qdurllm
v0.0.0?
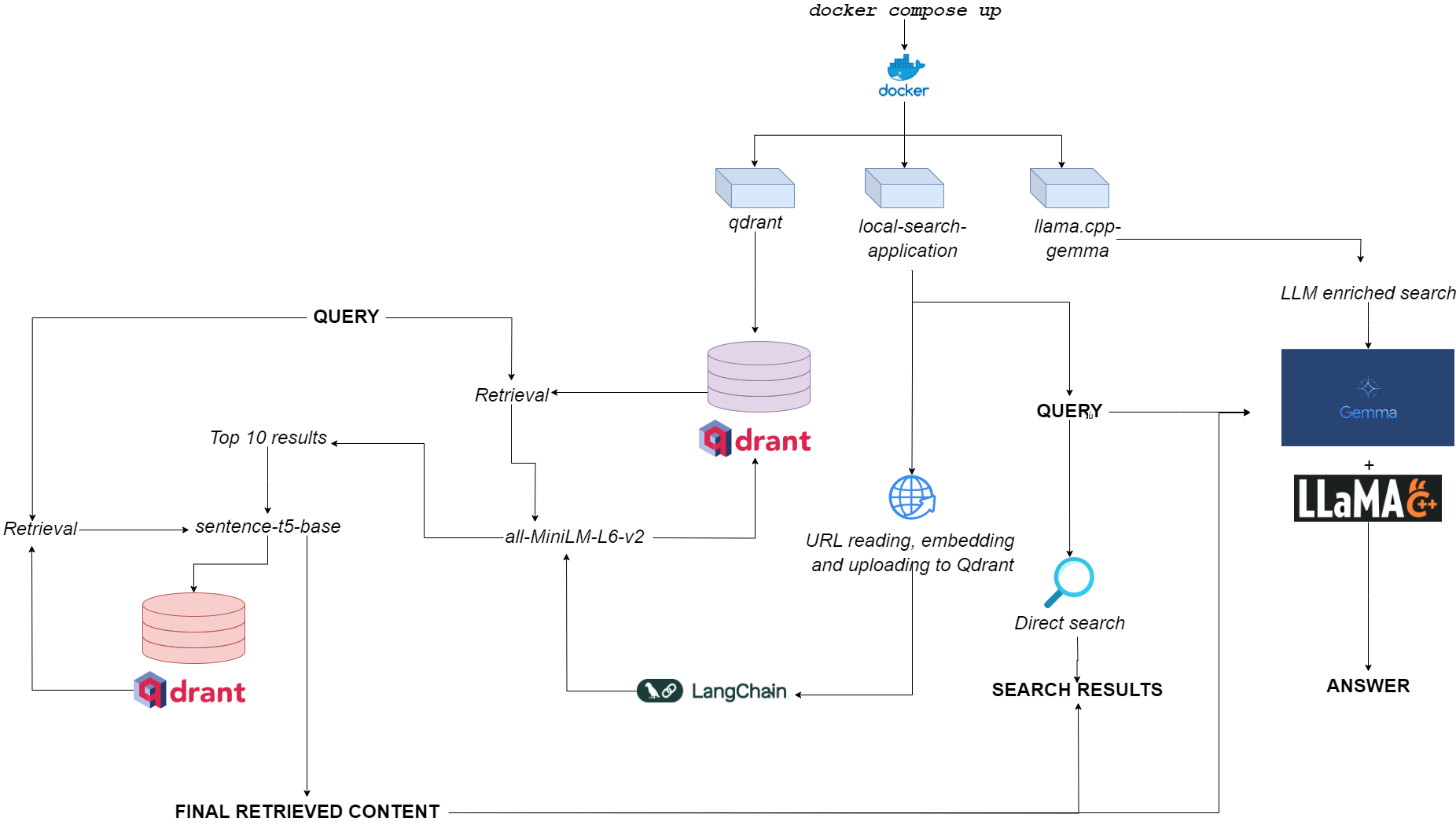
Organigramme pour qdurllm
QDURLLM ( QD RANT URL et L Arge l Anguage M ODELS) est un moteur de recherche local qui vous permet de sélectionner et de télécharger le contenu URL dans une base de données vectorielle: après cela, vous pouvez rechercher, récupérer et discuter avec ce contenu.
Ceci est provisionné via une application Docker multi-container, tirant parti de Qdrant, Langchain, Llama.cpp, Gemma et Gradio quantifiés.
Rendez-vous dans l'espace de démonstration sur HuggingFace?
La seule exigence est d'avoir docker et docker-compose .
Si vous ne les avez pas, assurez-vous de les installer ici.
