qdurllm
v0.0.0?
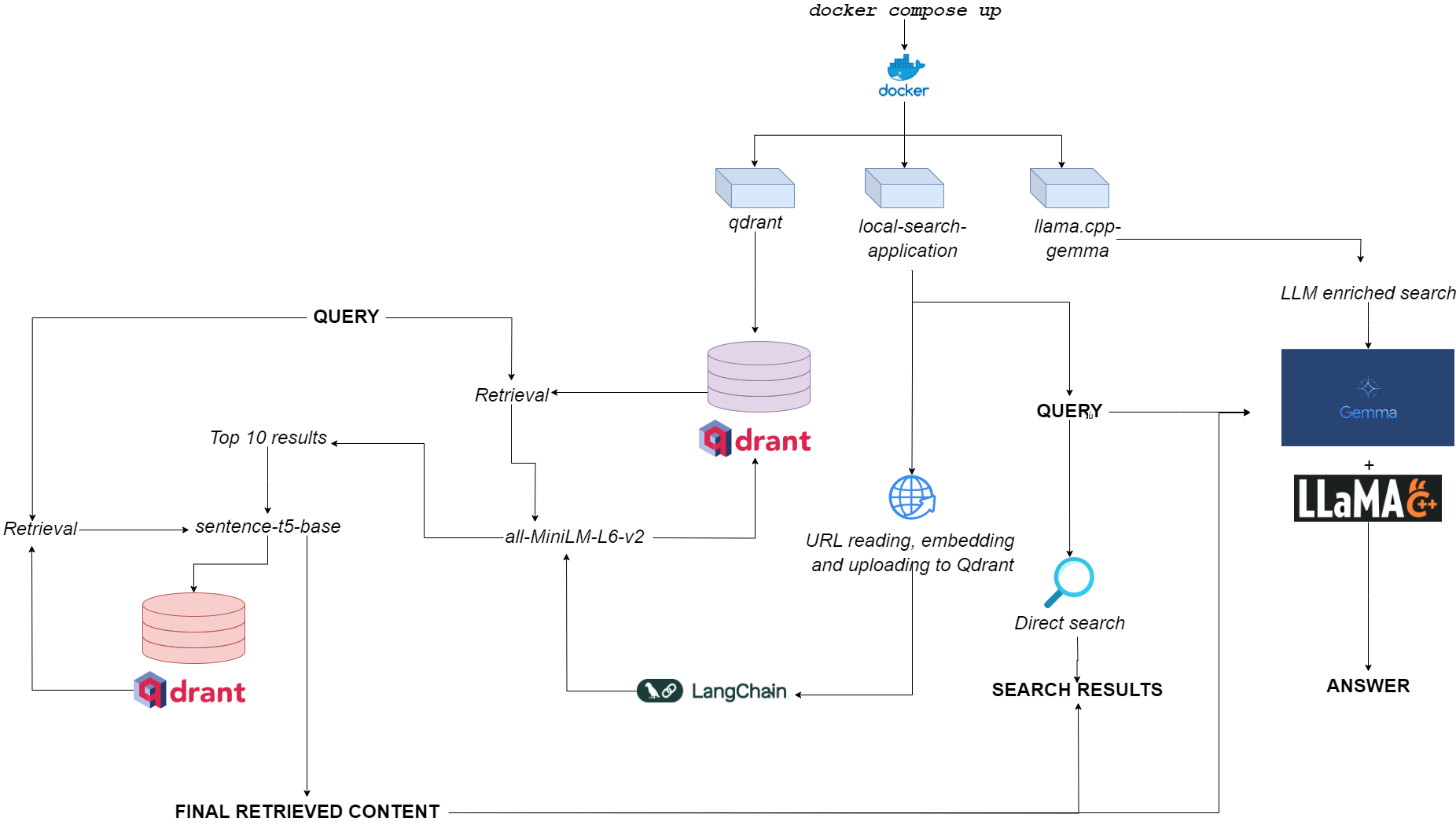
Flowchart untuk qdurllm
Qdurllm ( QD Rant URL S dan L arge l Anguage m odels) adalah mesin pencari lokal yang memungkinkan Anda memilih dan mengunggah konten URL ke database vektor: setelah itu, Anda dapat mencari, mengambil, dan mengobrol dengan konten ini.
