qdurllm
v0.0.0?
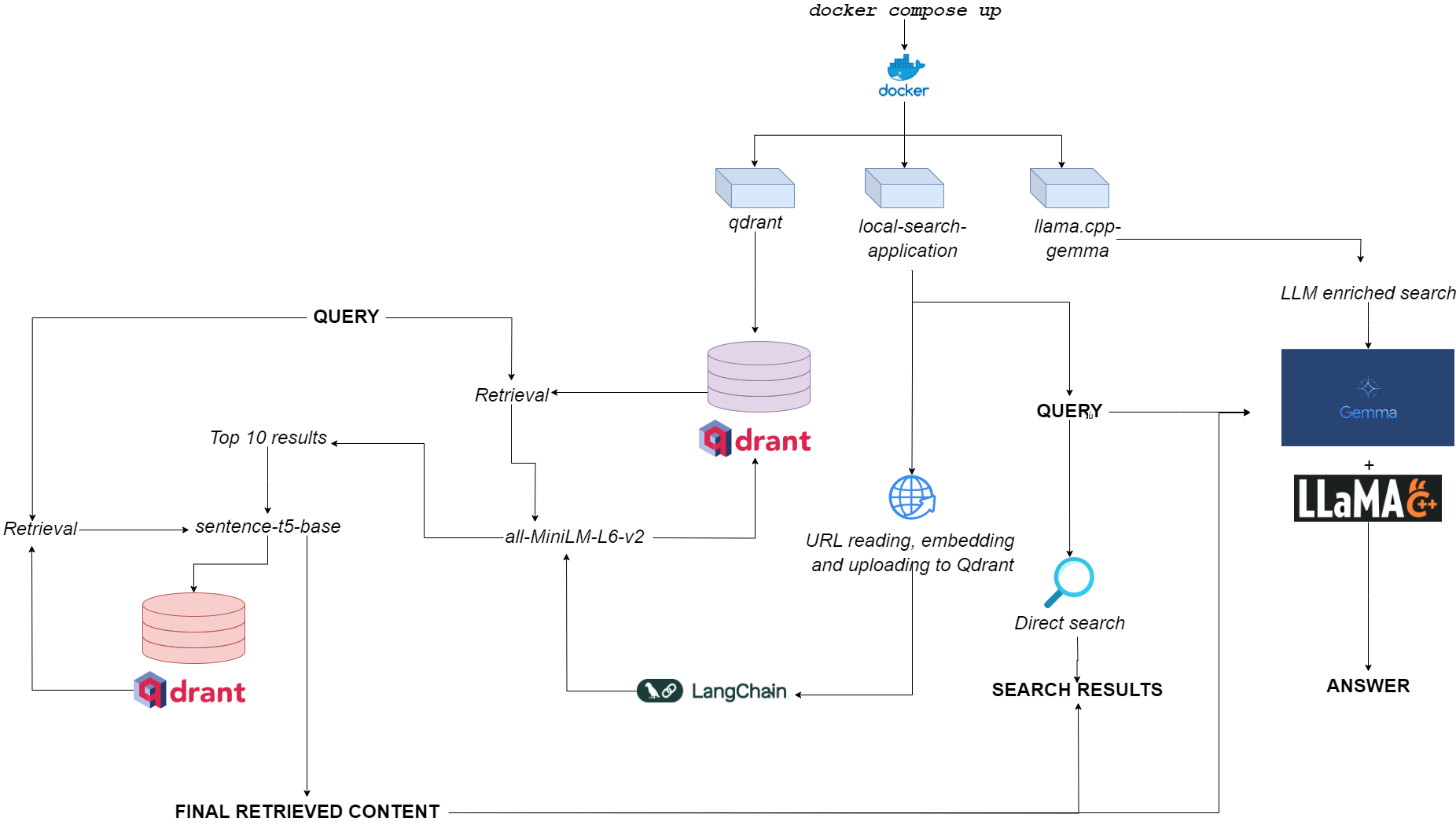
Diagrama de flujo para qdurllm
Qdurllm ( QD Rant Url S y L Arge L Anguege M Odels) es un motor de búsqueda local que le permite seleccionar y cargar contenido de URL a una base de datos vectorial: después de eso, puede buscar, recuperar y chatear con este contenido.
Esto se aprovisiona a través de una aplicación Docker de múltiples contenedores, aprovechando Qdrant, Langchain, Llama.cpp, cuantificada Gemma y Gradio.
¿Dirígete al espacio de demostración en Huggingface?
El único requisito es tener docker y docker-compose .
Si no los tiene, asegúrese de instalarlos aquí.
