Elasticflow (ITA)
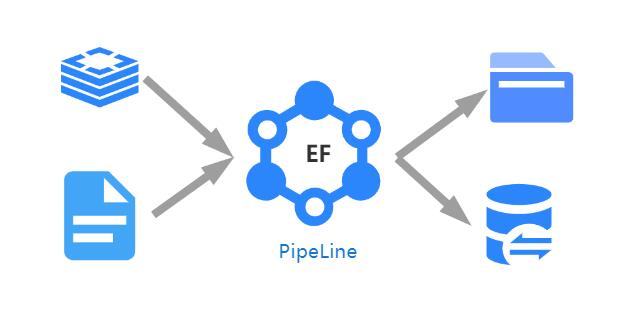
Elasticflow-это система обмена данными данных с открытым исходным кодом, которая поддерживает создание вычислимых конвейеров упругого потока между любым типом данных заканчивается простой конфигурацией, а также выполнение времени, количественного, высокого параллелизма и служб данных обменного обмена. Система может быть применена к обмену данными, общей поисковой системой, службами публикации данных, хранилищам данных и другим проектам.
Что использует Elasticflow для решения?
- В качестве системы обмена данными Elasticflow может записывать данные в целевой конец, а также может поддерживать услуги по вычислению и обработке данных в процессе обмена данными. Во время процесса обмена данными ElasticFlow существуют многоуровневые и многозернистые методы управления, что облегчает отображение полевых полетов между «конец чтения» и «конец записи» данных. Кроме того, система также имеет механизм управления на стороне записи для поддержки механизма синхронного управления многозадачным письмом в том же месте.
- Elasticflow может быть улучшен с помощью распределенной системы (мастер/рабов) или может быть запущен в виде одного узла, где распределенное развертывание будет поддерживать автоматическую балансировку нагрузки на задачу на уровне экземпляра, чтобы обеспечить крупномасштабное строительство задач эластичного потока.
- Может решить проблему:
- Синхронизация данных между различными источниками;
- Данные обрабатываются на стороне расчета (например, обработка вывода моделей домена NLP и CV) на стороне записи, например, доступ к службе потоковой передачи видео;
- Сборка поисковых систем, такие как инкрементальный, полный и индексация по дате;
- Другие сценарии, где между системами требуется управление обменом данными.
Версии
характеристика
- Поддерживает систему работы распределенной или одноклетной режима
- Поддерживает распределенное планирование задач, например, система может автоматически сбалансировать загрузку задач между кластерами
- Поддерживает многоуровневые стратегии одновременного выполнения, такие как параллелизм трубопроводов, параллелизм задач и другие методы для ускорения обработки данных
- Поддерживает работу цепочки задач, а система обеспечивает порядок зависимости от управления операцией между задачами
- Планирование приоритета приоритета поддержки задач с низким приоритетом автоматически уменьшат обработку трубопровода, когда ресурсы недостаточны
- Поддерживает задачи абстрактного уровня, которые управляют задачами.
- Поддерживает интеграцию и вычисления данных, в основном для поддержки доступа к внешним службам для обеспечения обработки выводов данных моделей глубокого обучения
Основные преимущества
- Надежный мониторинг качества данных
- Каждое поле может быть настроено с собственной стратегией преобразования типа данных, чтобы данные могли быть переданы в пункт назначения в полном и без потерь;
- Обеспечить мониторинг времени выполнения в режиме реального времени на чтение домашнего задания, вычисления и письма;
- Эластичный контроль потока
- Задача работает при мониторинге запуска задачи.
- Работа задачи имеет приоритетный контроль, и когда системные ресурсы отсутствуют, «трафик» операции с низким приоритетом будет контролироваться для автоматического уменьшения размера трубопровода;
- Управление расчета данных
- После введения вычислительной терминала система может выполнять услуги расчетов по потоковым данным и может предоставлять вычислительные услуги с выводом через API REST или загружать модели глубокого обучения;
- Вычислительный терминал может автоматически управлять системой, чтобы запустить больше вычислительных служб в соответствии с размером потока и выполнять управление балансировкой нагрузки;
- Сильная производительность синхронизации
- Обработка данных может быть обработана одновременно на нескольких уровнях, таких как трубопроводы и каналы;
- Система поддерживает виртуальные задачи, и для выполнения одной и той же обработки данных можно использовать несколько задач, а виртуальные задачи могут реализовать управление между несколькими задачами;
- Надежный механизм устойчивости к разлому
- Система может автоматически реализовать многоуровневую локальную/глобальную повторную попытку на уровне потоков, уровня процесса и уровня работы, чтобы обеспечить стабильную работу задач;
- Система выключается и использует режим мягкого выключения, который автоматически выполняет безопасную посадку кластерных задач, чтобы предотвратить потерю данных, когда грязные данные вступают в конец и считываются.
Поддержка читателей
- Hbase 1.x
- Kafka
- RocketMQ 4.x
- Mysql
- Oracle
- files (txt,csv)
Компьютерная поддержка
- Rest API (POST/JSON)
- Model
Поддержка писателя
- ElasticSearch 7.x
- Mysql
- Neo4j 3.x
- Vearch
- Hbase 1.x
- Kafka 2.x
Поддержка поиска
- Vearch
- Kafka
- ElasticSearch
Документ
- Обратитесь к вики для подробной документации
- Пример обмена данными ссылка
- Ссылка на установку и развертывание
Интерфейс визуального управления
Изменения
Версия 6.0 имеет новое обновление архитектуры до предыдущей версии, и больше не поддерживает глубокое обучение через Java.
EF плагин разработка
- POM Package:
< dependency >
< groupId >org.elasticflow</ groupId >
< artifactId >elasticflow</ artifactId >
< version >6.0.8</ version >
< scope >system</ scope >
< systemPath >./target/elasticflow.jar</ systemPath >
</ dependency >
- Например, код тестирования разработки плагинов:
@ Before
public void setUp () {
System . setProperty ( "config" , "/work/EF/" );
System . setProperty ( "nodeid" , "1" );
}
@ Test
public void testPlugin () throws Exception {
Run . main ( null );
while ( true ) {
}
} План развития
- Поддержка LLMS для получения дополнительной возможности
- Оптимизировать мониторинг цепочки вызовов.
- 6.x Версия планирование функции.
Ссылаясь на Elasticflow
@article { agtabular ,
title = { ElasticFlow (伊塔):ElasticFlow(伊塔)是一个开源弹性流数据交换系统,支持在任意类型数据端之间通过简单配置就可以建立可计算的弹性流管道,并进行定时、定量、高并发、多类型的交换数据服务。系统可应用于数据交换、通用搜索引擎、数据发布服务、数据仓库等项目。 } ,
author = { chengwen } ,
year = { 2023 }
}