qdurllm
v0.0.0?
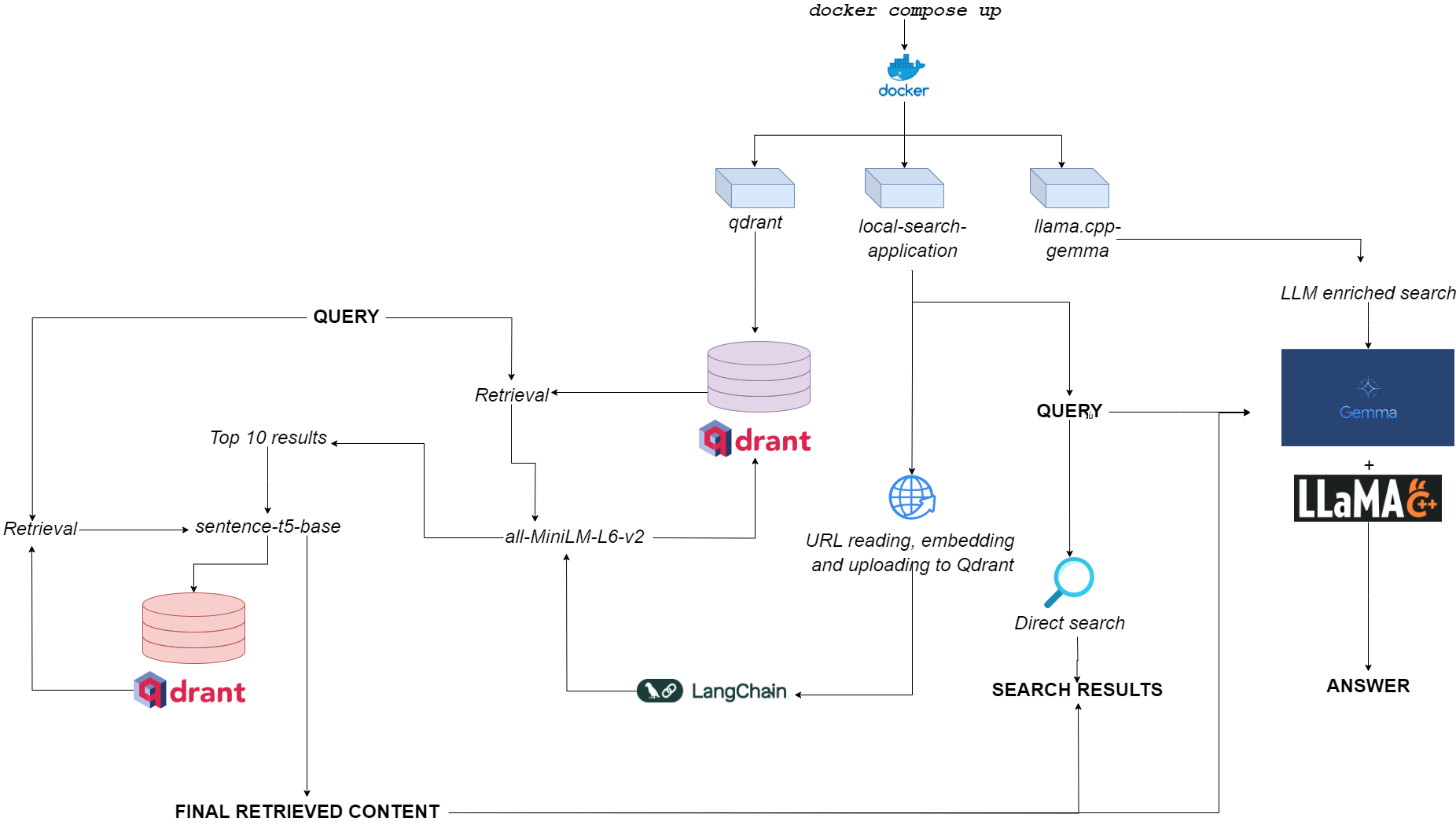
Fluxograma para Qdurllm
QDURLLM ( URL RANT QD S e LA ARGE L ANGIAGEM MODELS ) é um mecanismo de pesquisa local que permite selecionar e fazer upload do conteúdo da URL para um banco de dados vetorial: depois disso, você pode pesquisar, recuperar e conversar com esse conteúdo.
Isso é provisionado por meio de uma aplicação de docker multi-container, alavancando QDRANT, Langchain, LLAMA.CPP, Quantized Gemma e Gradio.
Vá para o espaço de demonstração no Huggingface?
O único requisito é ter docker e docker-compose .
Se você não os tiver, certifique -se de instalá -los aqui.