Puede instalar la aplicación clonando el repositorio de GitHub
git clone https://github.com/AstraBert/qdurllm.git
cd qdurllm O simplemente puede pegar el siguiente texto en un archivo compose.yaml :
networks :
mynet :
driver : bridge
services :
local-search-application :
image : astrabert/local-search-application
networks :
- mynet
ports :
- " 7860:7860 "
qdrant :
image : qdrant/qdrant
ports :
- " 6333:6333 "
volumes :
- " ./qdrant_storage:/qdrant/storage "
networks :
- mynet
llama_server :
image : astrabert/llama.cpp-gemma
ports :
- " 8000:8000 "
networks :
- mynetColocar el archivo en cualquier directorio que desee en su sistema de archivos.
Antes de ejecutar la aplicación, opcionalmente puede extraer todas las imágenes necesarias de Docker Hub:
docker pull qdrant/qdrant
docker pull astrabert/llama.cpp-gemma
docker pull astrabert/local-search-applicationCuando se lanza (ver uso), la aplicación ejecuta tres contenedores:
qdrant (Puerto 6333): Sirve como proveedor de bases de datos vectoriales para la recuperación semántica basada en la búsquedallama.cpp-gemma (puerto 8000): Esta es una implementación de un modelo de Gemma cuantificado proporcionado por LMStudio y Google, servido con