Ini disediakan melalui aplikasi Multi-Container Docker, memanfaatkan Qdrant, Langchain, Llama.cpp, Gemma dan Gradio terkuantisasi.
Pergilah ke ruang demo di Huggingface?
Satu-satunya persyaratan adalah memiliki docker dan docker-compose .
Jika Anda tidak memilikinya, pastikan untuk menginstalnya di sini.
Anda dapat menginstal aplikasi dengan mengkloning repositori github
git clone https://github.com/AstraBert/qdurllm.git
cd qdurllm Atau Anda dapat menempelkan teks berikut ke dalam file compose.yaml :
networks :
mynet :
driver : bridge
services :
local-search-application :
image : astrabert/local-search-application
networks :
- mynet
ports :
- " 7860:7860 "
qdrant :
image : qdrant/qdrant
ports :
- " 6333:6333 "
volumes :
- " ./qdrant_storage:/qdrant/storage "
networks :
- mynet
llama_server :
image : astrabert/llama.cpp-gemma
ports :
- " 8000:8000 "
networks :
- mynetMenempatkan file di direktori apa pun yang Anda inginkan di sistem file Anda.
Sebelum menjalankan aplikasi, Anda dapat secara opsional menarik semua gambar yang diperlukan dari Docker Hub:
docker pull qdrant/qdrant
docker pull astrabert/llama.cpp-gemma
docker pull astrabert/local-search-applicationSaat diluncurkan (lihat Penggunaan), aplikasi menjalankan tiga kontainer:
qdrant (port 6333): berfungsi sebagai penyedia database vektor untuk pengambilan berbasis pencarian semantikllama.cpp-gemma (port 8000): Ini adalah implementasi model GEMMA terkuantisasi yang disediakan oleh LMStudio dan Google, disajikan dengan server llama.cpp . Ini berfungsi untuk lingkup generasi teks, memperkaya pengalaman pencarian pengguna.local-search-application (port 7860): Antarmuka tab gradio dengan:llama.cpp-gemmaall-MiniLM-L6-v2 (yang mengidentifikasi 10 pertandingan terbaik) dan sentence-t5-base (yang mengukur ulang 10 pertandingan terbaik dan mengekstraksi hit terbaik dari mereka)-ini adalah implementasi RAG yang sama yang digunakan dalam kombinasi dengan llama.cpp-gemma . Ingin melihat bagaimana kinerja lap berlapis ganda dibandingkan dengan lap berlapis tunggal? Pergilah ke sini!Beban komputasi keseluruhan cukup ringan untuk membuat aplikasi berjalan tidak hanya gpuless, tetapi juga dengan ketersediaan RAM rendah (> = 8GB, meskipun dapat memakan waktu hingga 10 menit untuk Gemma untuk merespons pada RAM 8GB).
Anda dapat membuat aplikasi berfungsi dengan perintah berikut - sangat sederhana - yang harus dijalankan dalam direktori yang sama di mana Anda menyimpan file compose.yaml Anda:
docker compose up -d Jika Anda sudah menarik semua gambar, Anda akan menemukan aplikasi yang berjalan di http://localhost:7860 atau http://0.0.0.0:7860 dalam waktu kurang dari satu menit.
Jika Anda belum menarik gambar, Anda harus menunggu bahwa instalasi mereka selesai sebelum benar -benar menggunakan aplikasi.