Você pode instalar o aplicativo clonando o repositório do GitHub
git clone https://github.com/AstraBert/qdurllm.git
cd qdurllm Ou você pode simplesmente colar o seguinte texto em um arquivo compose.yaml :
networks :
mynet :
driver : bridge
services :
local-search-application :
image : astrabert/local-search-application
networks :
- mynet
ports :
- " 7860:7860 "
qdrant :
image : qdrant/qdrant
ports :
- " 6333:6333 "
volumes :
- " ./qdrant_storage:/qdrant/storage "
networks :
- mynet
llama_server :
image : astrabert/llama.cpp-gemma
ports :
- " 8000:8000 "
networks :
- mynetColocando o arquivo em qualquer diretório que desejar no seu sistema de arquivos.
Antes de executar o aplicativo, você pode opcionalmente puxar todas as imagens necessárias do Docker Hub:
docker pull qdrant/qdrant
docker pull astrabert/llama.cpp-gemma
docker pull astrabert/local-search-applicationQuando lançado (consulte o uso), o aplicativo executa três contêineres:
qdrant (PORT 6333): Serve como provedor de banco de dados vetorial para recuperação semântica baseada em buscallama.cpp-gemma (porta 8000): Esta é uma implementação de um modelo GEMMA quantizado fornecido pelo LMStudio e Google, servido com o