Transformers4Rec
v23.12.00
Transformers4Recは、シーケンシャルおよびセッションベースの推奨のための柔軟で効率的なライブラリであり、Pytorchで動作することができます。
ライブラリは、最も人気のあるNLPフレームワークの1つであるフェイストランス(HF)と統合することにより、自然言語処理(NLP)と推奨システム(RECSYS)の間の橋渡しとして機能します。 Transformers4Recは、Recsysの研究者や産業実務家が利用できる最先端のトランスアーキテクチャを利用できます。
次の図は、推奨システムでのライブラリの使用を示しています。入力データは、通常、Webセッションで閲覧されたアイテムやカートに入れられたアイテムなどの一連のインタラクションです。ライブラリは、次のアイテムのより良い推奨事項を出力できるように、インタラクションを処理およびモデル化するのに役立ちます。
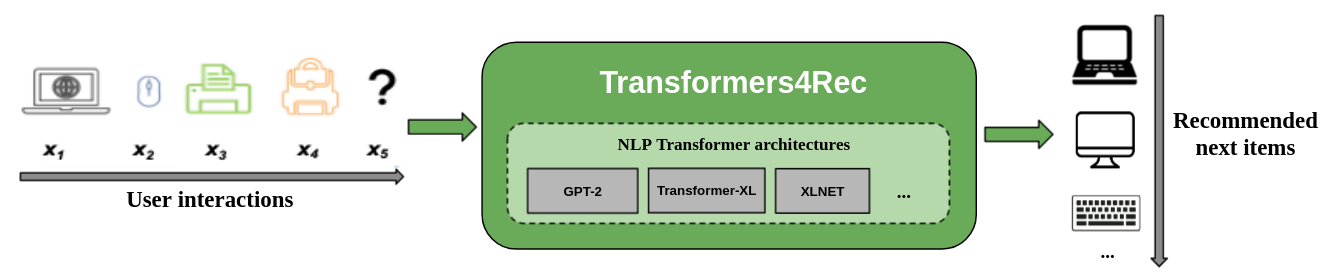
従来の推奨アルゴリズムは通常、ユーザーの動作をモデル化しようとするときの時間的ダイナミクスと一連の相互作用を無視します。一般に、次のユーザーの相互作用は、ユーザーの以前の選択のシーケンスに関連しています。場合によっては、繰り返し購入または曲のプレイかもしれません。ユーザーの関心は、好みが時間とともに変化する可能性があるため、関心のドリフトに苦しむ可能性があります。これらの課題は、順次推奨タスクによって対処されます。
シーケンシャル推奨の特別なユースケースは、現在のセッション内の短い一連の相互作用にのみアクセスできるセッションベースの推奨タスクです。これは、eコマース、ニュース、メディアポータルなどのオンラインサービスで非常に一般的であり、ユーザーがCookieの収集を制限するGDPRコンプライアンスやユーザーがサイトに新しくなったために匿名で閲覧することを選択します。このタスクは、ユーザーのコンテキストや意図に応じて、ユーザーの関心が時間とともに大きく変化するシナリオにも関連しています。この場合、現在のセッションの相互作用を活用することは、関連する推奨事項を提供するために、古い相互作用よりも有望です。
シーケンシャルおよびセッションベースの推奨事項に対処するために、以前に機械学習およびNLP研究に適用されていた多くのシーケンス学習アルゴリズムが、k-nearest Neighbors、頻繁なパターンマイニング、隠されたマルコフモデル、再発性ニューラルネットワーク、および最近では自己立てメカニズムとトランスアーキテクチャを使用したニューラルアーキテクチャに基づいて調査されています。 Transformers4RECとは異なり、これらのフレームワークはアイテムIDのシーケンスのみを入力として受け入れ、生産使用のためのモジュール化されたスケーラブルな実装を提供しません。
Transformers4Recは次の利点を提供します。
柔軟性:Transformers4Recは、標準のPytorchモジュールと互換性のある構成可能なモジュール化されたビルディングブロックを提供します。この建物ブロック設計により、複数のタワー、複数のヘッド/タスク、および損失を備えたカスタムアーキテクチャを作成できます。
HFトランスへのアクセス:64を超えるさまざまな変圧器アーキテクチャを使用して、抱き合ったフェイストランスの統合の結果として、シーケンシャルおよびセッションベースの推奨タスクを評価できます。
複数の入力機能のサポート:HFトランスは、元々NLP向けに設計されていたため、入力としてトークンIDのシーケンスのみをサポートしています。 Transformers4RECを使用すると、Recsysデータセットで利用できるリッチな機能により、HFトランスでの入力として他のタイプのシーケンシャル表形式データを使用できます。 Transformers4Recはスキーマを使用して入力機能を構成し、新しい機能を含めるためにコード変更を必要とせずに、ターゲットに基づいてテーブル、投影層、出力層などの必要なレイヤーを自動的に作成します。構成可能な方法で、相互作用とシーケンスレベルの入力機能を正規化および結合できます。
