qdurllm
v0.0.0?
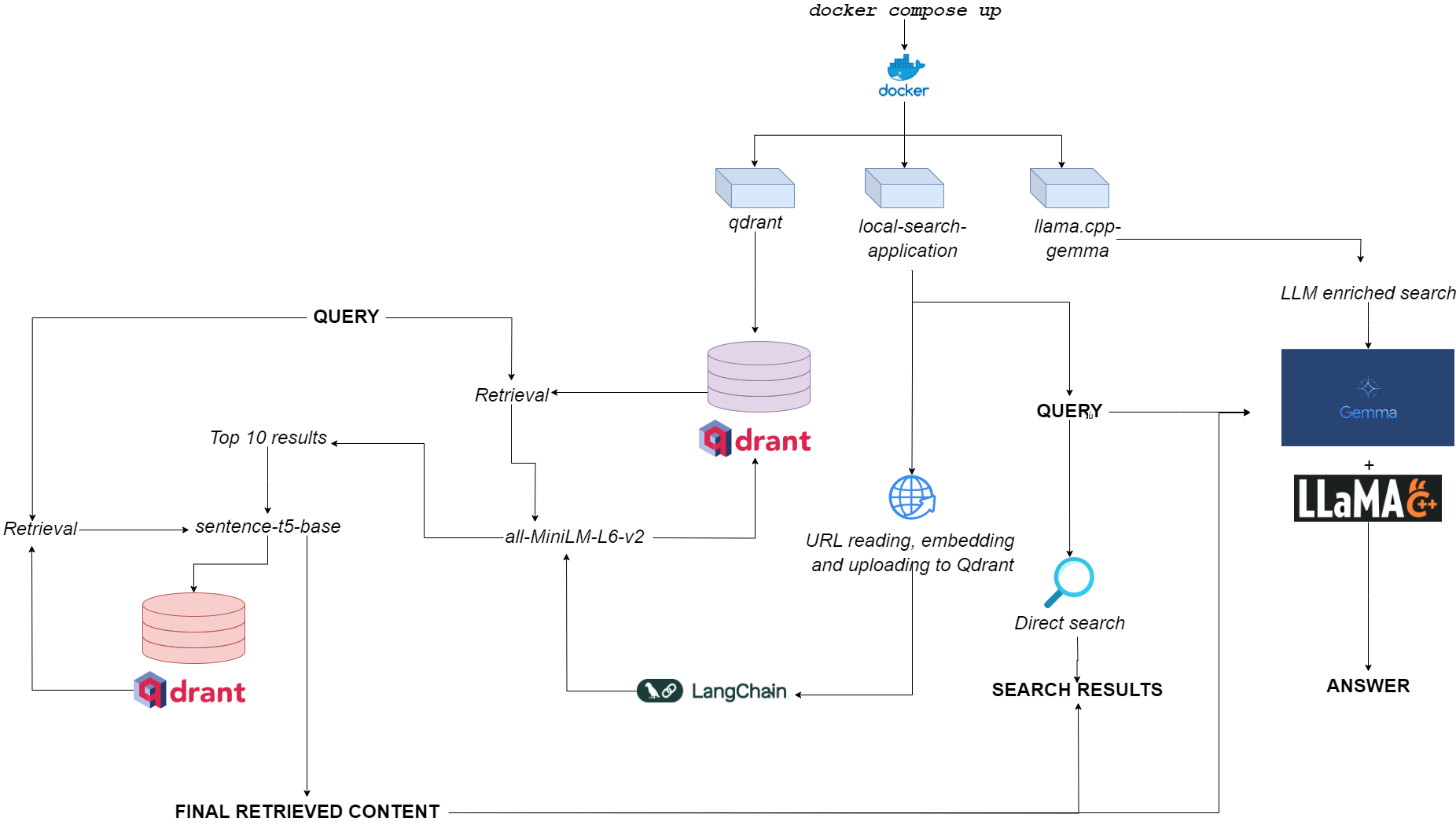
Блок -схема для Qdurllm
Qdurllm ( qd rant url s и l arge l anguage m odels) - это локальная поисковая система, которая позволяет выбирать и загружать контент URL в векторную базу данных: после этого вы можете искать, получать и общаться с этим контентом.
Это обеспечивается применением многоконтравнеров Docker, используя Qdrant, Langchain, Llama.cpp, квантовую гемму и Gradio.
Отправляйтесь в демонстрационное пространство на Huggingface?
Единственное требование-иметь docker и docker-compose .
Если у вас их нет, обязательно установите их здесь.