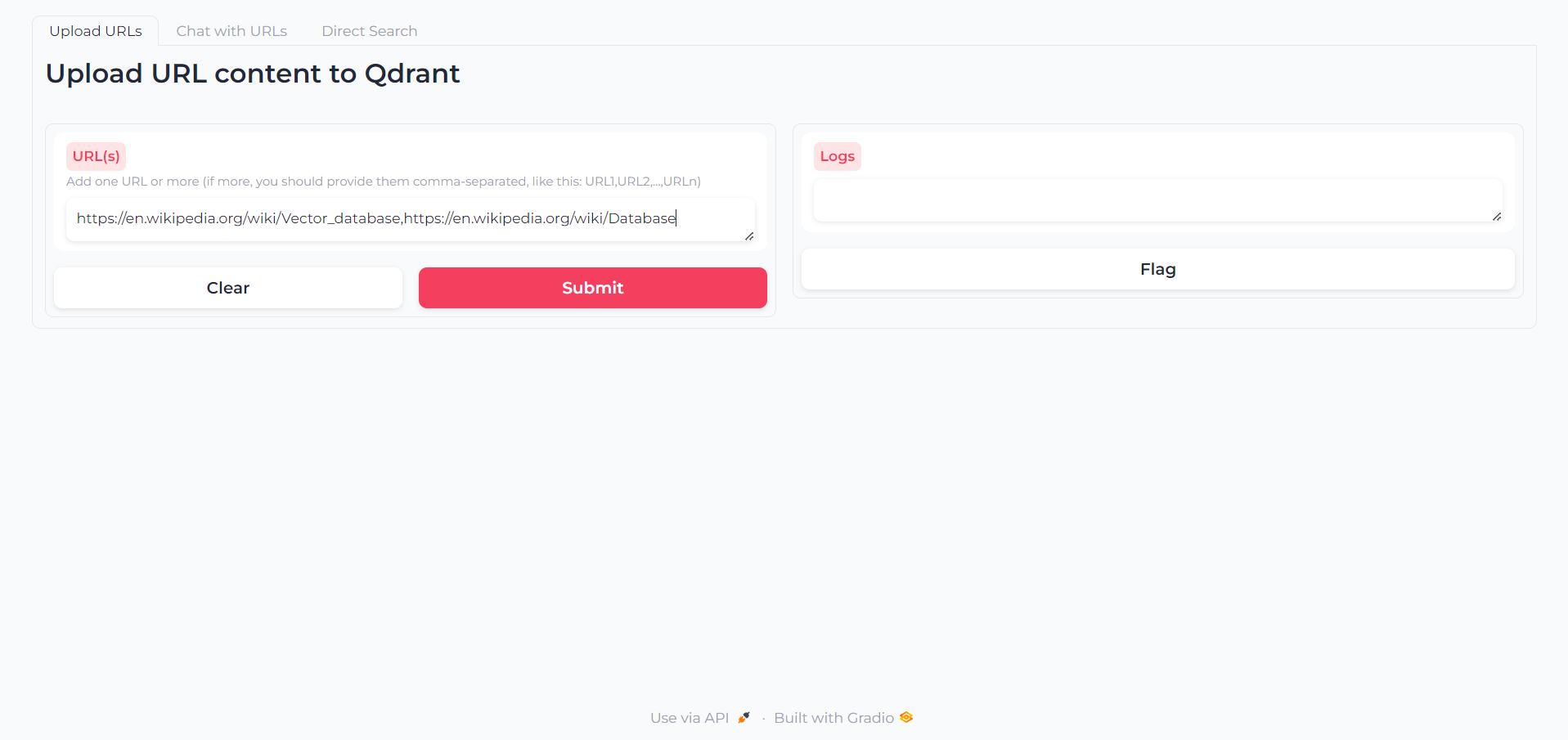
Setelah aplikasi dimuat, Anda akan menemukan tab pertama di mana Anda dapat menulis URL yang kontennya ingin Anda berinteraksi:
Sekarang URL Anda diunggah, Anda dapat mengobrol dengan konten mereka melalui llama.cpp-gemma :
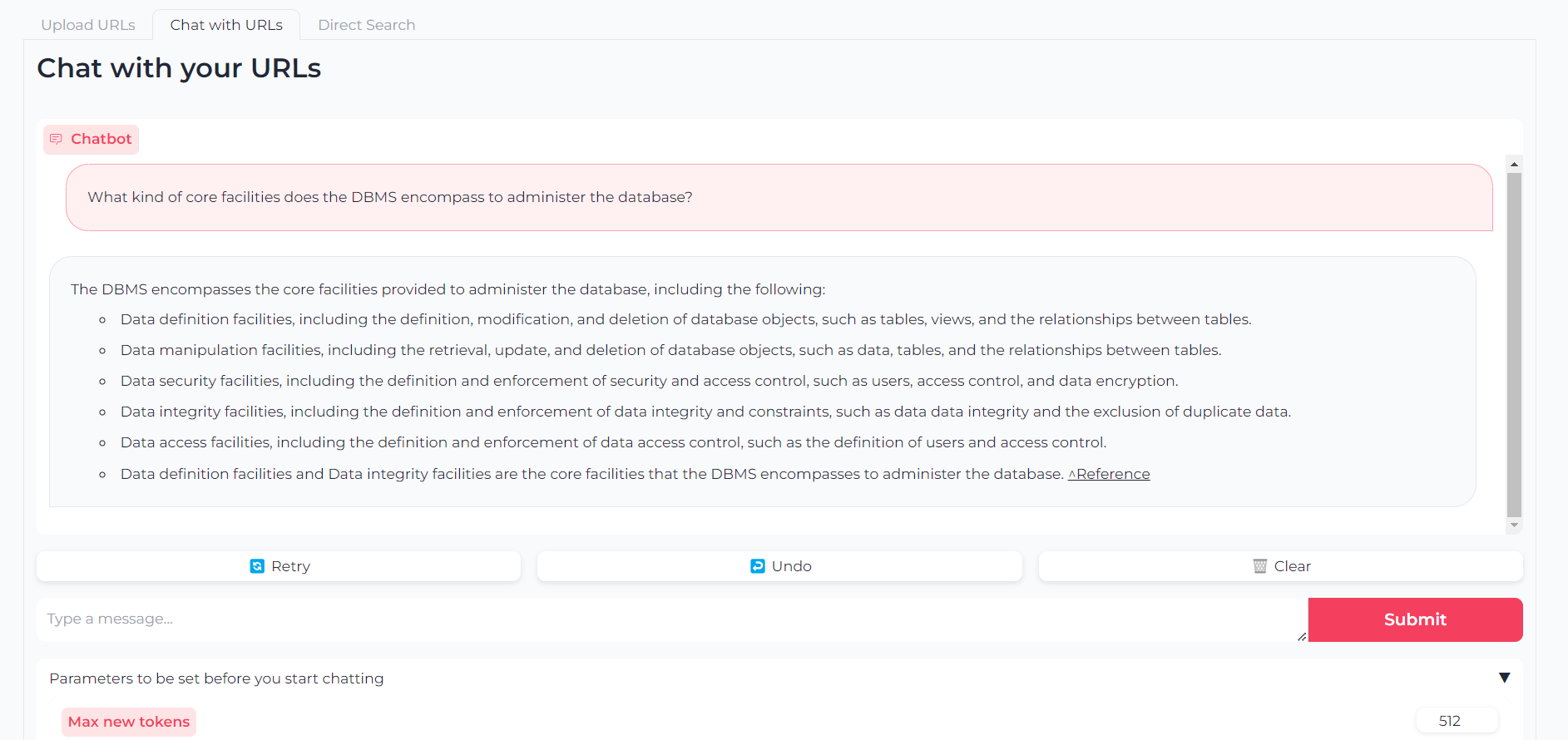
Perhatikan bahwa Anda juga dapat mengatur parameter seperti token