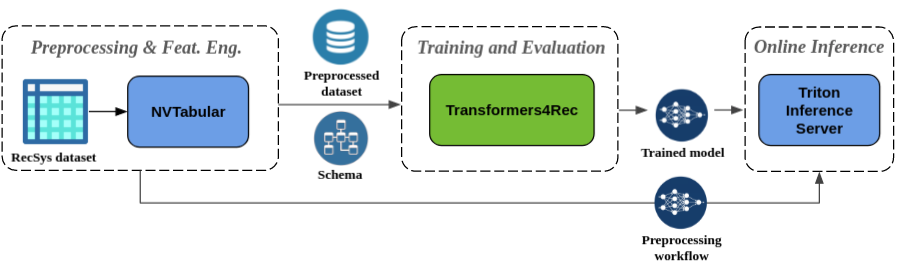
シームレスな前処理と機能エンジニアリング:Merlinエコシステムの一部として、Transformers4RecはNVTabularおよびTriton Incerence Serverと統合されています。これらのコンポーネントを使用すると、シーケンシャルおよびセッションベースの推奨のために、完全にGPU加速パイプラインを構築できます。 NVTabularには、セッションベースの推奨のための一般的な前処理操作があり、データセットスキーマをエクスポートしています。スキーマはtransformers4recと互換性があるため、入力機能を自動的に構成できます。トレーニングされたモデルをエクスポートして、オンライン機能前処理とモデル推論を含む単一のパイプラインでTriton Incerence Serverを使用できます。詳細については、Nvidia Merlinのエンドツーエンドパイプラインを参照してください。
Transformers4Recは最近、WSDM Webtour Workshop Challenge 2021(Booking.comが主催)とSigir Ecommerce Workshop Data Challenge 2021(Coveoが主催)と2つのセッションベースの推奨コンテストで優勝しました。ライブラリは、ベースラインアルゴリズムよりもセッションベースの推奨事項に対してより高い精度を提供し、精度に関する広範な経験的分析を実行しました。これらの観察結果は、ACM Recsys'21論文に掲載されています。
Transformers4RECでモデルをトレーニングするには、通常、次の高レベルの手順を実行する必要があります。
スキーマを提供し、入力モジュールを構築します。
セッションベースの推奨の問題に遭遇した場合、通常、コンテキスト機能とシーケンシャル機能をマージするため、Tabular sequencefeaturesクラスを使用する必要があります。
予測タスクを提供します。
すぐに提供されるタスクは、APIドキュメントから入手できます。
トランスボディを構築し、これをモデルに変換します。
次のコードサンプルは、XLNETモデルをPytorchを使用して次の項目予測タスクで定義およびトレーニングする方法を示しています。
from transformers4rec import torch as tr
from transformers4rec . torch . ranking_metric import NDCGAt , RecallAt
# Create a schema or read one from disk: tr.Schema().from_json(SCHEMA_PATH).
schema : tr . Schema = tr . data . tabular_sequence_testing_data . schema
max_sequence_length , d_model = 20 , 64
# Define the input module to process the tabular input features.
input_module = tr . TabularSequenceFeatures . from_schema (
schema ,
max_sequence_length = max_sequence_length ,
continuous_projection = d_model ,
aggregation = "concat" ,
masking = "causal" ,
)
