REC bietet die folgenden Vorteile:
Flexibilität : Transformers4REC bietet modularisierte Bausteine, die konfigurierbar und mit Standard -Pytorch -Modulen kompatibel sind. Mit diesem Design-Block-Design können Sie benutzerdefinierte Architekturen mit mehreren Türmen, mehreren Köpfen/Aufgaben und Verlusten erstellen.
Zugriff auf HF-Transformatoren : Mehr als 64 verschiedene Transformatorarchitekturen können verwendet werden, um Ihre sequentielle und auf Sitzungsbasis basierende Empfehlungsaufgabe als Ergebnis der Integration der umarmenden Gesichtstransformatoren zu bewerten.
Unterstützung für mehrere Eingabefunktionen : HF -Transformatoren unterstützen nur Sequenzen von Token -IDs als Eingabe, da sie ursprünglich für NLP entwickelt wurden. Mit Transformers4REC können Sie andere Arten von sequentiellen tabellarischen Daten als Eingabe mit HF -Transformatoren verwenden, da in Recsys -Datensätzen verfügbar sind. Transformers4Rec verwendet ein Schema, um die Eingabefunktionen zu konfigurieren, und erstellt automatisch die erforderlichen Schichten, z. B. ein Einbettungstabellen, Projektionsschichten und Ausgabeebenen basierend auf dem Ziel, ohne dass Codeänderungen erforderlich sind, um neue Funktionen einzuschließen. Sie können Interaktions- und Sequenzebene-Eingangsfunktionen auf konfigurierbare Weise normalisieren und kombinieren.
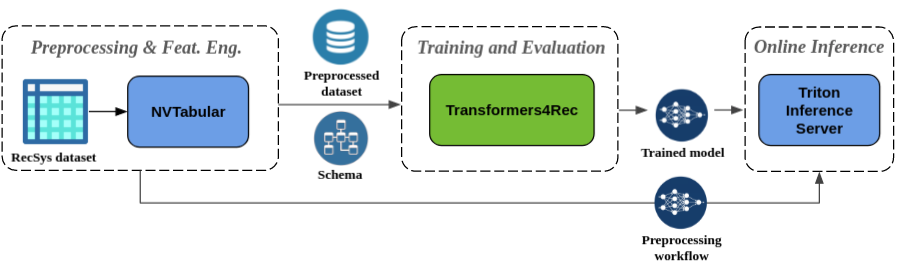
Nahtloses Vorverarbeitung und Feature Engineering : Als Teil des Merlin -Ökosystems ist Transformers4REC in NVTABULAR- und Triton Inference Server integriert. Diese Komponenten ermöglichen es Ihnen, eine vollständig gpubeschleunigte Pipeline für sequentielle und Sitzungsbasis zu erstellen. NVTABular verfügt über gemeinsame Vorverarbeitungsvorgänge für Sitzungsempfehlungen und exportiert ein Datensatzschema. Das Schema ist mit Transformators4REC kompatibel, damit Eingabefunktionen automatisch konfiguriert werden können. Sie können Ihre geschulten Modelle so exportieren, um mit Triton Inference Server in einer einzigen Pipeline zu dienen, die Online -Feature -Vorverarbeitung und Modellinferenz enthält. Weitere Informationen finden Sie in der End-to-End-Pipeline mit Nvidia Merlin.
Transformers4Rec hat kürzlich zwei Sitzungs-Basis-Empfehlungswettbewerbe gewonnen: WSDM Webtour Workshop Challenge 2021 (organisiert von booking.com) und Sigir E-Commerce Workshop Data Challenge 2021 (organisiert von Coveo). Die Bibliothek bietet eine höhere Genauigkeit für die Sitzungsempfehlung als Basisalgorithmen, und wir haben eine umfassende empirische Analyse zur Genauigkeit durchgeführt. Diese Beobachtungen werden in unserem ACM Recsys'21 -Papier veröffentlicht.
Training Ein Modell mit Transformers4REC erfordert in der Regel die folgenden hochrangigen Schritte aus:
Geben Sie das Schema an und konstruieren Sie ein Eingabemodul.
Wenn Sie auf Sitzungsbasis-Empfehlungsprobleme stoßen, möchten Sie in der Regel die TabelleSequenzfeatures-Klasse verwenden, da sie Kontextfunktionen mit sequentiellen Funktionen verschmelzen.
Bereitstellung der Vorhersageaufgaben.
Die Aufgaben, die direkt aus der Box zur Verfügung gestellt werden, sind in unserer API -Dokumentation erhältlich.
Konstruieren Sie einen Transformator-Körper und konvertieren Sie diese in ein Modell.
