langport
0.3.11
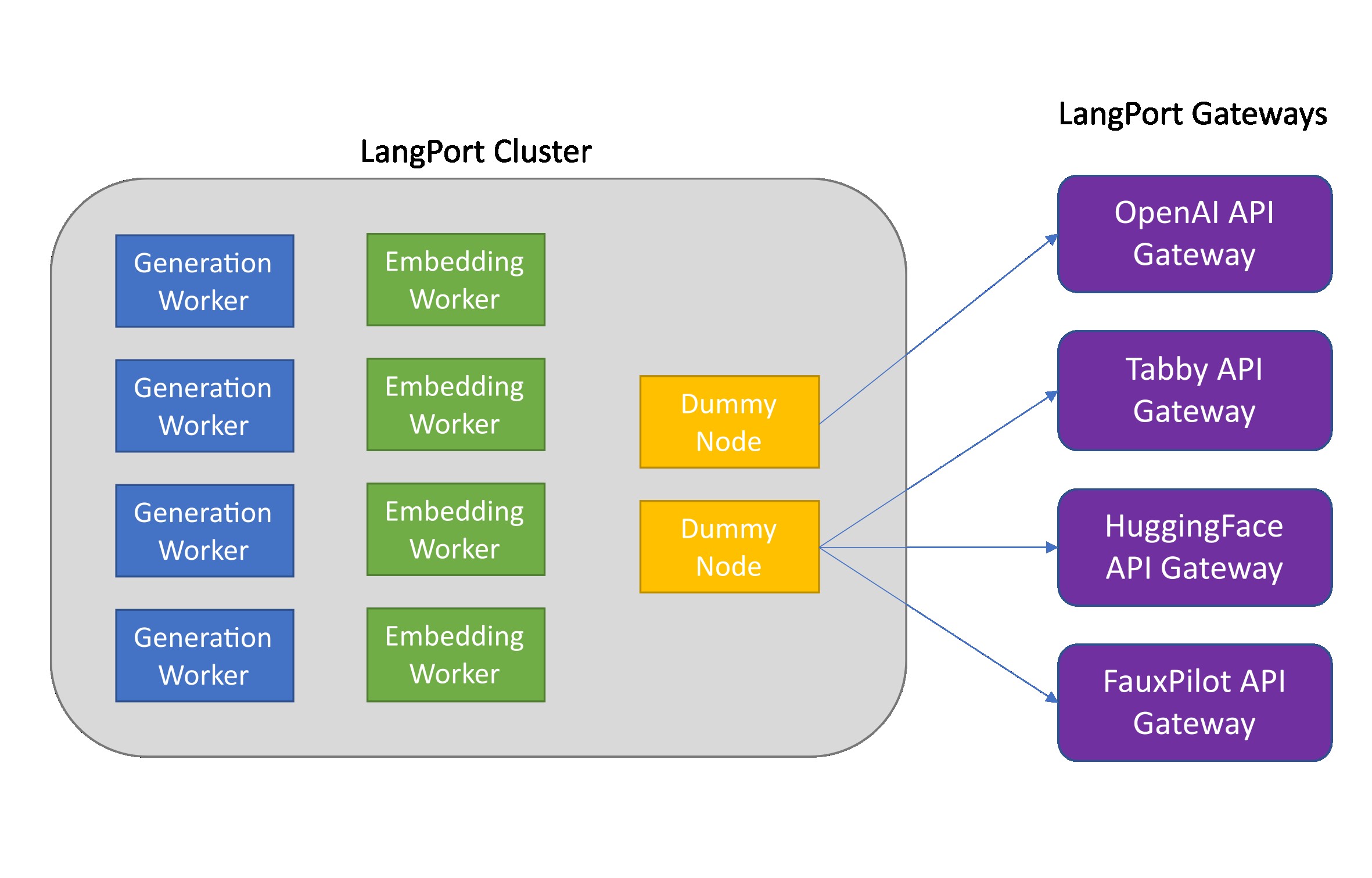
Langport é uma plataforma de servir de modelo de grande idioma de código aberto. Nosso objetivo é construir um serviço de inferência super rápido LLM.
Este projeto é inspirado no LMSYS/FASTCHAT, esperamos que a plataforma de servir seja leve e rápida, mas o FastChat inclui outros recursos, como treinamento e avaliação, o complicou.
Os principais recursos incluem:
ChatProto .pip install langportou:
pip install git+https://github.com/vtuber-plan/langport.git Se você precisar de GGML Generation Worker, use este comando:
pip install langport[ggml]Se você quiser usar a GPU:
CT_CUBLAS=1 pip install langport[ggml]git clone https://github.com/vtuber-plan/langport.git
cd langportpip install --upgrade pip
pip install -e . É simples iniciar um serviço de API de bate -papo local:
Primeiro, inicie um processo de trabalhador no terminal:
python -m langport.service.server.generation_worker --port 21001 --model-path < your model path >Em seguida, inicie um serviço de API em outro terminal:
python -m langport.service.gateway.openai_apiAgora, você pode usar a API de inferência pelo protocolo OpenAI.
É simples iniciar um único serviço de API de bate -papo de nó:
python -m langport.service.server.generation_worker --port 21001 --model-path < your model path >
python -m langport.service.gateway.openai_apiSe você precisar de um único nó API Server de Node:
python -m langport.service.server.embedding_worker --port 21002 --model-path bert-base-chinese --gpus 0 --num-gpus 1
python -m langport.service.gateway.openai_api --port 8000 --controller-address http://localhost:21002Se você precisar da API de incorporação ou outros recursos, poderá implantar um cluster de inferência distribuído:
python -m langport.service.server.dummy_worker --port 21001
python -m langport.service.server.generation_worker --model-path < your model path > --neighbors http://localhost:21001
python -m langport.service.server.embedding_worker --model-path < your model path > --neighbors http://localhost:21001
python -m langport.service.gateway.openai_api --controller-address http://localhost:21001Na prática, o gateway pode se conectar a qualquer nó para distribuir tarefas de inferência:
python -m langport.service.server.dummy_worker --port 21001
python -m langport.service.server.generation_worker --port 21002 --model-path < your model path > --neighbors http://localhost:21001
python -m langport.service.server.generation_worker --port 21003 --model-path < your model path > --neighbors http://localhost:21001 http://localhost:21002
python -m langport.service.server.generation_worker --port 21004 --model-path < your model path > --neighbors http://localhost:21001 http://localhost:21003
python -m langport.service.server.generation_worker --port 21005 --model-path < your model path > --neighbors http://localhost:21001 http://localhost:21004
python -m langport.service.gateway.openai_api --controller-address http://localhost:21003 # 21003 is OK!
python -m langport.service.gateway.openai_api --controller-address http://localhost:21002 # Any worker is also OK!Execute a geração de texto com Multi GPUs:
python -m langport.service.server.generation_worker --port 21001 --model-path < your model path > --gpus 0,1 --num-gpus 2
python -m langport.service.gateway.openai_apiExecute a geração de texto com o GGML Worker:
python -m langport.service.server.ggml_generation_worker --port 21001 --model-path < your model path > --gpu-layers < num layer to gpu (resize this for your VRAM) >Execute o OpenAi Forward Server:
python -m langport.service.server.chatgpt_generation_worker --port 21001 --api-url < url > --api-key < key > Langport é liberado sob a licença do software Apache.