Вы можете установить приложение, клонируя репозиторий GitHub
git clone https://github.com/AstraBert/qdurllm.git
cd qdurllm Или вы можете просто вставить следующий текст в файл compose.yaml :
networks :
mynet :
driver : bridge
services :
local-search-application :
image : astrabert/local-search-application
networks :
- mynet
ports :
- " 7860:7860 "
qdrant :
image : qdrant/qdrant
ports :
- " 6333:6333 "
volumes :
- " ./qdrant_storage:/qdrant/storage "
networks :
- mynet
llama_server :
image : astrabert/llama.cpp-gemma
ports :
- " 8000:8000 "
networks :
- mynetРазмещение файла в любой каталог, который вы хотите в вашей файловой системе.
До запуска приложения вы можете при желании вытащить все необходимые изображения из Docker Hub:
docker pull qdrant/qdrant
docker pull astrabert/llama.cpp-gemma
docker pull astrabert/local-search-applicationПри запуске (см. Использование) приложение запускает три контейнера:
qdrant (порт 6333): служит поставщиком векторной базы данных для получения семантического поиска поискаllama.cpp-gemma (порт 8000): это реализация квантовой модели Джеммы, предоставленной LMStudio и Google, обслуживаемой на сервере llama.cpp . Это работает для областей генерации текста, обогащая опыт поиска пользователя.local-search-application (порт 7860): интерфейс Gradio вкладка с:llama.cpp-gemmaall-MiniLM-L6-v2 (который идентифицирует 10 лучших совпадений) и sentence-t5-base (которая переоценивает 10 лучших совпадений и извлекает из них наилучший удар)-это та же самая реализация Rag, используемая в комбинации с llama.cpp-gemma . Хотите увидеть, как работает двойная тряпка по сравнению с однослойной тряпкой? Отправляйся сюда!Общее вычислительное бремя достаточно легкое, чтобы приложение запустило не только безинную полосу, но и с низкой доступностью оперативной памяти (> = 8 ГБ, хотя для того, чтобы Gemma может занять до 10 минут, чтобы ответить на 8 ГБ оперативной памяти).
Вы можете заставить приложение работать со следующей - действительно просто - команда, которую нужно запускать в том же каталоге, где вы хранили свой файл compose.yaml :
docker compose up -d Если вы уже вытащили все изображения, вы найдете приложение, работающее по адресу http://localhost:7860 или http://0.0.0.0:7860 менее чем за минуту.
Если вы не вытащили изображения, вам придется подождать, чтобы их установка была завершена, прежде чем использовать приложение.
