탄성 흐름 (ITA)
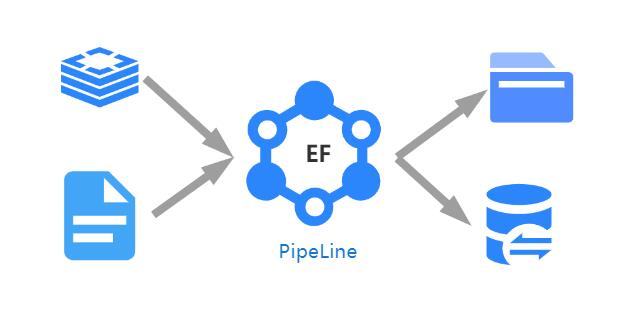
Elasticflow는 간단한 구성을 통해 모든 유형의 데이터 사이에 계산 가능한 탄성 흐름 파이프 라인의 설정을 지원하고 타이밍, 정량적, 높은 동시성 및 다형 교환 데이터 서비스를 수행하는 오픈 소스 Elastic Flow Data Exchange 시스템입니다. 이 시스템은 데이터 교환, 일반 검색 엔진, 데이터 게시 서비스, 데이터웨어 하우스 및 기타 프로젝트에 적용 할 수 있습니다.
Elasticflow는 무엇을 해결하는 데 사용됩니까?
- 데이터 교환 시스템으로서 ElasticFlow는 데이터 교환 프로세스 중에 데이터 컴퓨팅 및 처리 서비스를 지원할 수도 있습니다. 탄성 흐름 데이터 교환 프로세스 중에 다단계 및 다단계 제어 방법이 있으며, 이는 "읽기 종료"와 데이터의 "쓰기 종료"사이의 필드 매핑을 용이하게합니다. 또한이 시스템에는 동일한 장소로의 멀티 태스킹 쓰기의 동기 제어 메커니즘을 지원하는 쓰기 측 제어 메커니즘이 있습니다.
- Elasticflow는 분산 시스템 (마스터/슬레이브)으로 향상되거나 단일 노드로 실행될 수 있으며, 분산 배포는 인스턴스 수준에서 자동 작업로드 밸런싱을 지원하여 대규모 탄성 흐름 작업 구축을 가능하게합니다.
- 문제를 해결할 수 있습니다.
- 다른 소스 간의 데이터 동기화;
- 데이터는 비디오 스트리밍 서비스 액세스와 같은 쓰기 대상 측에서 계산 측 (예 : NLP 및 CV 도메인 모델의 추론 처리)에서 처리됩니다.
- 날짜 별 증분, 전체 및 색인과 같은 검색 엔진 서비스를 구축합니다.
- 시스템간에 데이터 교환 제어가 필요한 다른 시나리오.
버전
특성
- 분산 또는 단일 노드 모드 작동 시스템을 지원합니다
- 시스템과 같은 분산 작업 스케줄링을 지원하여 클러스터간에 작업로드 밸런싱을 자동으로 수행 할 수 있습니다.
- 파이프 라인 동시성, 작업 동시성 및 데이터 처리 속도를 높이는 기타 방법과 같은 다단계 동시 실행 전략을 지원합니다.
- 작업 체인 작동을 지원하고 시스템은 작업 간의 작업 제어에 대한 의존 순서를 제공합니다.
- 지원 작업 우선 순위 일정, 우선 순위가 낮은 작업이 자원이 부족할 때 처리 파이프 라인을 자동으로 축소합니다.
- 작업을 제어하는 초록 수준의 작업을 지원합니다.
- 데이터 통합 및 컴퓨팅을 지원합니다. 주로 외부 서비스에 대한 액세스를 지원하여 딥 러닝 모델의 데이터 추론 처리를 제공합니다.
핵심 장점
- 신뢰할 수있는 데이터 품질 모니터링
- 각 필드는 자체 데이터 유형 변환 전략으로 구성하여 데이터를 전체 및 무손실로 대상으로 전송할 수 있습니다.
