ElasticFlow (Ita)
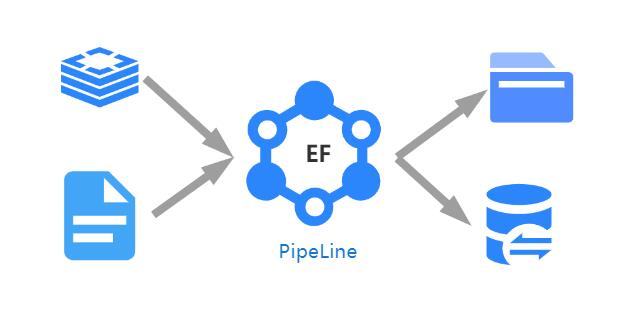
ElasticFlow is an open source elastic flow data exchange system that supports the establishment of computable elastic flow pipelines between any type of data ends through simple configuration, and perform timing, quantitative, high concurrency, and multi-type exchange data services. The system can be applied to data exchange, general search engine, data publishing services, data warehouses and other projects.
What does ElasticFlow use to solve?
- As a data exchange system, ElasticFlow can write data to the target end and can also support data computing and processing services during the data exchange process. There are multi-level and multi-grained control methods during the ElasticFlow data exchange process, which facilitates field mapping between the "read end" and the "write end" of data. In addition, the system also has a write-side control mechanism to support the synchronous control mechanism of multi-task writing to the same place.
- ElasticFlow can be enhanced with a distributed system (Master/Slave) or can be run as a single node, where distributed deployment will support automatic task load balancing on the instance level to enable large-scale elastic flow task building.
- Can solve the problem:
- Data synchronization between different sources;
- The data is processed on the calculation side (such as the inference processing of the NLP and CV domain models) at the write target side, such as video streaming service access;
- Build search engine services, such as incremental, full, and indexing by date;
- Other scenarios where data exchange control is required between systems.
Versions
characteristic
- Supports distributed or single-node mode operation system
- Supports distributed task scheduling, such as the system can automatically perform task load balancing between clusters
- Supports multi-level concurrent execution strategies, such as pipeline concurrency, task concurrency and other methods to speed up data processing
- Supports task chain operation, and the system provides order of dependence on operation control between tasks
- Support task priority scheduling, low-priority tasks will automatically shrink the processing pipeline when resources are insufficient
- Supports abstract-level tasks that control tasks. Virtual tasks can control multiple tasks when the same thing is performed on the write end.
- Supports data integration and computing, mainly to support access to external services to provide data inference processing of deep learning models
Core advantages
- Reliable data quality monitoring
- Each field can be configured with its own data type conversion strategy so that the data can be transmitted to the destination in full and lossless;
- Provide real-time runtime monitoring of homework reading, computing and writing;
- Elastic flow control
- The task runs when monitoring the task runs. When the state error reaches the specified feature value, the flow will be disconnected;
- Task operation has priority control, and when the system resources are lacking, the "traffic" of low-priority operation will be controlled to automatically reduce the pipeline size;
- Data calculation control
- After introducing the computing terminal, the system can perform calculation services on streaming data, and can provide inference computing services through the Rest API or loading deep learning models;
- The computing terminal can automatically control the system to start more computing services according to the flow size and perform load balancing management;
- Strong synchronization performance
- Data processing can be processed concurrently at multiple levels such as pipelines and channels;
- The system supports virtual tasks, and multiple tasks can be used to complete the same data processing, and virtual tasks can realize the control between multiple tasks;
- Robust fault tolerance mechanism
- The system can automatically implement multi-level local/global retry at thread level, process level, and job level to ensure the stable operation of tasks;
- The system is turned off and uses soft shutdown mode, which will automatically perform safe landing of cluster tasks to prevent data loss when dirty data enters the end and reads.
Reader Support
- Hbase 1.x
- Kafka
- RocketMQ 4.x
- Mysql
- Oracle
- files (txt,csv)
Computer Support
- Rest API (POST/JSON)
- Model
Writer Support
- ElasticSearch 7.x
- Mysql
- Neo4j 3.x
- Vearch
- Hbase 1.x
- Kafka 2.x
Searcher Support
- Vearch
- Kafka
- ElasticSearch
Document
- Refer to the wiki for detailed documentation
- Data exchange example reference
- Installation and deployment reference
Visual management interface
Changes
Version 6.0 has a new architecture upgrade to the previous version, and no longer supports deep learning natively through Java. The computing stream implements data computing services by calling the external inference service rest interface.
EF plug-in development
- Pom package:
< dependency >
< groupId >org.elasticflow</ groupId >
< artifactId >elasticflow</ artifactId >
< version >6.0.8</ version >
< scope >system</ scope >
< systemPath >./target/elasticflow.jar</ systemPath >
</ dependency >
- Plugin development test code, for example:
@ Before
public void setUp () {
System . setProperty ( "config" , "/work/EF/" );
System . setProperty ( "nodeid" , "1" );
}
@ Test
public void testPlugin () throws Exception {
Run . main ( null );
while ( true ) {
}
} Development Plan
- Support LLMs for more capability access
- Optimize call chain monitoring.
- 6.x version function planning.
Citing ElasticFlow (Ita)
@article { agtabular ,
title = { ElasticFlow (伊塔):ElasticFlow(伊塔)是一个开源弹性流数据交换系统,支持在任意类型数据端之间通过简单配置就可以建立可计算的弹性流管道,并进行定时、定量、高并发、多类型的交换数据服务。系统可应用于数据交换、通用搜索引擎、数据发布服务、数据仓库等项目。 } ,
author = { chengwen } ,
year = { 2023 }
}