Vous pouvez installer l'application en clonage le référentiel GitHub
git clone https://github.com/AstraBert/qdurllm.git
cd qdurllm Ou vous pouvez simplement coller le texte suivant dans un fichier compose.yaml :
networks :
mynet :
driver : bridge
services :
local-search-application :
image : astrabert/local-search-application
networks :
- mynet
ports :
- " 7860:7860 "
qdrant :
image : qdrant/qdrant
ports :
- " 6333:6333 "
volumes :
- " ./qdrant_storage:/qdrant/storage "
networks :
- mynet
llama_server :
image : astrabert/llama.cpp-gemma
ports :
- " 8000:8000 "
networks :
- mynetPlacer le fichier dans le répertoire que vous souhaitez dans votre système de fichiers.
Avant d'exécuter l'application, vous pouvez éventuellement retirer toutes les images nécessaires de Docker Hub:
docker pull qdrant/qdrant
docker pull astrabert/llama.cpp-gemma
docker pull astrabert/local-search-applicationLorsqu'il est lancé (voir l'utilisation), l'application exécute trois conteneurs:
qdrant (port 6333): sert de fournisseur de base de données vectorielle pour la récupération basée sur la recherche sémantiquellama.cpp-gemma (Port 8000): Il s'agit d'une implémentation d'un modèle Gemma quantifié fourni par LMStudio et Google, servi avec le serveur llama.cpp . Cela fonctionne