Das folgende Code-Beispiel zeigt, wie ein XLNET-Modell mit Pytorch für die Vorhersage-Aufgabe als nächster Element definiert und trainiert wird:
from transformers4rec import torch as tr
from transformers4rec . torch . ranking_metric import NDCGAt , RecallAt
# Create a schema or read one from disk: tr.Schema().from_json(SCHEMA_PATH).
schema : tr . Schema = tr . data . tabular_sequence_testing_data . schema
max_sequence_length , d_model = 20 , 64
# Define the input module to process the tabular input features.
input_module = tr . TabularSequenceFeatures . from_schema (
schema ,
max_sequence_length = max_sequence_length ,
continuous_projection = d_model ,
aggregation = "concat" ,
masking = "causal" ,
)
# Define a transformer-config like the XLNet architecture.
transformer_config = tr . XLNetConfig . build (
d_model = d_model , n_head = 4 , n_layer = 2 , total_seq_length = max_sequence_length
)
# Define the model block including: inputs, masking, projection and transformer block.
body = tr . SequentialBlock (
input_module ,
tr . MLPBlock ([ d_model ]),
tr . TransformerBlock ( transformer_config , masking = input_module . masking )
)
# Define the evaluation top-N metrics and the cut-offs
metrics = [ NDCGAt ( top_ks = [ 20 , 40 ], labels_onehot = True ),
RecallAt ( top_ks = [ 20 , 40 ], labels_onehot = True )]
# Define a head with NextItemPredictionTask.
head = tr . Head (
body ,
tr . NextItemPredictionTask ( weight_tying = True , metrics = metrics ),
inputs = input_module ,
)
# Get the end-to-end Model class.
model = tr . Model ( head )Sie können den vorhergehenden Code so ändern, dass eine binäre Klassifizierung durchgeführt wird. Die Maskierung im Eingangsmodul kann auf
Noneanstelle voncausaleingestellt werden. Wenn Sie den Kopf definieren, können Sie dieNextItemPredictionTaskdurch eine Instanz vonBinaryClassificationTaskersetzen. Siehe den Beispielcode in der API -Dokumentation für die Klasse.
Sie können Transformers4Rec mit PIP, Conda oder einem Docker -Container ausführen.
Sie können Transformers4Rec mit der Funktionalität installieren, um den GPU-bewerteten Merlin Dataloader zu verwenden. Die Installation mit dem Dataloader ist dringend empfohlen, um eine bessere Leistung zu erzielen. Diese Komponenten können als optionale Argumente für den Befehl pip install installiert werden.
Um Transformers4Rec mit PIP zu installieren, führen Sie den folgenden Befehl aus:
pip install transformers4rec[nvtabular] -> Beachten Sie, dass die Installation von Transformers4Rec mit pip nicht automatisch Rapids CUDF installiert. -> CUDF ist für GPU-beschleunigte Versionen von NVTabular-Transformationen und des Merlin Dataloaders erforderlich.
Anweisungen zur Installation von CUDF mit PIP finden Sie hier: https://docs.rapids.ai/install#pip-install
pip install cudf-cu11 dask-cudf-cu11 --extra-index-url=https://pypi.nvidia.com Führen Sie den folgenden Befehl mit conda oder mamba aus, um eine neue Umgebung zu schaffen, um Transformers4Rec mit Conda zu installieren.
mamba create -n transformers4rec-23.04 -c nvidia -c rapidsai -c pytorch -c conda-forge
transformers4rec=23.04 ` # NVIDIA Merlin `
nvtabular=23.04 ` # NVIDIA Merlin - Used in example notebooks `
python=3.10 ` # Compatible Python environment `
cudf=23.02 ` # RAPIDS cuDF - GPU accelerated DataFrame `
cudatoolkit=11.8 pytorch-cuda=11.8 ` # NVIDIA CUDA version ` Transformers4Rec ist im merlin-pytorch -Behälter vorinstalliert, der im NVIDIA GPU Cloud (NGC) -Katalog erhältlich ist.
Informationen zu den Merlin -Containernamen, URLs zu Containerbildern im Katalog und wichtigen Merlin -Komponenten finden Sie auf der Merlin Container -Dokumentationsseite.
Die End-to-End-Pipeline mit Nvidia Merlin-Seite zeigt, wie Transformers4REC und andere Merlin-Bibliotheken wie NVTABular verwendet werden, um ein vollständiges Empfehlungssystem zu erstellen.
Wir haben mehrere Beispiel -Notizbücher, mit denen Sie ein Empfehlungssystem erstellen oder Transformers4Rec in Ihr System integrieren:
Wenn Sie direkte Beiträge zu Transformers4Rec leisten möchten, finden Sie in Transformers4Rec. Wir interessieren uns besonders für Beiträge oder Feature -Anfragen für unsere Feature Engineering- und Preprozessing -Operationen. Um unsere Merlin-Roadmap weiter voranzutreiben, empfehlen wir Ihnen, alle Details zu Ihrer Empfehlungssystempipeline zu teilen, indem wir unter https://developer.nvidia.com/merlin-devzone-survey gehen.
Wenn Sie mehr darüber erfahren möchten, wie Transformers4Rec funktioniert, lesen Sie unsere Transformers4REC -Dokumentation. Wir haben auch eine API -Dokumentation, in der die Einzelheiten der verfügbaren Module und Klassen innerhalb von Transformers4REC beschrieben werden.


