Elasticflow (ITA)
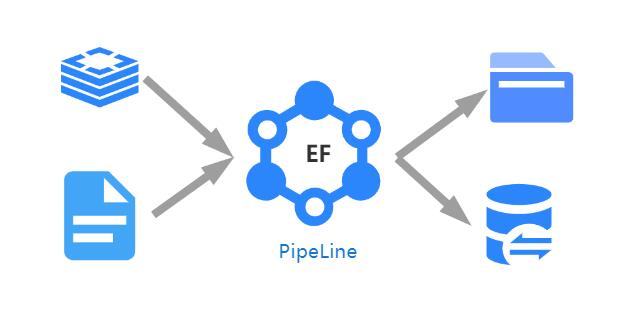
O ElasticFlow é um sistema de troca de dados de fluxo elástico de código aberto que suporta o estabelecimento de tubulações de fluxo elástico computável entre qualquer tipo de dados termina por meio de configuração simples e executam o tempo, os serviços de dados de troca quantitativos, de alta concorrência e de vários tipos. O sistema pode ser aplicado à troca de dados, mecanismo de pesquisa geral, serviços de publicação de dados, data warehouses e outros projetos.
O que o ElasticFlow usa para resolver?
- Como sistema de troca de dados, o ElasticFlow pode gravar dados na extremidade de destino e também pode suportar serviços de computação e processamento de dados durante o processo de troca de dados. Existem métodos de controle de vários níveis e multi-grades durante o processo de troca de dados do Elasticflow, que facilita o mapeamento de campo entre a "extremidade de leitura" e a "extremidade de gravação" dos dados. Além disso, o sistema também possui um mecanismo de controle do lado da gravação para apoiar o mecanismo de controle síncrono da escrita de várias tarefas no mesmo local.
- O ElasticFlow pode ser aprimorado com um sistema distribuído (mestre/escravo) ou pode ser executado como um nó único, onde a implantação distribuída suportará o balanceamento automático de carga de tarefas no nível da instância para ativar a construção de tarefas de fluxo elástico em larga escala.
- Pode resolver o problema:
- Sincronização de dados entre diferentes fontes;
- Os dados são processados no lado do cálculo (como o processamento de inferência dos modelos de domínio PNL e CV) no lado do destino da gravação, como acesso ao serviço de streaming de vídeo;
- Construir serviços de mecanismo de pesquisa, como incremental, completo e indexação por data;
- Outros cenários em que o controle de troca de dados é necessário entre os sistemas.
Versões
característica
- Suporta o sistema de operação de modo distribuído ou único
- Suporta o agendamento de tarefas distribuídas, como o sistema, pode executar automaticamente o balanceamento de carga de tarefas entre clusters
- Suporta estratégias de execução concorrentes de vários níveis, como simultaneidade de pipeline, concorrência de tarefas e outros métodos para acelerar o processamento de dados
- Suporta a operação da cadeia de tarefas e o sistema fornece ordem de dependência do controle da operação entre tarefas
- Apoiar a programação de prioridade da tarefa, tarefas de baixa prioridade reduzirão automaticamente o pipeline de processamento quando os recursos forem insuficientes
- Suporta tarefas de nível abstrato que controlam tarefas virtuais.
- Suporta a integração e a computação de dados, principalmente para apoiar o acesso a serviços externos para fornecer processamento de inferência de dados de modelos de aprendizado profundo
Vantagens principais
- Monitoramento de qualidade de dados confiável
- Cada campo pode ser configurado com sua própria estratégia de conversão de tipo de dados, para que os dados possam ser transmitidos ao destino integral e sem perdas;
- Fornecer monitoramento em tempo real da leitura, computação e escrita em tempo real da lição de casa;
- Controle de fluxo elástico
- A tarefa é executada ao monitorar a tarefa executada.
- A operação de tarefas tem controle de prioridade e, quando falta os recursos do sistema, o "tráfego" da operação de baixa prioridade será controlado para reduzir automaticamente o tamanho do pipeline;
- Controle de cálculo de dados
- Após a introdução do terminal de computação, o sistema pode executar serviços de cálculo nos dados de streaming e pode fornecer serviços de computação de inferência através da API REST ou carregar modelos de aprendizado profundo;
- O terminal de computação pode controlar automaticamente o sistema para iniciar mais serviços de computação de acordo com o tamanho do fluxo e executar o gerenciamento de balanceamento de carga;
- Forte desempenho de sincronização
- O processamento de dados pode ser processado simultaneamente em vários níveis, como pipelines e canais;
- O sistema suporta tarefas virtuais e várias tarefas podem ser usadas para concluir o mesmo processamento de dados, e as tarefas virtuais podem realizar o controle entre várias tarefas;
- Mecanismo robusto de tolerância a falhas
- O sistema pode implementar automaticamente a tentativa local/global de vários níveis no nível de encadeamento, nível de processo e nível de trabalho para garantir a operação estável das tarefas;
- O sistema é desligado e usa o modo de desligamento suave, que executará automaticamente o pouso seguro das tarefas de cluster para evitar a perda de dados quando dados sujos entram no final e lê.
Suporte ao leitor
- Hbase 1.x
- Kafka
- RocketMQ 4.x
- Mysql
- Oracle
- files (txt,csv)
Suporte ao computador
- Rest API (POST/JSON)
- Model
Apoio ao escritor
- ElasticSearch 7.x
- Mysql
- Neo4j 3.x
- Vearch
- Hbase 1.x
- Kafka 2.x
Suporte ao pesquisador
- Vearch
- Kafka
- ElasticSearch
Documento
- Consulte o wiki para obter documentação detalhada
- Exemplo de troca de dados referência
- Referência de instalação e implantação
Interface de gerenciamento visual
Mudanças
A versão 6.0 possui uma nova atualização de arquitetura para a versão anterior e não suporta mais o aprendizado profundo por meio de Java.
Desenvolvimento de plug-in EF
- Pacote POM:
< dependency >
< groupId >org.elasticflow</ groupId >
< artifactId >elasticflow</ artifactId >
< version >6.0.8</ version >
< scope >system</ scope >
< systemPath >./target/elasticflow.jar</ systemPath >
</ dependency >
- Código de teste de desenvolvimento de plug -in, por exemplo:
@ Before
public void setUp () {
System . setProperty ( "config" , "/work/EF/" );
System . setProperty ( "nodeid" , "1" );
}
@ Test
public void testPlugin () throws Exception {
Run . main ( null );
while ( true ) {
}
} Plano de desenvolvimento
- Suporte LLMS para mais acesso de capacidade
- Otimize o monitoramento da cadeia de chamadas.
- Planejamento da função da versão 6.x.x.
Citando ElasticFlow (ITA)
@article { agtabular ,
title = { ElasticFlow (伊塔):ElasticFlow(伊塔)是一个开源弹性流数据交换系统,支持在任意类型数据端之间通过简单配置就可以建立可计算的弹性流管道,并进行定时、定量、高并发、多类型的交换数据服务。系统可应用于数据交换、通用搜索引擎、数据发布服务、数据仓库等项目。 } ,
author = { chengwen } ,
year = { 2023 }
}