servidor llama.cpp . Isso funciona para escopos de geração de texto, enriquecendo a experiência de pesquisa do usuário.local-search-application (porta 7860): Uma interface com guias Gradio com:llama.cpp-gemmaall-MiniLM-L6-v2 (que identifica as 10 melhores correspondências) e sentence-t5-base (que reencodifica as 10 melhores correspondências e extrai o melhor sucesso deles)-esta é a mesma implementação de pano usada em combinação com llama.cpp-gemma . Quer ver como o pano de camada dupla se apresenta em comparação com o pano de camada única? Vá aqui!A carga computacional geral é leve o suficiente para fazer com que o aplicativo seja executado não apenas GPULESS, mas também com baixa disponibilidade de RAM (> = 8 GB, embora possa levar até 10 minutos para que Gemma responda em 8 GB de RAM).
Você pode fazer com que o aplicativo funcione com o seguinte - comando realmente simples -, que deve ser executado no mesmo diretório em que você armazenou seu arquivo compose.yaml :
docker compose up -d Se você já retirou todas as imagens, encontrará o aplicativo em execução em http://localhost:7860 ou http://0.0.0.0:7860 em menos de um minuto.
Se você não puxou as imagens, terá que esperar que a instalação deles esteja concluída antes de realmente usar o aplicativo.
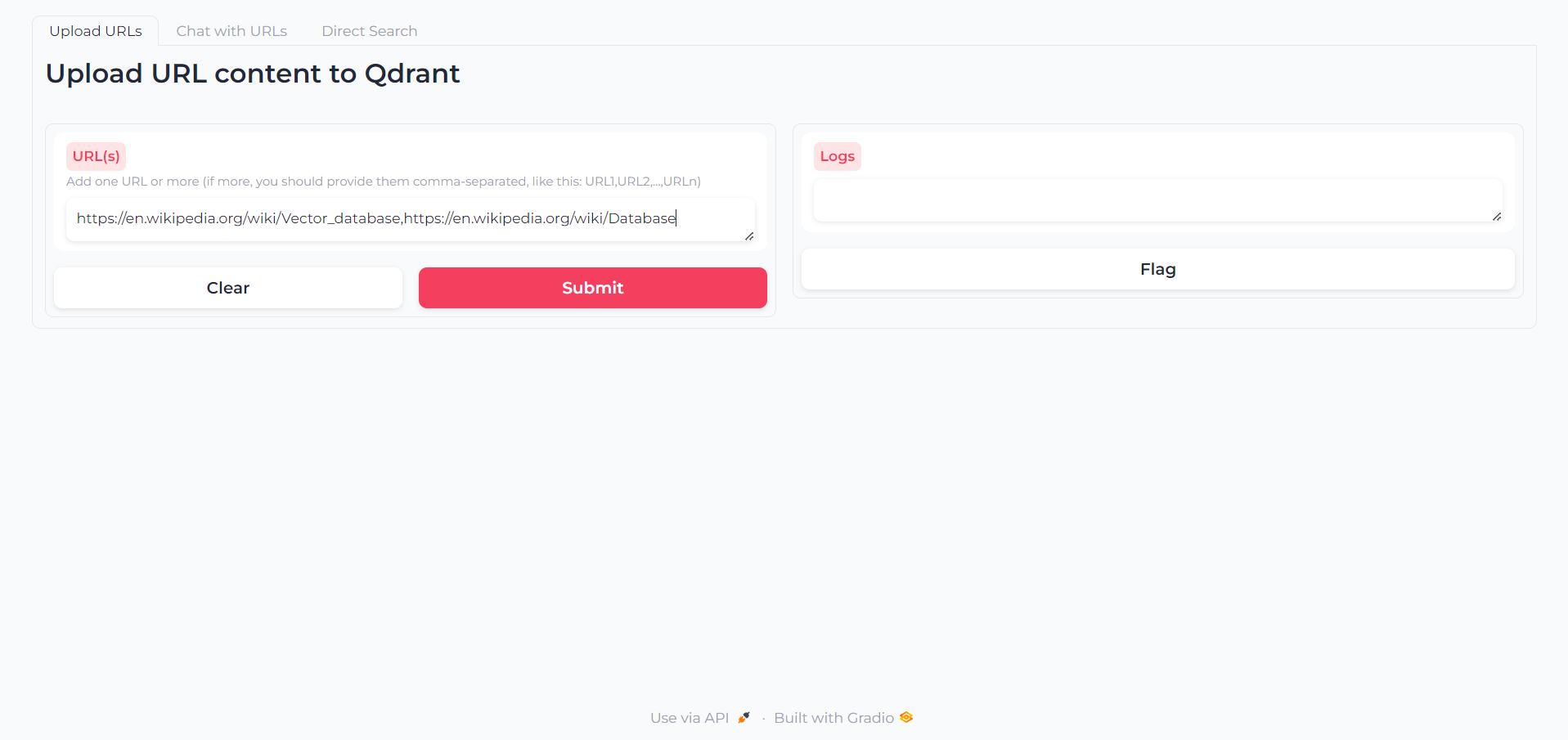
Depois que o aplicativo for carregado, você encontrará uma primeira guia na qual você pode escrever os URLs cujo conteúdo deseja interagir:
Agora que seus URLs são enviados, você pode conversar com o conteúdo deles através do llama.cpp-gemma :
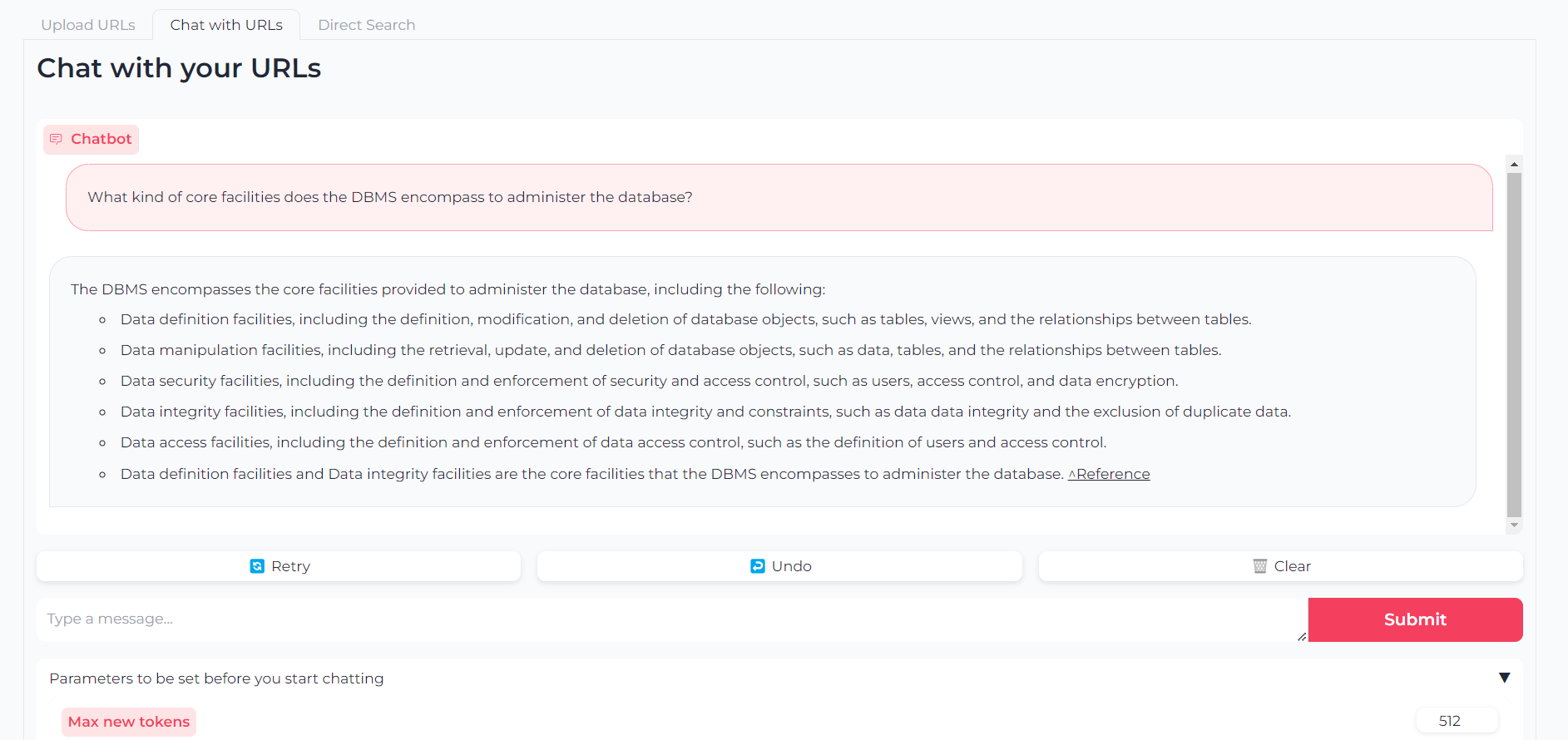
Observe que você também pode definir parâmetros como tokens de saída máxima, temperatura, penalidade de repetição e semente de geração
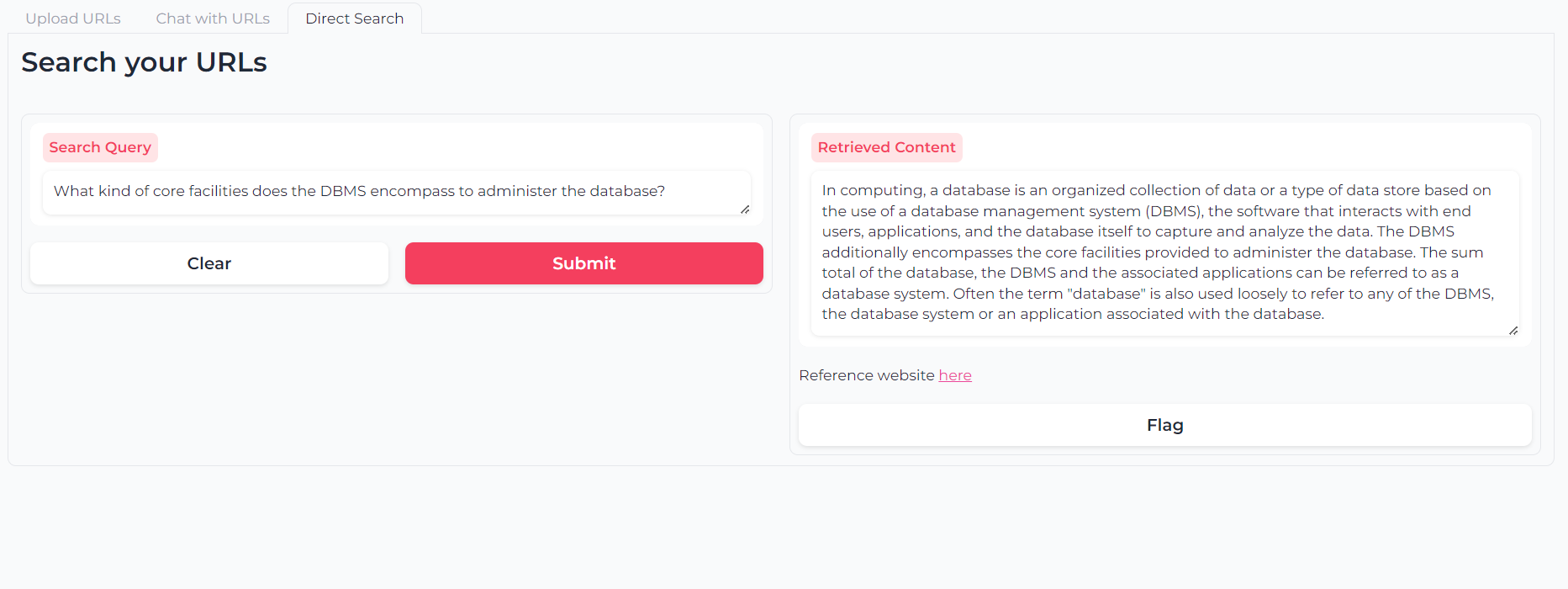
Ou você pode usar a pesquisa semântica de camada de duas camadas para consultar seu conteúdo (s) de URL diretamente:
O software é (e sempre será) de código aberto, fornecido sob licença do MIT.
Qualquer pessoa pode usar, modificar e redistribuir qualquer parte dele, desde que o autor, Astra Clelia Bertelli seja citado.
A contribuição é sempre mais do que bem -vinda! Sinta -se à vontade para sinalizar problemas, abrir PRs ou entrar em contato com o autor para sugerir alterações, solicitar recursos ou melhorar o código.
Se você achou o aplicativo útil, considere financiá -lo para permitir melhorias!


