langport
0.3.11
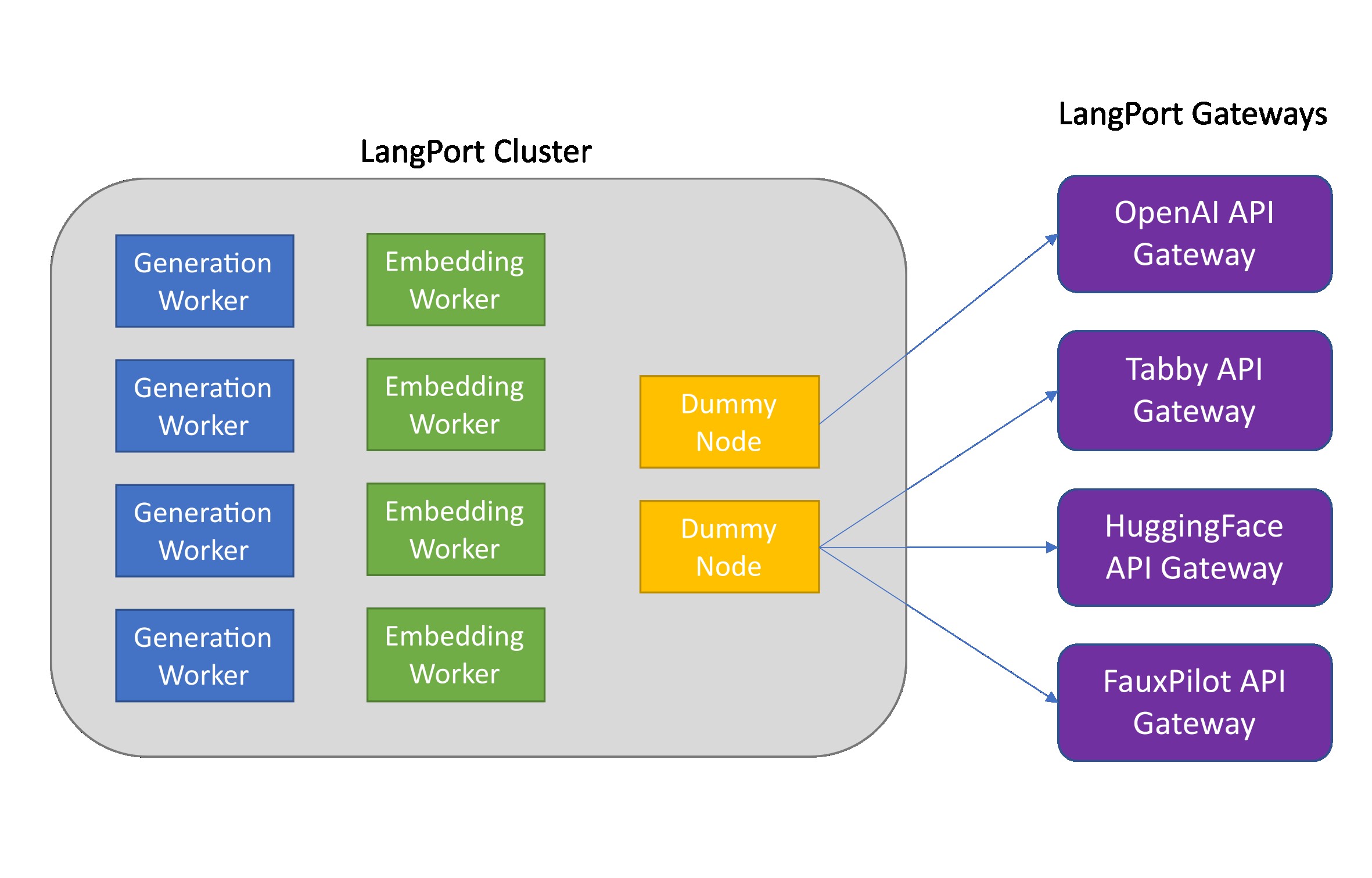
Langport ist eine Open-Source-Dienerplattform mit großer Sprache. Unser Ziel ist es, einen superschnellen LLM -Inferenzservice zu bauen.