pour les lunettes de génération de texte, enrichissant l'expérience de recherche de l'utilisateur.local-search-application (port 7860): une interface à onglet Gradio avec:llama.cpp-gemmaall-MiniLM-L6-v2 (qui identifie les 10 meilleurs matchs) et sentence-t5-base (qui réencode les 10 meilleurs matchs et les extrait le meilleur coup) - il s'agit de la même implémentation de chiffon utilisée en combinaison avec llama.cpp-gemma . Vous voulez voir comment les chiffons à double couche se déroulent par rapport au chiffon à une seule couche? Rendez-vous ici!La charge de calcul globale est suffisamment légère pour faire fonctionner l'application non seulement GPULESS, mais aussi avec une faible disponibilité de RAM (> = 8 Go, bien que cela puisse prendre jusqu'à 10 minutes pour que Gemma réponde sur 8 Go de RAM).
Vous pouvez faire en sorte que l'application fonctionne avec la commande - vraiment simple - vraiment simple, qui doit être exécutée dans le même répertoire où vous avez stocké votre fichier compose.yaml :
docker compose up -d Si vous avez déjà tiré toutes les images, vous trouverez l'application en cours d'exécution sur http://localhost:7860 ou http://0.0.0.0:7860 en moins d'une minute.
Si vous n'avez pas tiré les images, vous devrez attendre que leur installation soit terminée avant d'utiliser l'application.
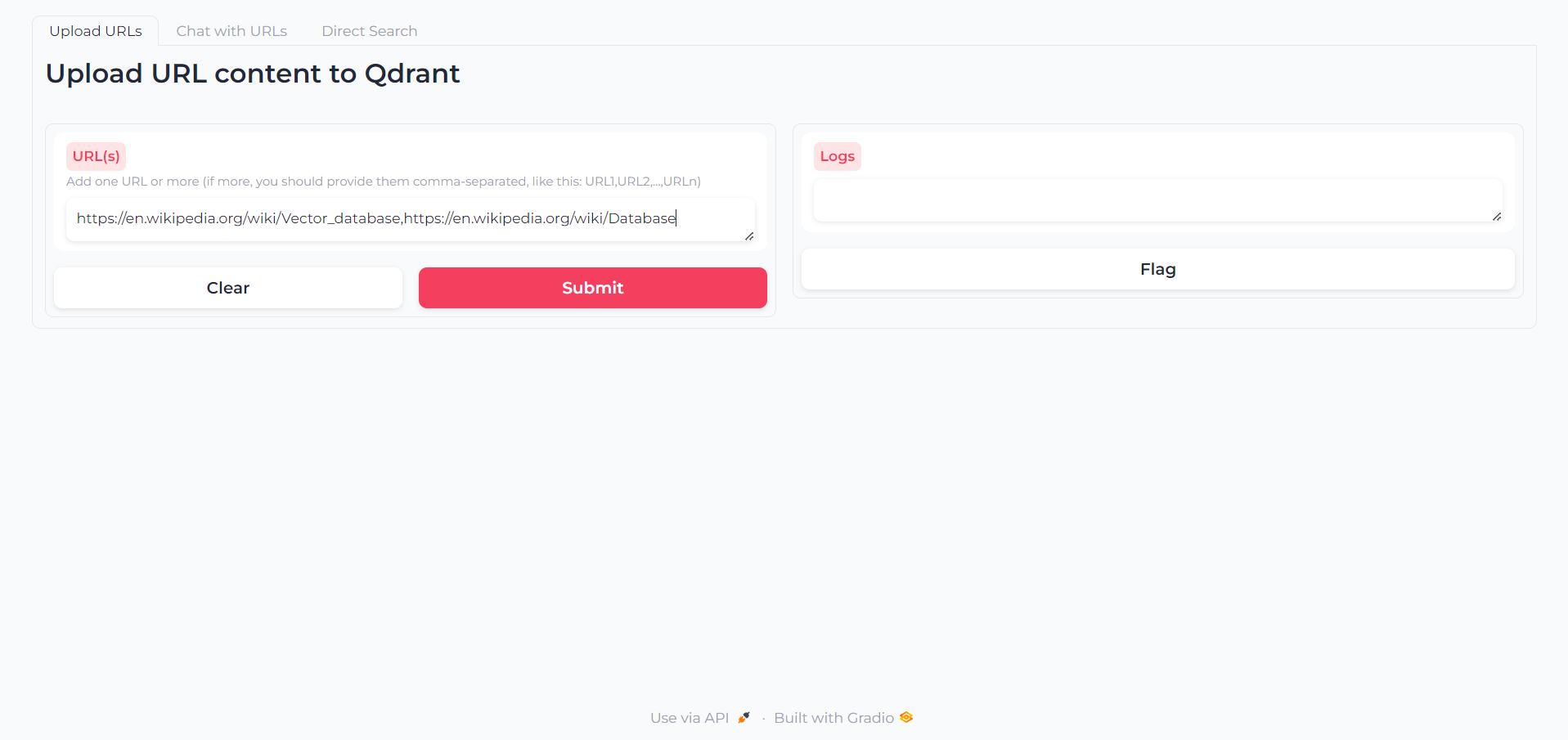
Une fois l'application chargée, vous trouverez un premier onglet dans lequel vous pouvez écrire les URL dont vous souhaitez interagir le contenu:
Maintenant que vos URL sont téléchargées, vous pouvez soit discuter avec leur contenu via llama.cpp-gemma :
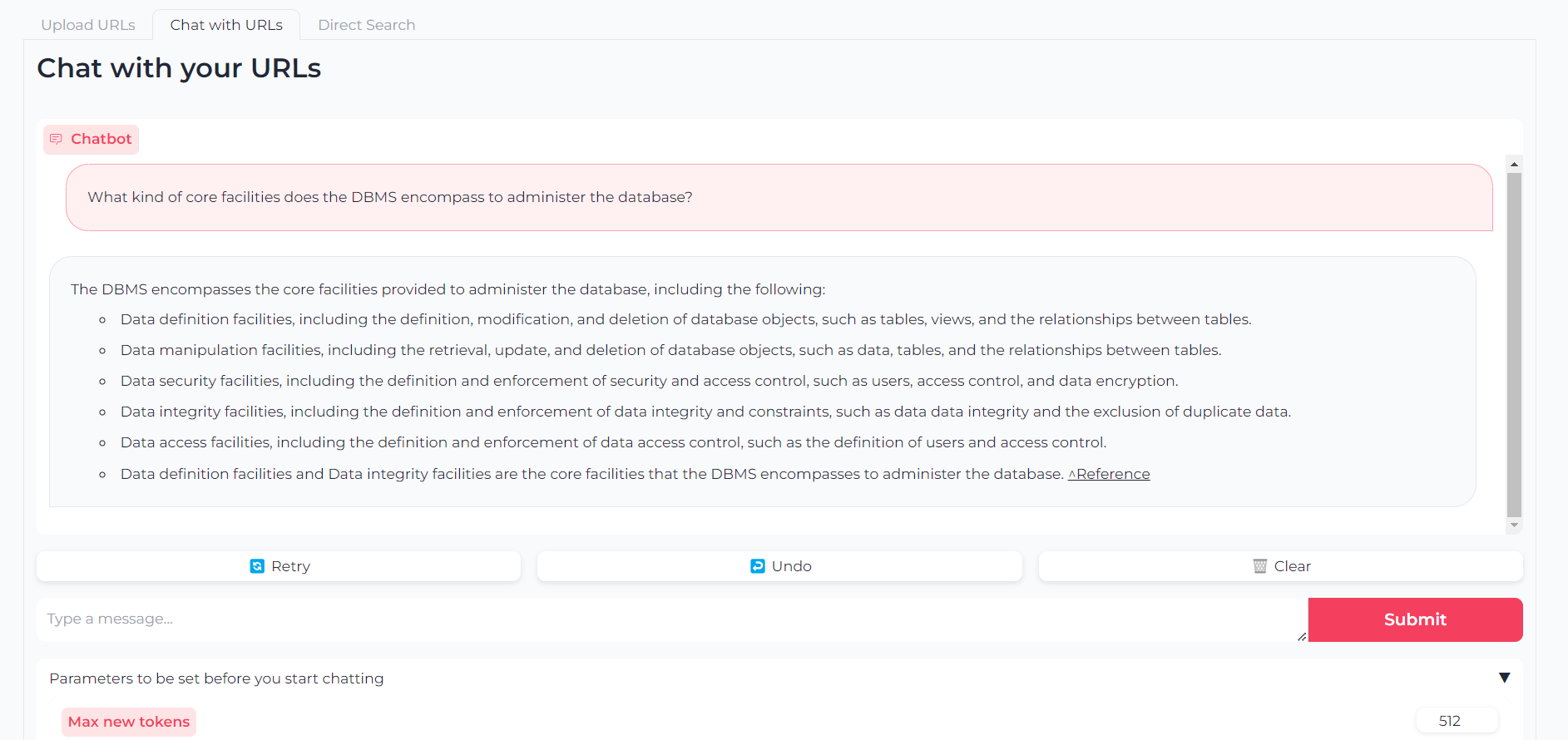
Notez que vous pouvez également définir des paramètres comme les jetons de sortie maximaux, la température, la pénalité de répétition et les graines de génération
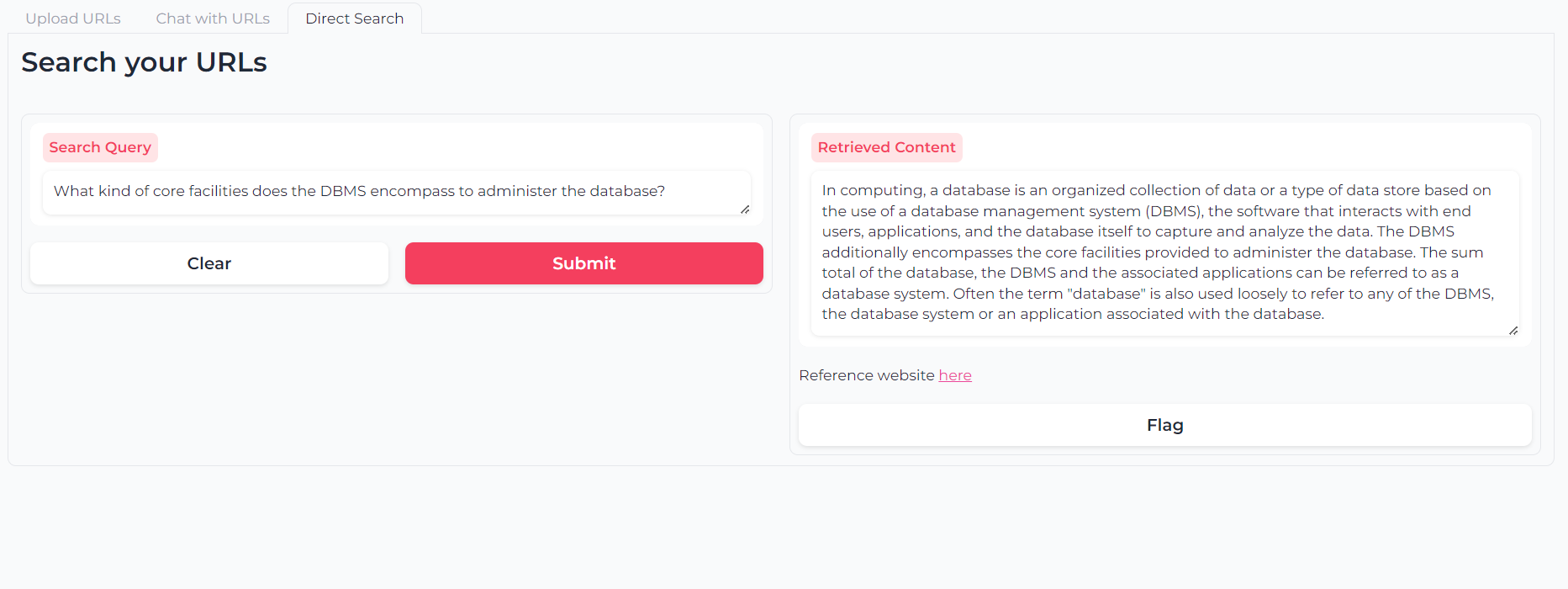
Ou vous pouvez utiliser la recherche sémantique à double couche pour interroger directement vos contenus URL:
Le logiciel est (et sera toujours) open-source, fourni en vertu de la licence MIT.
Tout le monde peut utiliser, modifier et redistribuer n'importe quelle partie de celui-ci, tant que l'auteur, Astra Clelia Bertelli est citée.
La contribution est toujours plus que bienvenue! N'hésitez pas à signaler les problèmes, à ouvrir PRS ou à contacter l'auteur pour suggérer toute modification, demander des fonctionnalités ou améliorer le code.
Si vous avez trouvé la demande utile, veuillez envisager de le financer afin d'autoriser les améliorations!