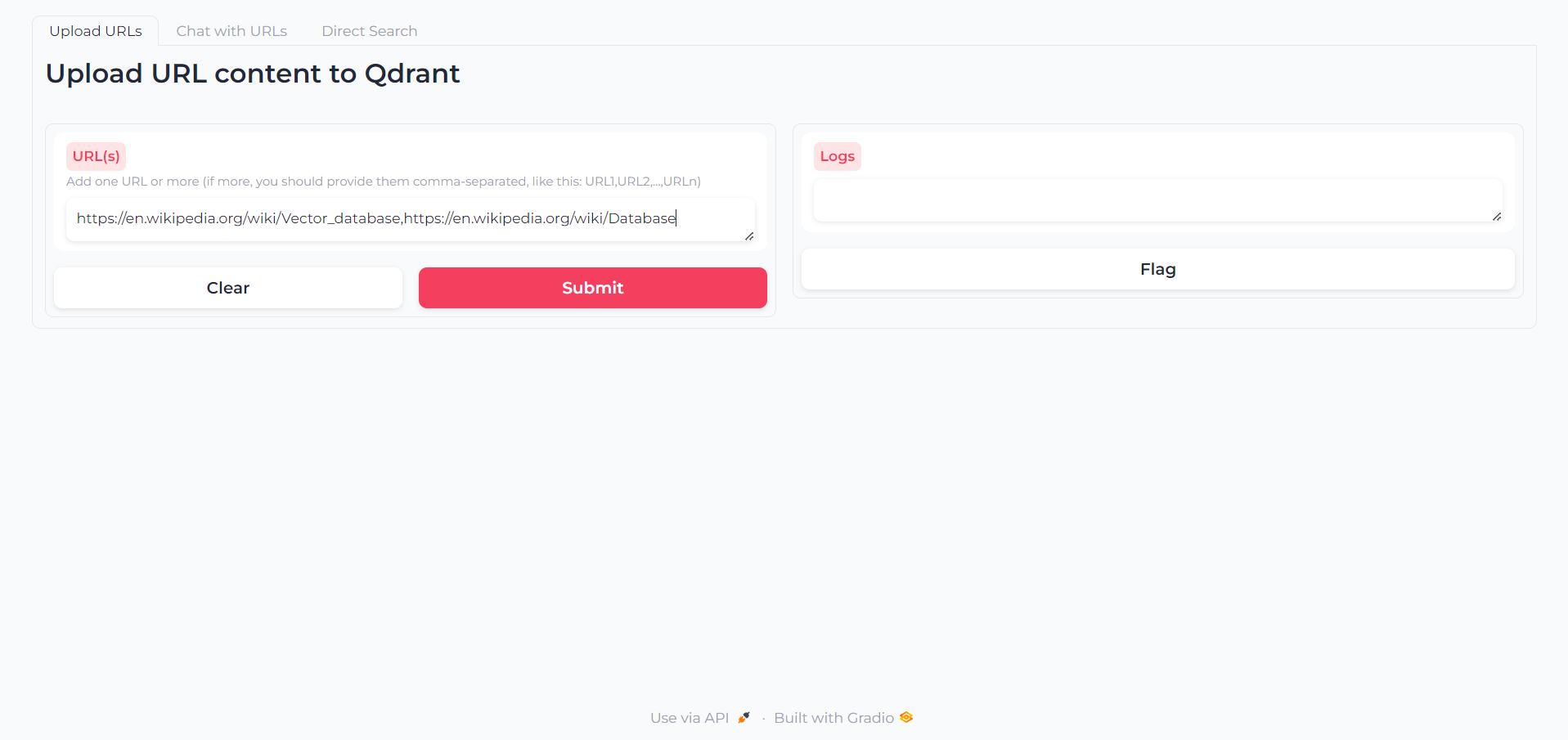
Как только приложение загружено, вы найдете первую вкладку, в которой вы сможете написать URL -адреса, содержимое которого вы хотите взаимодействовать:
Теперь, когда ваши URL-адреса загружаются, вы можете поболтать с их контентом через llama.cpp-gemma :
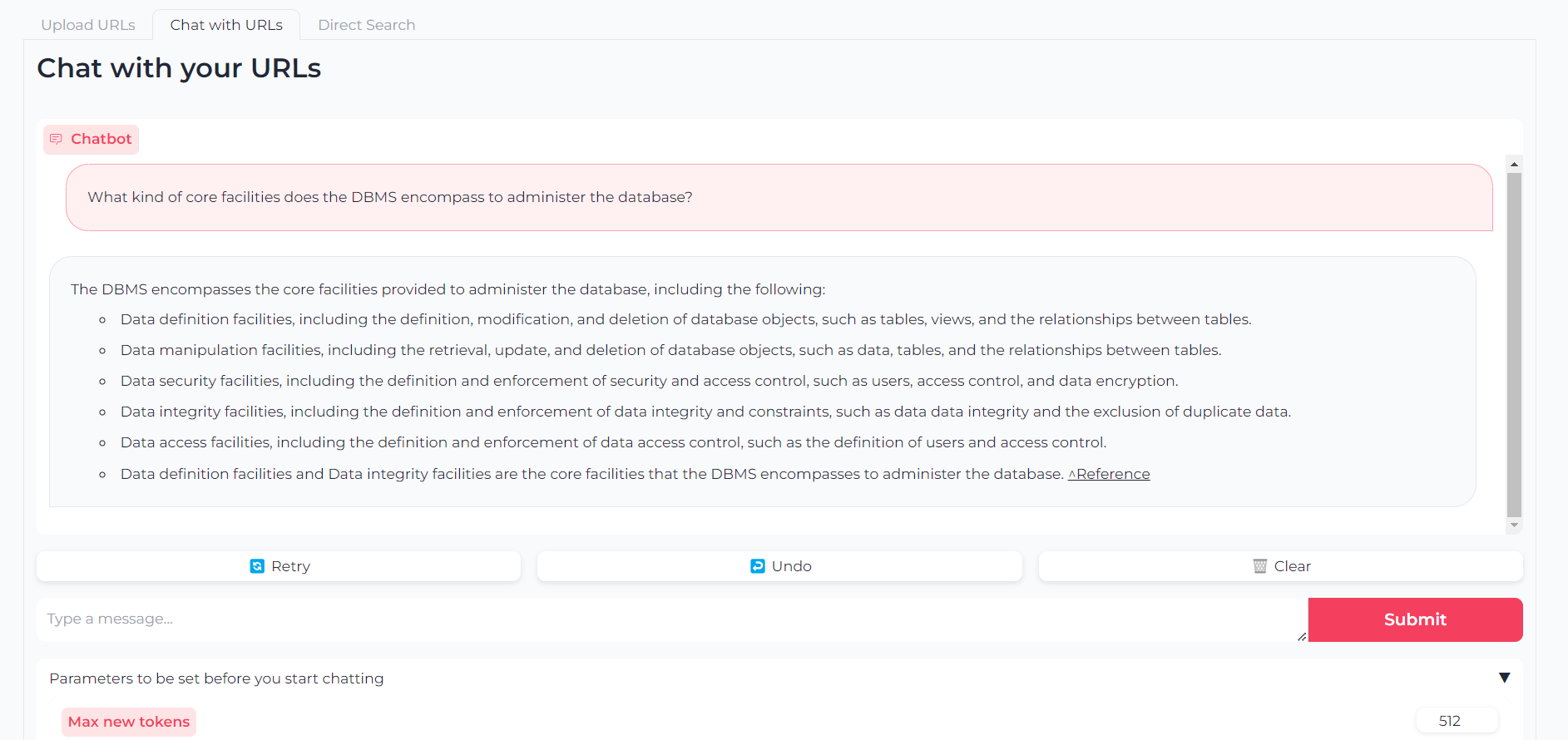
Обратите внимание, что вы также можете установить параметры, такие как максимальные выходные токены, температура, штраф за повторение и семена генерации
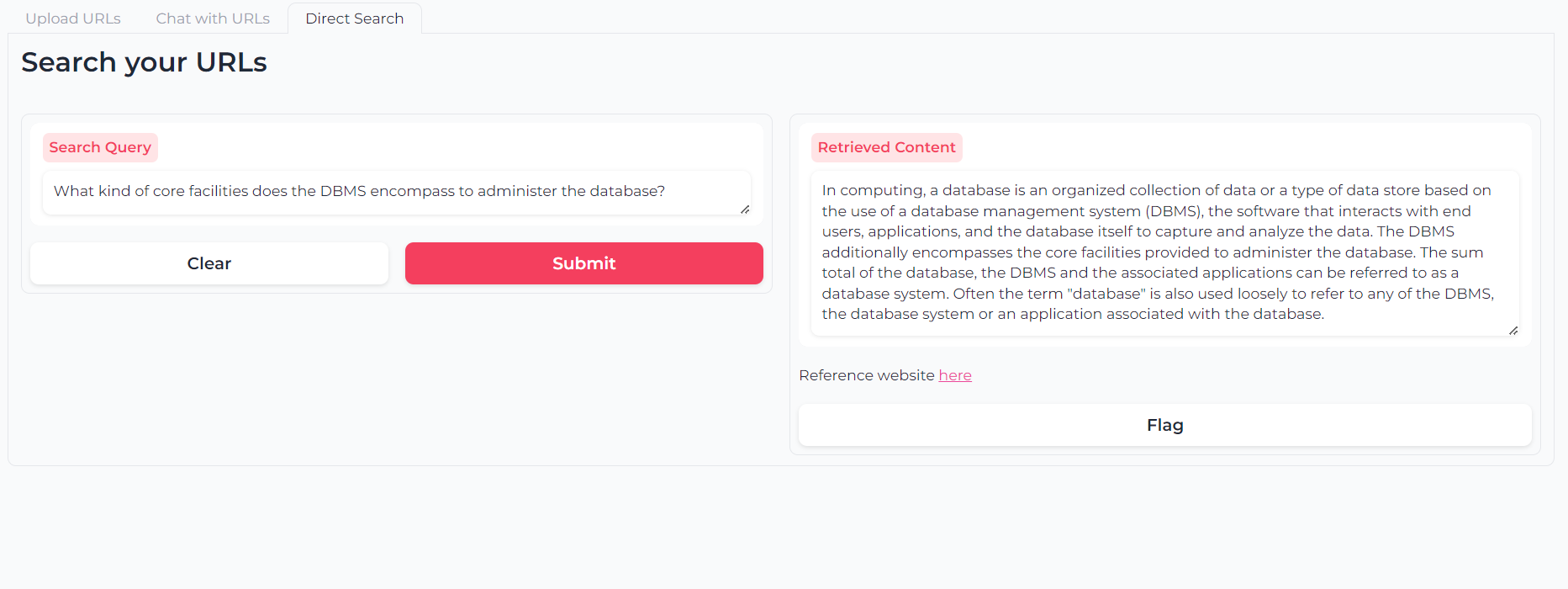
Или вы можете использовать семантический поиск с двумя слоями, чтобы напрямую запросить контент (ы) вашего URL-адреса:
Программное обеспечение (и всегда будет) с открытым исходным кодом, предоставляется в соответствии с лицензией MIT.
Любой может использовать, изменять и перераспределить любую ее часть, если цитируется автор Астра Клелия Бертелли.
Вклад всегда более чем приветствуется! Не стесняйтесь помечать проблемы, открывать PRS или свяжитесь с автором, чтобы предложить любые изменения, запросить функции или улучшить код.
Если вы нашли приложение полезным, рассмотрите возможность финансирования его, чтобы разрешить улучшения!


