ElasticFlow (ITA)
ElasticFlow est un système d'échange de données de flux élastique élastique open source qui prend en charge l'établissement de pipelines d'écoulement élastique calculables entre tout type de données se termine par une configuration simple et effectuer des services de données d'échange de synchronisation, quantitatifs, élevés et élevés et multi-types. Le système peut être appliqué à l'échange de données, au moteur de recherche général, aux services de publication de données, aux entrepôts de données et à d'autres projets.
Qu'utilise ElasticFlow pour résoudre?
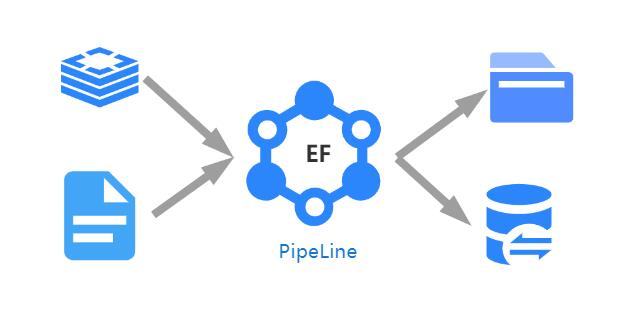
- En tant que système d'échange de données, ElasticFlow peut écrire des données à l'extrémité cible et peut également prendre en charge les services de calcul et de traitement des données pendant le processus d'échange de données. Il existe des méthodes de contrôle à plusieurs niveaux et à grains multiples pendant le processus d'échange de données ElasticFlow, qui facilite la cartographie de champ entre la "lecture de lecture" et la "fin d'écriture" des données. De plus, le système dispose également d'un mécanisme de contrôle côté écriture pour soutenir le mécanisme de contrôle synchrone de l'écriture multi-tâches au même endroit.
- ElasticFlow peut être amélioré avec un système distribué (maître / esclave) ou peut être exécuté en tant que nœud unique, où le déploiement distribué prendra en charge l'équilibrage automatique de la charge des tâches au niveau de l'instance pour permettre le renforcement des tâches à débit élastique à grande échelle.
- Peut résoudre le problème:
- Synchronisation des données entre différentes sources;
- Les données sont traitées du côté calcul (telles que le traitement d'inférence des modèles de domaine NLP et CV) du côté cible d'écriture, tels que l'accès au service de streaming vidéo;
- Créer des services de moteur de recherche, tels que incrémentiel, complet et indexation par date;
- Autres scénarios où le contrôle d'échange de données est requis entre les systèmes.
Versions
caractéristiques
- Prend en charge le système de fonctionnement en mode distribué ou à nœud
- Prend en charge la planification des tâches distribuée, comme le système peut automatiquement effectuer un équilibrage de charge de tâche entre les clusters
- Prend en charge les stratégies d'exécution simultanées à plusieurs niveaux, telles que la concurrence des pipelines, la concurrence des tâches et d'autres méthodes pour accélérer le traitement des données
- Prend en charge le fonctionnement de la chaîne de travail et le système fournit l'ordre de dépendance à l'égard du contrôle de l'opération entre les tâches
- La planification de la priorité de la tâche de support, les tâches à faible priorité réduiront automatiquement le pipeline de traitement lorsque les ressources sont insuffisantes
- Prend en charge les tâches de niveau abstraites qui contrôlent les tâches.
- Prend en charge l'intégration et l'informatique des données, principalement pour prendre en charge l'accès aux services externes pour fournir un traitement d'inférence des données des modèles d'apprentissage en profondeur
Avantages de base
- Surveillance fiable de la qualité des données
- Chaque champ peut être configuré avec sa propre stratégie de conversion de type de données afin que les données puissent être transmises à la destination en pleine et sans perte;
- Fournir une surveillance d'exécution en temps réel de la lecture, de l'informatique et de l'écriture des devoirs;
- Contrôle de débit élastique
- La tâche s'exécute lors de la surveillance de la tâche.
- Le fonctionnement de la tâche a un contrôle prioritaire et lorsque les ressources système font défaut, le «trafic» de l'opération à faible priorité sera contrôlé pour réduire automatiquement la taille du pipeline;
- Contrôle de calcul des données
- Après avoir introduit le terminal informatique, le système peut effectuer des services de calcul sur les données de streaming et peut fournir des services informatiques d'inférence via l'API REST ou le chargement des modèles d'apprentissage en profondeur;
- Le terminal informatique peut contrôler automatiquement le système pour démarrer plus de services informatiques en fonction de la taille du flux et effectuer une gestion d'équilibrage de charge;
- Fortes performances de synchronisation
- Le traitement des données peut être traité simultanément à plusieurs niveaux tels que les pipelines et les canaux;
- Le système prend en charge les tâches virtuelles et plusieurs tâches peuvent être utilisées pour effectuer le même traitement des données, et les tâches virtuelles peuvent réaliser le contrôle entre plusieurs tâches;
- Mécanisme de tolérance aux défauts robuste
- Le système peut mettre en œuvre automatiquement la nouvelle tentative locale / globale à plusieurs niveaux au niveau du thread, au niveau du processus et au niveau du travail pour assurer le fonctionnement stable des tâches;
- Le système est désactivé et utilise le mode d'arrêt doux, qui effectuera automatiquement un atterrissage sûr des tâches de cluster pour éviter la perte de données lorsque les données sales entrent en fin et se lit
Support du lecteur
- Hbase 1.x
- Kafka
- RocketMQ 4.x
- Mysql
- Oracle
- files (txt,csv)
Support informatique
- Rest API (POST/JSON)
- Model
Support de l'écrivain
- ElasticSearch 7.x
- Mysql
- Neo4j 3.x
- Vearch
- Hbase 1.x
- Kafka 2.x
Prise en charge du chercheur
- Vearch
- Kafka
- ElasticSearch
Document
- Reportez-vous au wiki pour une documentation détaillée
- Exemple d'échange de données Référence
- Référence d'installation et de déploiement
Interface de gestion visuelle
Changements
La version 6.0 a une nouvelle mise à niveau de l'architecture vers la version précédente et ne prend plus en charge l'apprentissage en profondeur nativement via Java.
Développement du plug-in EF
- Pack de pom:
< dependency >
< groupId >org.elasticflow</ groupId >
< artifactId >elasticflow</ artifactId >
< version >6.0.8</ version >
< scope >system</ scope >
< systemPath >./target/elasticflow.jar</ systemPath >
</ dependency >
- Code de test de développement du plugin, par exemple:
@ Before
public void setUp () {
System . setProperty ( "config" , "/work/EF/" );
System . setProperty ( "nodeid" , "1" );
}
@ Test
public void testPlugin () throws Exception {
Run . main ( null );
while ( true ) {
}
} Plan de développement
- Support LLMS pour plus d'accès aux capacités
- Optimiser la surveillance de la chaîne d'appels.
- 6.x Planification de la fonction de version.
Citant ElasticFlow (ITA)
@article { agtabular ,
title = { ElasticFlow (伊塔):ElasticFlow(伊塔)是一个开源弹性流数据交换系统,支持在任意类型数据端之间通过简单配置就可以建立可计算的弹性流管道,并进行定时、定量、高并发、多类型的交换数据服务。系统可应用于数据交换、通用搜索引擎、数据发布服务、数据仓库等项目。 } ,
author = { chengwen } ,
year = { 2023 }
}