output maksimum, suhu, penalti pengulangan dan biji pembangkit
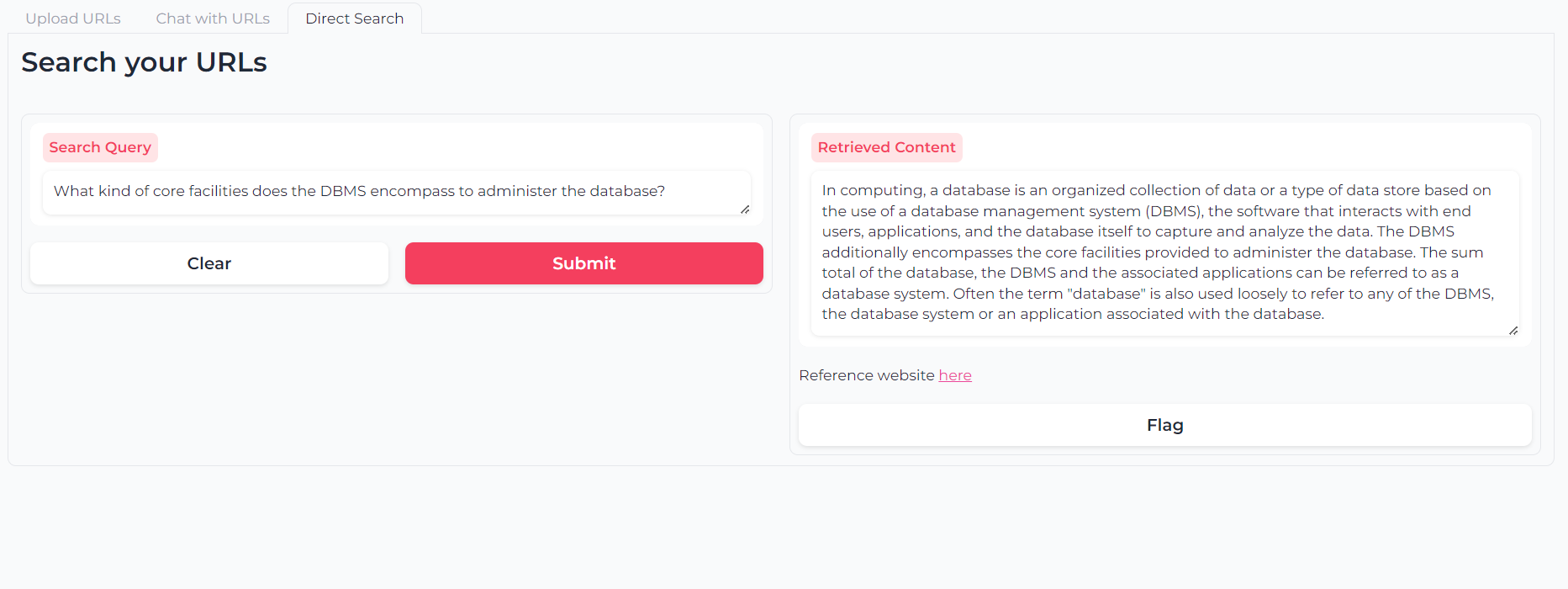
Atau Anda dapat menggunakan pencarian semantik pelapis ganda-retrieval untuk meminta konten URL Anda secara langsung:
Perangkat lunak ini adalah (dan akan selalu) open-source, disediakan di bawah lisensi MIT.
Siapa pun dapat menggunakan, memodifikasi, dan mendistribusikan kembali porsi apa pun, selama penulisnya, Astra Clelia Bertelli dikutip.
Kontribusi selalu lebih dari diterima! Jangan ragu untuk menandai masalah, membuka PR atau menghubungi penulis untuk menyarankan perubahan apa pun, meminta fitur atau meningkatkan kode.
Jika Anda menemukan aplikasi itu berguna, harap pertimbangkan mendanai untuk mengizinkan perbaikan!


