Elastic Flow (ITA)
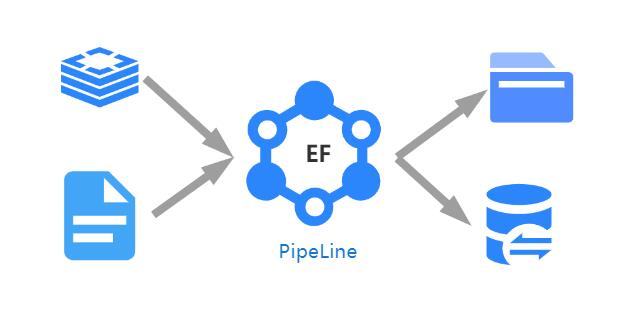
ElasticFlow es un sistema de intercambio de datos de flujo elástico de código abierto que admite el establecimiento de tuberías de flujo elástico computable entre cualquier tipo de datos de datos a través de la configuración simple y realiza el tiempo, cuantitativa, alta concurrencia y servicios de datos de intercambio de tipo múltiple. El sistema se puede aplicar al intercambio de datos, el motor de búsqueda general, los servicios de publicación de datos, los almacenes de datos y otros proyectos.
¿Qué usa ElasticFlow para resolver?
- Como sistema de intercambio de datos, ElasticFlow puede escribir datos hasta el final de destino y también puede admitir servicios de computación y procesamiento de datos durante el proceso de intercambio de datos. Existen métodos de control de nivel múltiple y múltiples durante el proceso de intercambio de datos ElasticFlow, que facilita el mapeo de campo entre el "extremo de lectura" y el "extremo de escritura" de los datos. Además, el sistema también tiene un mecanismo de control del lado de escritura para apoyar el mecanismo de control sincrónico de la escritura de varias tareas al mismo lugar.
- ElasticFlow se puede mejorar con un sistema distribuido (maestro/esclavo) o se puede ejecutar como un solo nodo, donde la implementación distribuida admitirá el equilibrio automático de carga de tareas en el nivel de instancia para habilitar la construcción de tareas de flujo elástico a gran escala.
- Puede resolver el problema:
- Sincronización de datos entre diferentes fuentes;
- Los datos se procesan en el lado del cálculo (como el procesamiento de inferencia de los modelos de dominio NLP y CV) en el lado objetivo de escritura, como el acceso al servicio de transmisión de video;
- Construir servicios de motor de búsqueda, como incremental, completo e indexación por fecha;
- Otros escenarios en los que se requiere control de intercambio de datos entre los sistemas.
Versiones
característica
- Admite sistema de operación de modo distribuido o de nodo único
- Admite la programación de tareas distribuidas, como el sistema puede realizar automáticamente el equilibrio de carga de tareas entre clústeres
- Admite estrategias de ejecución concurrentes de varios niveles, como la concurrencia de la tubería, la concurrencia de la tarea y otros métodos para acelerar el procesamiento de datos
- Admite la operación de la cadena de tareas, y el sistema proporciona orden de dependencia del control de operación entre tareas
- La programación de prioridad de la tarea de soporte, las tareas de baja prioridad reducirán automáticamente la tubería de procesamiento cuando los recursos son insuficientes
- Admite tareas de nivel abstracto que controlan las tareas.
- Admite la integración y la computación de datos, principalmente para admitir el acceso a servicios externos para proporcionar un procesamiento de inferencia de datos de modelos de aprendizaje profundo
Ventajas del núcleo
- Monitoreo de calidad de datos confiable
- Cada campo se puede configurar con su propia estrategia de conversión de tipo de datos para que los datos puedan transmitirse al destino en su totalidad y sin pérdidas;
- Proporcione monitoreo en tiempo de ejecución en tiempo real de la lectura de la tarea, la computación y la escritura;
- Control de flujo elástico
- La tarea se ejecuta cuando se ejecuta la tarea.
- La operación de la tarea tiene control de prioridad, y cuando faltan los recursos del sistema, el "tráfico" de la operación de baja prioridad se controlará para reducir automáticamente el tamaño de la tubería;
- Control de cálculo de datos
- Después de introducir el terminal de computación, el sistema puede realizar servicios de cálculo en los datos de transmisión y puede proporcionar servicios informáticos de inferencia a través de la API REST o la carga de modelos de aprendizaje profundo;
- El terminal informático puede controlar automáticamente el sistema para iniciar más servicios informáticos de acuerdo con el tamaño del flujo y realizar la gestión de equilibrio de carga;
- Fuerte rendimiento de sincronización
- El procesamiento de datos se puede procesar simultáneamente en múltiples niveles, como tuberías y canales;
- El sistema admite tareas virtuales, y se pueden usar múltiples tareas para completar el mismo procesamiento de datos, y las tareas virtuales pueden realizar el control entre múltiples tareas;
- Mecanismo de tolerancia a fallas robusto
- El sistema puede implementar automáticamente el reintento local/global de niveles en el nivel de hilo, el nivel de proceso y el nivel de trabajo para garantizar el funcionamiento estable de las tareas;
- El sistema está apagado y utiliza el modo de apagado suave, que realizará automáticamente el aterrizaje seguro de las tareas de clúster para evitar la pérdida de datos cuando los datos sucios ingresan al final y se lee.
Soporte de lector
- Hbase 1.x
- Kafka
- RocketMQ 4.x
- Mysql
- Oracle
- files (txt,csv)
Soporte informático
- Rest API (POST/JSON)
- Model
Apoyo para el escritor
- ElasticSearch 7.x
- Mysql
- Neo4j 3.x
- Vearch
- Hbase 1.x
- Kafka 2.x
Soporte del buscador
- Vearch
- Kafka
- ElasticSearch
Documento
- Consulte el wiki para una documentación detallada
- Referencia de ejemplo de intercambio de datos
- Referencia de instalación e implementación
Interfaz de gestión visual
Cambios
La versión 6.0 tiene una nueva actualización de arquitectura a la versión anterior, y ya no admite el aprendizaje profundo de forma nativa a través de Java.
Desarrollo de complemento EF
- Paquete POM:
< dependency >
< groupId >org.elasticflow</ groupId >
< artifactId >elasticflow</ artifactId >
< version >6.0.8</ version >
< scope >system</ scope >
< systemPath >./target/elasticflow.jar</ systemPath >
</ dependency >
- Código de prueba de desarrollo de complementos, por ejemplo:
@ Before
public void setUp () {
System . setProperty ( "config" , "/work/EF/" );
System . setProperty ( "nodeid" , "1" );
}
@ Test
public void testPlugin () throws Exception {
Run . main ( null );
while ( true ) {
}
} Plan de desarrollo
- Soporte de LLM para obtener más acceso a la capacidad
- Optimizar el monitoreo de la cadena de llamadas.
- 6.x Planificación de funciones de la versión.
Citando elasticflow (ita)
@article { agtabular ,
title = { ElasticFlow (伊塔):ElasticFlow(伊塔)是一个开源弹性流数据交换系统,支持在任意类型数据端之间通过简单配置就可以建立可计算的弹性流管道,并进行定时、定量、高并发、多类型的交换数据服务。系统可应用于数据交换、通用搜索引擎、数据发布服务、数据仓库等项目。 } ,
author = { chengwen } ,
year = { 2023 }
}