langport
0.3.11
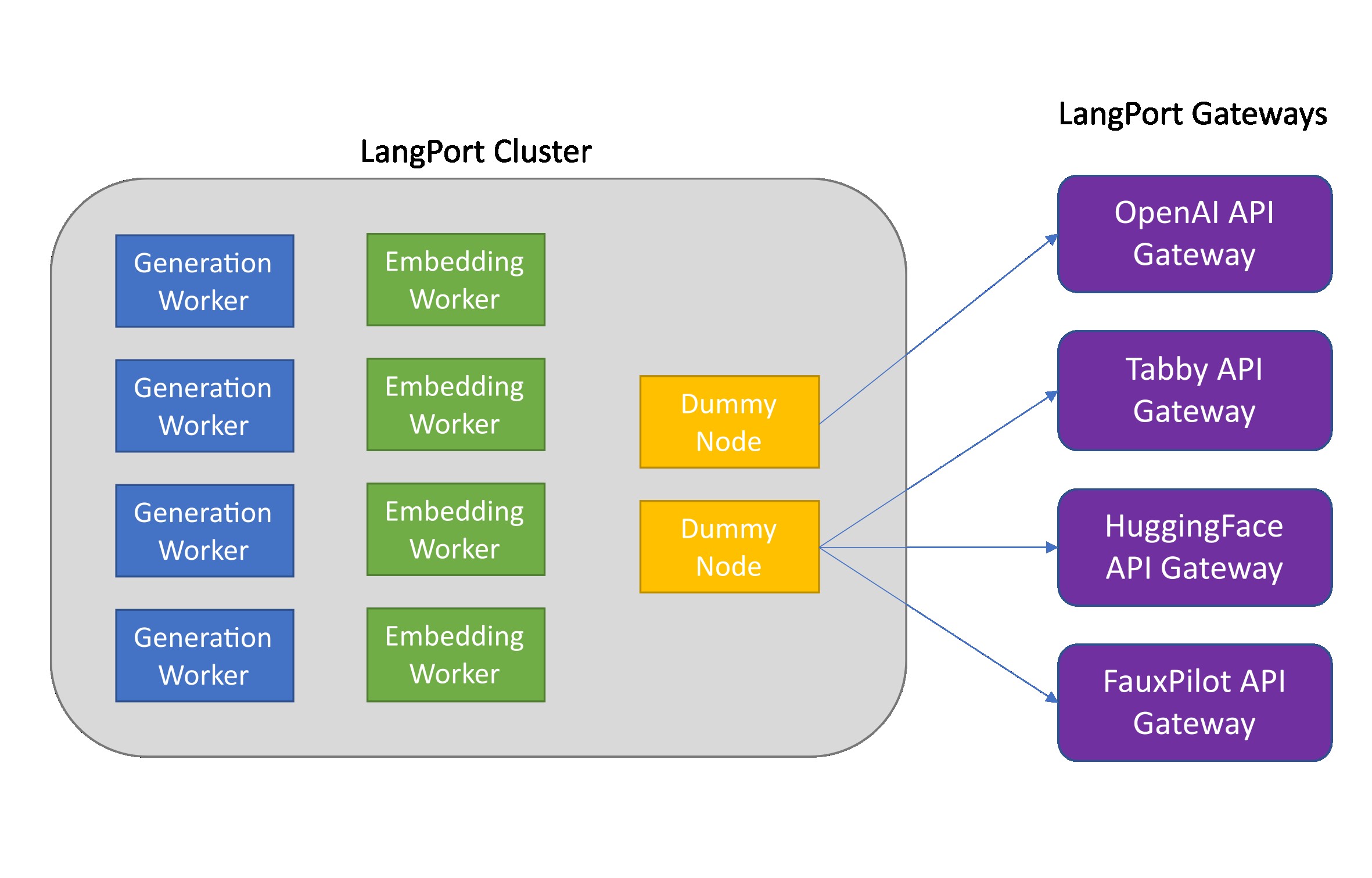
Langport est une plate-forme de service de grande langue open source. Notre objectif est de construire un service d'inférence LLM super rapide.
Ce projet est inspiré par LMSYS / FASTCHAT, nous espérons que la plate-forme de service est légère et rapide, mais FastChat comprend d'autres fonctionnalités telles que la formation et l'évaluation le compliquent.
Les caractéristiques de base comprennent:
ChatProto .pip install langportou:
pip install git+https://github.com/vtuber-plan/langport.git Si vous avez besoin d'un travailleur de la génération GGML, utilisez cette commande:
pip install langport[ggml]Si vous souhaitez utiliser GPU:
CT_CUBLAS=1 pip install langport[ggml]git clone https://github.com/vtuber-plan/langport.git
cd langportpip install --upgrade pip
pip install -e . Il est simple de démarrer un service API de chat local:
Tout d'abord, démarrez un processus de travailleur dans le terminal:
python -m langport.service.server.generation_worker --port 21001 --model-path < your model path >Ensuite, démarrez un service API dans un autre terminal:
python -m langport.service.gateway.openai_apiMaintenant, vous pouvez utiliser l'API d'inférence par le protocole OpenAI.
Il est simple de démarrer un service API de chat de nœud unique:
python -m langport.service.server.generation_worker --port 21001 --model-path < your model path >
python -m langport.service.gateway.openai_apiSi vous avez besoin d'un seul serveur API Embeddings Node:
python -m langport.service.server.embedding_worker --port 21002 --model-path bert-base-chinese --gpus 0 --num-gpus 1
python -m langport.service.gateway.openai_api --port 8000 --controller-address http://localhost:21002Si vous avez besoin de l'API Embeddings ou d'autres fonctionnalités, vous pouvez déployer un cluster d'inférence distribué:
python -m langport.service.server.dummy_worker --port 21001
python -m langport.service.server.generation_worker --model-path < your model path > --neighbors http://localhost:21001
python -m langport.service.server.embedding_worker --model-path < your model path > --neighbors http://localhost:21001
python -m langport.service.gateway.openai_api --controller-address http://localhost:21001En pratique, la passerelle peut se connecter à n'importe quel nœud pour distribuer des tâches d'inférence:
python -m langport.service.server.dummy_worker --port 21001
python -m langport.service.server.generation_worker --port 21002 --model-path < your model path > --neighbors http://localhost:21001
python -m langport.service.server.generation_worker --port 21003 --model-path < your model path > --neighbors http://localhost:21001 http://localhost:21002
python -m langport.service.server.generation_worker --port 21004 --model-path < your model path > --neighbors http://localhost:21001 http://localhost:21003
python -m langport.service.server.generation_worker --port 21005 --model-path < your model path > --neighbors http://localhost:21001 http://localhost:21004
python -m langport.service.gateway.openai_api --controller-address http://localhost:21003 # 21003 is OK!
python -m langport.service.gateway.openai_api --controller-address http://localhost:21002 # Any worker is also OK!Exécutez la génération de texte avec plusieurs GPU:
python -m langport.service.server.generation_worker --port 21001 --model-path < your model path > --gpus 0,1 --num-gpus 2
python -m langport.service.gateway.openai_apiExécutez la génération de texte avec un travailleur GGML:
python -m langport.service.server.ggml_generation_worker --port 21001 --model-path < your model path > --gpu-layers < num layer to gpu (resize this for your VRAM) >Exécutez Openai Forward Server:
python -m langport.service.server.chatgpt_generation_worker --port 21001 --api-url < url > --api-key < key > Langport est publié sous la licence logicielle Apache.


