Elasticflow (ITA)
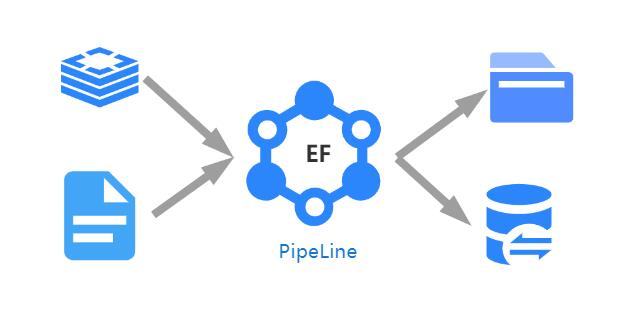
Elasticflow ist ein Open-Source-Elastic Flow Data Exchange-System, das die Festlegung von rechtzeitigen elastischen Flusspipelines zwischen einer beliebigen Art von Daten endet, die durch einfache Konfiguration und Timing-, quantitative, hohe Parallelitäts- und Austauschdatendienste mit mehreren Typen ausführen. Das System kann auf Datenaustausch, allgemeine Suchmaschinen, Datenveröffentlichungsdienste, Data Warehouses und andere Projekte angewendet werden.
Was verwendet der Elasticflow, um zu lösen?
- Als Datenaustauschsystem kann Elasticflow Daten an das Zielende schreiben und auch Datencomputer- und Verarbeitungsdienste während des Datenaustauschprozesses unterstützen. Während des Elasticflow-Datenaustauschprozesses gibt es mehrstufige und mehrverteilte Kontrollmethoden, die die Feldzuordnung zwischen dem "Read-Ende" und dem "Schreibende" von Daten erleichtert. Darüber hinaus verfügt das System über einen Schreibseite des Kontrollmechanismus, um den synchronen Kontrollmechanismus des Schreibens von Multitaskieren an denselben Ort zu unterstützen.
- Der Elasticflow kann durch ein verteiltes System (Master/Slave) verbessert werden oder als einzelner Knoten ausgeführt werden, wobei die verteilte Bereitstellung auf der Instanzebene automatische Aufgabenlastausgleich unterstützt, um ein großräumiges Aufbau von Elastic Flow Task zu ermöglichen.
- Kann das Problem lösen:
- Datensynchronisation zwischen verschiedenen Quellen;
- Die Daten werden auf der Berechnungsseite (z. B. die Inferenzverarbeitung der NLP- und CV -Domänenmodelle) auf der Schreibzielseite verarbeitet, wie z. B. Video -Streaming -Dienstzugriff.
- Erstellen Sie Suchmaschinendienste wie inkrementelle, vollständige und indizieren nach Datum;
- Andere Szenarien, in denen die Datenaustauschsteuerung zwischen den Systemen erforderlich ist.
Versionen
Merkmal
- Unterstützt das Betriebssystem für das verteilte oder ein Knotenmodus
- Unterstützt die verteilte Aufgabenplanung, z. B. das System kann automatisch Aufgabenlastausgleich zwischen Clustern durchführen
- Unterstützt mehrstufige gleichzeitige Ausführungsstrategien wie Pipeline-Parallelität, Aufgabe und andere Methoden zur Beschleunigung der Datenverarbeitung
- Unterstützt den Betrieb der Aufgabenkette, und das System bietet Reihenfolge der Abhängigkeit von der Betriebskontrolle zwischen Aufgaben
- Support Task Priority Planing und Aufgaben mit niedriger Priorität werden die Verarbeitungspipeline automatisch verkleinern, wenn die Ressourcen nicht ausreicht
- Unterstützt Aufgaben auf abstrakter Ebene, die Aufgaben steuern.
- Unterstützt die Datenintegration und -Computerin, hauptsächlich, um den Zugriff auf externe Dienste zu unterstützen, um die Verarbeitung von Deep -Learning -Modellen für die Dateninferenz bereitzustellen
Kernvorteile
- Zuverlässige Datenqualitätsüberwachung
- Jedes Feld kann mit seiner eigenen Datentyp -Konvertierungsstrategie konfiguriert werden, damit die Daten in voller und verlustfreier Daten an das Ziel übertragen werden können.