# Define a transformer-config like the XLNet architecture.
transformer_config = tr . XLNetConfig . build (
d_model = d_model , n_head = 4 , n_layer = 2 , total_seq_length = max_sequence_length
)
# Define the model block including: inputs, masking, projection and transformer block.
body = tr . SequentialBlock (
input_module ,
tr . MLPBlock ([ d_model ]),
tr . TransformerBlock ( transformer_config , masking = input_module . masking )
)
# Define the evaluation top-N metrics and the cut-offs
metrics = [ NDCGAt ( top_ks = [ 20 , 40 ], labels_onehot = True ),
RecallAt ( top_ks = [ 20 , 40 ], labels_onehot = True )]
# Define a head with NextItemPredictionTask.
head = tr . Head (
body ,
tr . NextItemPredictionTask ( weight_tying = True , metrics = metrics ),
inputs = input_module ,
)
# Get the end-to-end Model class.
model = tr . Model ( head )前のコードを変更して、バイナリ分類を実行できます。入力モジュールのマスキングは、
causalの代わりにNoneで設定できます。ヘッドを定義すると、NextItemPredictionTaskBinaryClassificationTaskのインスタンスに置き換えることができます。クラスのAPIドキュメントのサンプルコードを参照してください。
Transformers4RecをPIP、Conda、またはDockerコンテナを使用してインストールできます。
Transformers4Recを機能してインストールして、GPUが加速したMerlin Dataloaderを使用できます。パフォーマンスを向上させるには、Dataloaderでのインストールを強くお勧めします。これらのコンポーネントは、 pip installコマンドのオプションの引数としてインストールできます。
PIPを使用してTransformers4recをインストールするには、次のコマンドを実行します。
pip install transformers4rec[nvtabular] - > pipでTransformers4Recをインストールすると、Rapids CUDFが自動的にインストールされないことに注意してください。 - > cudfは、nvtabular変換のGPUアクセラレーションバージョンとMerlin Dataloaderに必要です。
PIPでCUDFをインストールするための手順は、https://docs.rapids.ai/install#pip-installで入手できます。
pip install cudf-cu11 dask-cudf-cu11 --extra-index-url=https://pypi.nvidia.comCondaを使用してTransformers4recをインストールするには、 condaまたはmambaで次のコマンドを実行して新しい環境を作成します。
mamba create -n transformers4rec-23.04 -c nvidia -c rapidsai -c pytorch -c conda-forge
transformers4rec=23.04 ` # NVIDIA Merlin `
nvtabular=23.04 ` # NVIDIA Merlin - Used in example notebooks `
python=3.10 ` # Compatible Python environment `
cudf=23.02 ` # RAPIDS cuDF - GPU accelerated DataFrame `
cudatoolkit=11.8 pytorch-cuda=11.8 ` # NVIDIA CUDA version `Transformers4Recは、NVIDIA GPUクラウド(NGC)カタログから使用できるmerlin-pytorchコンテナに事前にインストールされています。
Merlinコンテナの名前、カタログ内のコンテナ画像へのURL、およびキーマーリンコンポーネントについては、Merlin Containersドキュメントページを参照してください。
Nvidia Merlinページを備えたエンドツーエンドのパイプラインは、Transformers4RecやNVTabularのような他のMerlinライブラリを使用して、完全な推奨システムを構築する方法を示しています。
推奨システムの構築やTransformers4recをシステムに統合するのに役立つノートブックの例がいくつかあります。
Transformers4recに直接貢献したい場合は、Transformers4Recへの貢献を参照してください。特に、機能エンジニアリングおよび前処理操作の貢献や機能のリクエストに興味があります。 Merlinのロードマップをさらに進めるために、https://developer.nvidia.com/merlin-devzone-surveyにアクセスして、推奨システムパイプラインに関するすべての詳細を共有することをお勧めします。
Transformers4Recの仕組みについて詳しく知りたい場合は、Transformers4Recドキュメントを参照してください。また、Transformers4Rec内の利用可能なモジュールとクラスの詳細を概説するAPIドキュメントもあります。