- 숙제 읽기, 컴퓨팅 및 쓰기의 실시간 런타임 모니터링을 제공합니다.
- 탄성 흐름 제어
- 상태 오류가 지정된 기능 값에 도달하면 작업이 실행됩니다.
- 작업 운영에는 우선 순위 제어가 있으며 시스템 리소스가 부족한 경우 우선 순위가 낮은 운영의 "트래픽"이 제어되어 파이프 라인 크기를 자동으로 줄입니다.
- 데이터 계산 제어
- 컴퓨팅 터미널을 도입 한 후 시스템은 스트리밍 데이터에 대한 계산 서비스를 수행 할 수 있으며 REST API를 통해 추론 컴퓨팅 서비스를 제공하거나 딥 러닝 모델을로드 할 수 있습니다.
- 컴퓨팅 터미널은 흐름 크기에 따라 더 많은 컴퓨팅 서비스를 시작하기 위해 시스템을 자동으로 제어하고로드 밸런싱 관리를 수행 할 수 있습니다.
- 강력한 동기화 성능
- 데이터 처리는 파이프 라인 및 채널과 같은 여러 수준에서 동시에 처리 될 수 있습니다.
- 이 시스템은 가상 작업을 지원하며 여러 작업을 사용하여 동일한 데이터 처리를 완료 할 수 있으며 가상 작업은 여러 작업 간의 제어를 실현할 수 있습니다.
- 강력한 결함 공차 메커니즘
- 이 시스템은 스레드 레벨, 프로세스 수준 및 작업 수준에서 멀티 레벨 로컬/글로벌 재 시도를 자동으로 구현하여 작업의 안정적인 작동을 보장 할 수 있습니다.
- 시스템이 꺼지고 소프트 셧다운 모드를 사용하여 더러운 데이터가 끝나고 읽을 때 데이터 손실을 방지하기 위해 클러스터 작업의 안전한 착륙을 자동으로 수행합니다.
독자 지원
- Hbase 1.x
- Kafka
- RocketMQ 4.x
- Mysql
- Oracle
- files (txt,csv)
컴퓨터 지원
- Rest API (POST/JSON)
- Model
작가 지원
- ElasticSearch 7.x
- Mysql
- Neo4j 3.x
- Vearch
- Hbase 1.x
- Kafka 2.x
검색자 지원
- Vearch
- Kafka
- ElasticSearch
문서
- 자세한 문서는 위키를 참조하십시오
- 데이터 교환 예제 참조
- 설치 및 배포 참조
시각적 관리 인터페이스
변화
버전 6.0은 이전 버전으로 새로운 아키텍처를 업그레이드하며 더 이상 Java를 통해 기본적으로 딥 러닝을 지원하지 않습니다.
EF 플러그인 개발
- POM 패키지 :
< dependency >
< groupId >org.elasticflow</ groupId >
< artifactId >elasticflow</ artifactId >
< version >6.0.8</ version >
< scope >system</ scope >
< systemPath >./target/elasticflow.jar</ systemPath >
</ dependency >
- 플러그인 개발 테스트 코드 (예 :
@ Before
public void setUp () {
System . setProperty ( "config" , "/work/EF/" );
System . setProperty ( "nodeid" , "1" );
}
@ Test
public void testPlugin () throws Exception {
Run . main ( null );
while ( true ) {
}
} 개발 계획
- 더 많은 기능 액세스를 위해 LLM을 지원합니다
- 통화 체인 모니터링 최적화.
- 6.x 버전 기능 계획.
Elasticflow 인용 (ITA)
@article { agtabular ,
title = { ElasticFlow (伊塔):ElasticFlow(伊塔)是一个开源弹性流数据交换系统,支持在任意类型数据端之间通过简单配置就可以建立可计算的弹性流管道,并进行定时、定量、高并发、多类型的交换数据服务。系统可应用于数据交换、通用搜索引擎、数据发布服务、数据仓库等项目。 } ,
author = { chengwen } ,
year = { 2023 }
}