el servidor llama.cpp . Esto funciona para ámbitos de generación de texto, enriqueciendo la experiencia de búsqueda del usuario.local-search-application (puerto 7860): una interfaz con pestañas de Gradio con:llama.cpp-gemmaall-MiniLM-L6-v2 (que identifica las 10 mejores coincidencias) y sentence-t5-base (que vuelve a codificar las 10 mejores coincidencias y extrae el mejor golpe de ellos). Esta es la misma implementación de trapo utilizada en combinación con llama.cpp-gemma . ¿Quieres ver cómo funciona el trapo de doble capa en comparación con el trapo de una sola capa? ¡Dirígete aquí!La carga computacional general es lo suficientemente ligera como para que la aplicación se ejecute no solo Gpuless, sino también con baja disponibilidad de RAM (> = 8GB, aunque Gemma puede tardar hasta 10 minutos en responder en 8 GB de RAM).
Puede hacer que la aplicación funcione con el siguiente comando, realmente simple, que debe ejecutarse dentro del mismo directorio donde almacenó su archivo compose.yaml :
docker compose up -d Si ya ha extraído todas las imágenes, encontrará que la aplicación se ejecuta en http://localhost:7860 o http://0.0.0.0:7860 en menos de un minuto.
Si no ha extraído las imágenes, tendrá que esperar que su instalación esté completa antes de usar la aplicación.
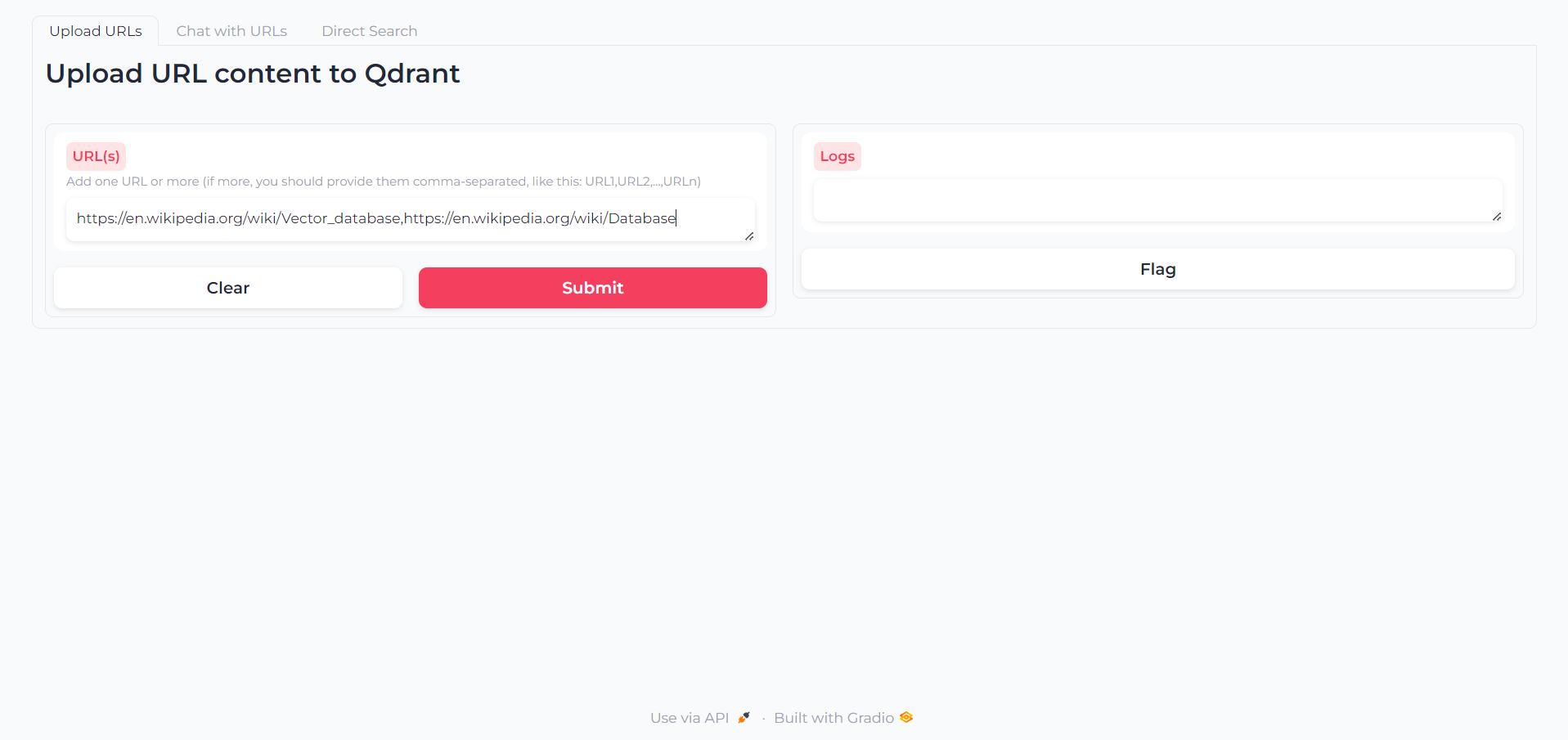
Una vez que se cargue la aplicación, encontrará una primera pestaña en la que puede escribir las URL cuyo contenido desea interactuar:
Ahora que sus URL están cargadas, puede chatear con su contenido a través de llama.cpp-gemma :
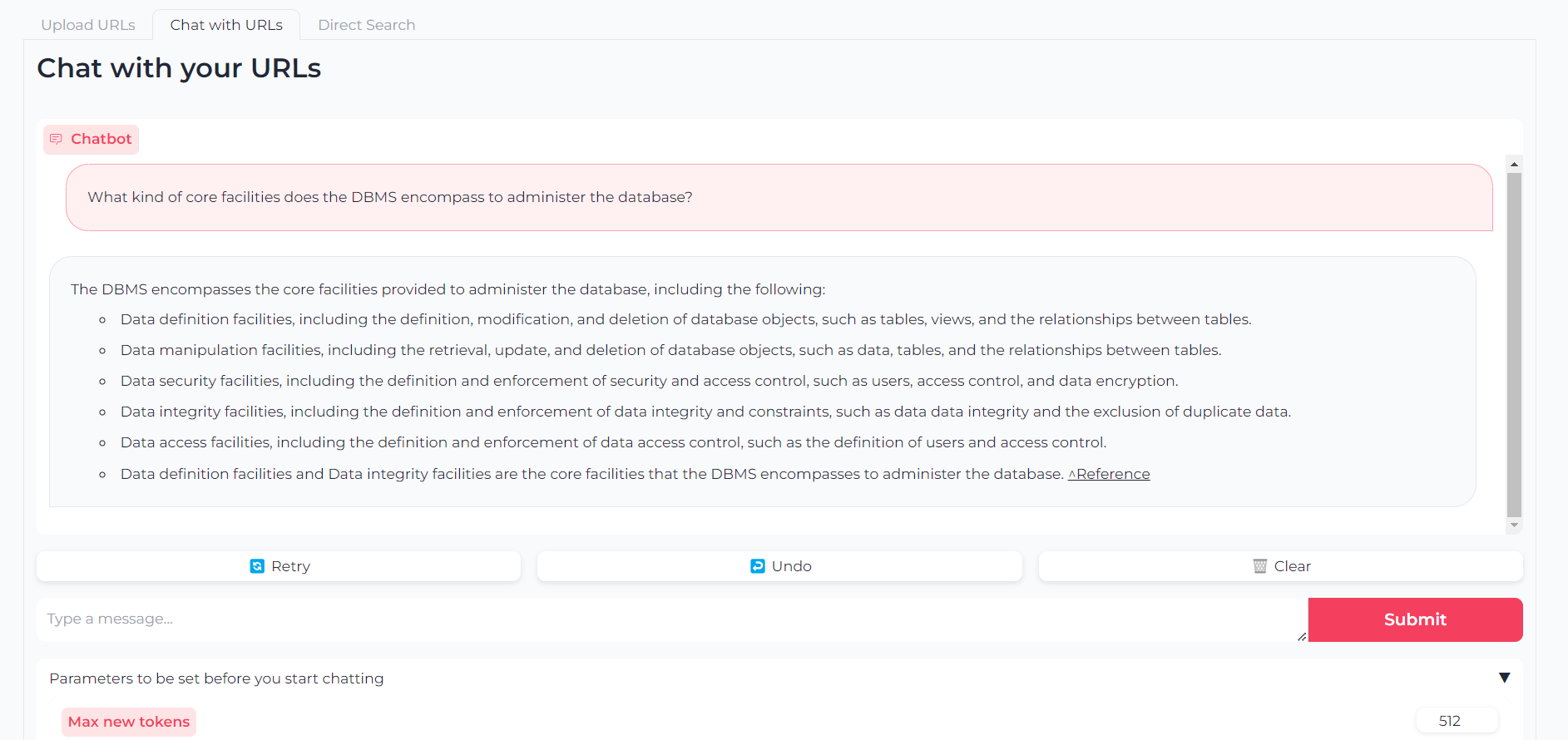
Tenga en cuenta que también puede establecer parámetros como tokens de salida máximos, temperatura, penalización de repetición y semilla de generación
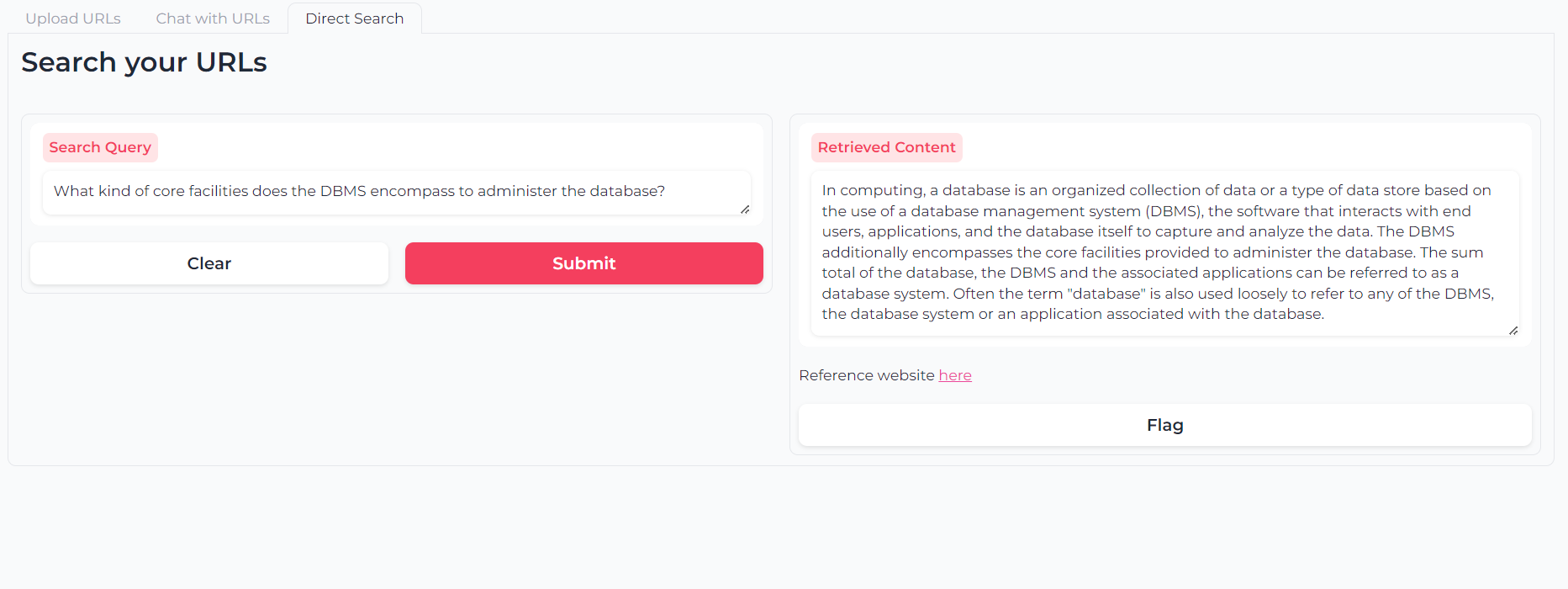
O puede usar la búsqueda semántica de retrieval de doble capa para consultar directamente sus contenidos de URL:
El software es (y siempre será) de código abierto, proporcionado bajo la licencia MIT.
Cualquiera puede usar, modificar y redistribuir cualquier parte de ella, siempre y cuando sea citada el autor, Astra Clelia Bertelli.
¡La contribución siempre es más que bienvenida! Siéntase libre de marcar los problemas, abrir PRS o comuníquese con el autor para sugerir cualquier cambio, solicitud de solicitud o mejorar el código.
Si encontró útil la aplicación, considere financiarla para permitir mejoras.