Dieses Projekt ist von LMSYS/Fastchat inspiriert. Wir hoffen, dass die Servierplattform leicht und Fast ist. Fastchat enthält jedoch andere Funktionen wie Training und Bewertung, die es kompliziert machen.
Die Kernfunktionen umfassen:
ChatProto ein.pip install langportoder:
pip install git+https://github.com/vtuber-plan/langport.git Wenn Sie einen GGML -Generierungarbeiter benötigen, verwenden Sie diesen Befehl:
pip install langport[ggml]Wenn Sie GPU verwenden möchten:
CT_CUBLAS=1 pip install langport[ggml]git clone https://github.com/vtuber-plan/langport.git
cd langportpip install --upgrade pip
pip install -e . Es ist einfach, einen lokalen Chat -API -Service zu starten:
Starten Sie zunächst einen Arbeitsprozess im Terminal:
python -m langport.service.server.generation_worker --port 21001 --model-path < your model path >Starten Sie dann einen API -Dienst in einem anderen Terminal:
python -m langport.service.gateway.openai_apiJetzt können Sie die Inferenz -API von OpenAI Protocol verwenden.
Es ist einfach, einen einzelnen Knoten -Chat -API -Dienst zu starten:
python -m langport.service.server.generation_worker --port 21001 --model-path < your model path >
python -m langport.service.gateway.openai_apiWenn Sie einen einzelnen Knoten -Einbettungs -API -Server benötigen:
python -m langport.service.server.embedding_worker --port 21002 --model-path bert-base-chinese --gpus 0 --num-gpus 1
python -m langport.service.gateway.openai_api --port 8000 --controller-address http://localhost:21002Wenn Sie die Einbettungs -API oder andere Funktionen benötigen, können Sie einen verteilten Inferenzcluster bereitstellen:
python -m langport.service.server.dummy_worker --port 21001
python -m langport.service.server.generation_worker --model-path < your model path > --neighbors http://localhost:21001
python -m langport.service.server.embedding_worker --model-path < your model path > --neighbors http://localhost:21001
python -m langport.service.gateway.openai_api --controller-address http://localhost:21001In der Praxis kann das Gateway eine Verbindung zu jedem Knoten herstellen, um Inferenzaufgaben zu verteilen:
python -m langport.service.server.dummy_worker --port 21001
python -m langport.service.server.generation_worker --port 21002 --model-path < your model path > --neighbors http://localhost:21001
python -m langport.service.server.generation_worker --port 21003 --model-path < your model path > --neighbors http://localhost:21001 http://localhost:21002
python -m langport.service.server.generation_worker --port 21004 --model-path < your model path > --neighbors http://localhost:21001 http://localhost:21003
python -m langport.service.server.generation_worker --port 21005 --model-path < your model path > --neighbors http://localhost:21001 http://localhost:21004
python -m langport.service.gateway.openai_api --controller-address http://localhost:21003 # 21003 is OK!
python -m langport.service.gateway.openai_api --controller-address http://localhost:21002 # Any worker is also OK!Führen Sie die Textgenerierung mit Multi -GPUs aus:
python -m langport.service.server.generation_worker --port 21001 --model-path < your model path > --gpus 0,1 --num-gpus 2
python -m langport.service.gateway.openai_apiFühren Sie die Textgenerierung mit GGML -Arbeitern aus:
python -m langport.service.server.ggml_generation_worker --port 21001 --model-path < your model path > --gpu-layers < num layer to gpu (resize this for your VRAM) >Führen Sie den OpenAI -Vorwärtsserver aus:
python -m langport.service.server.chatgpt_generation_worker --port 21001 --api-url < url > --api-key < key > Langport wird unter der Apache -Software -Lizenz veröffentlicht.