- Bereitstellung von Runtime-Überwachung von Hausaufgaben im Lesen, Computer und Schreiben;
- Elastische Flussregelung
- Die Aufgabe wird bei der Überwachung der Aufgabe ausgeführt.
- Der Aufgabenbetrieb hat eine vorrangige Kontrolle, und wenn die Systemressourcen fehlen, wird der "Verkehr" des Betriebs mit niedriger Priorität gesteuert, um die Pipeline-Größe automatisch zu reduzieren.
- Datenberechnungskontrolle
- Nach der Einführung des Computing -Terminals kann das System Berechnungsdienste für Streaming -Daten durchführen und Inferenz -Computerdienste über die REST -API oder das Laden von Deep -Learning -Modellen bereitstellen.
- Das Computerterminal kann das System automatisch steuern, um mehr Computerdienste gemäß der Durchflussgröße zu starten und das Lastausgleichsmanagement durchzuführen.
- Starke Synchronisationsleistung
- Die Datenverarbeitung kann gleichzeitig auf mehreren Ebenen wie Pipelines und Kanälen verarbeitet werden.
- Das System unterstützt virtuelle Aufgaben, und mehrere Aufgaben können verwendet werden, um dieselbe Datenverarbeitung zu erledigen, und virtuelle Aufgaben können die Steuerung zwischen mehreren Aufgaben realisieren.
- Robuster Fehlertoleranzmechanismus
- Das System kann automatisch mehrstufige lokale/globale Wiederholung auf Thread-Ebene, Prozessebene und Arbeitsebene implementieren, um den stabilen Betrieb von Aufgaben zu gewährleisten.
- Das System wird ausgeschaltet und verwendet den Soft -Shutdown -Modus, wodurch automatisch eine sichere Landung von Clusteraufgaben durchgeführt wird, um den Datenverlust zu verhindern, wenn schmutzige Daten in das Ende eintreten und liest.
Leserunterstützung
- Hbase 1.x
- Kafka
- RocketMQ 4.x
- Mysql
- Oracle
- files (txt,csv)
Computerunterstützung
- Rest API (POST/JSON)
- Model
Autorsunterstützung
- ElasticSearch 7.x
- Mysql
- Neo4j 3.x
- Vearch
- Hbase 1.x
- Kafka 2.x
Sucherunterstützung
- Vearch
- Kafka
- ElasticSearch
Dokumentieren
- Eine detaillierte Dokumentation finden Sie im Wiki
- Datenaustauschbeispielreferenz
- Referenz für Installation und Bereitstellung
Visuelle Verwaltungsschnittstelle
Änderungen
Version 6.0 verfügt über ein neues Architektur -Upgrade für die vorherige Version und unterstützt das Deep -Lernen nicht mehr über Java.
EF-Plug-in-Entwicklung
- POM -Paket:
< dependency >
< groupId >org.elasticflow</ groupId >
< artifactId >elasticflow</ artifactId >
< version >6.0.8</ version >
< scope >system</ scope >
< systemPath >./target/elasticflow.jar</ systemPath >
</ dependency >
- Plugin -Entwicklungstestcode, zum Beispiel:
@ Before
public void setUp () {
System . setProperty ( "config" , "/work/EF/" );
System . setProperty ( "nodeid" , "1" );
}
@ Test
public void testPlugin () throws Exception {
Run . main ( null );
while ( true ) {
}
} Entwicklungsplan
- Unterstützen Sie LLMs für den Zugang zu mehr Funktionen
- Optimieren Sie die Überwachung der Anrufkette.
- 6.x Versionsfunktionsplanung.
Zitieren von Elasticflow (ITA)
@article { agtabular ,
title = { ElasticFlow (伊塔):ElasticFlow(伊塔)是一个开源弹性流数据交换系统,支持在任意类型数据端之间通过简单配置就可以建立可计算的弹性流管道,并进行定时、定量、高并发、多类型的交换数据服务。系统可应用于数据交换、通用搜索引擎、数据发布服务、数据仓库等项目。 } ,
author = { chengwen } ,
year = { 2023 }
}