langport
0.3.11
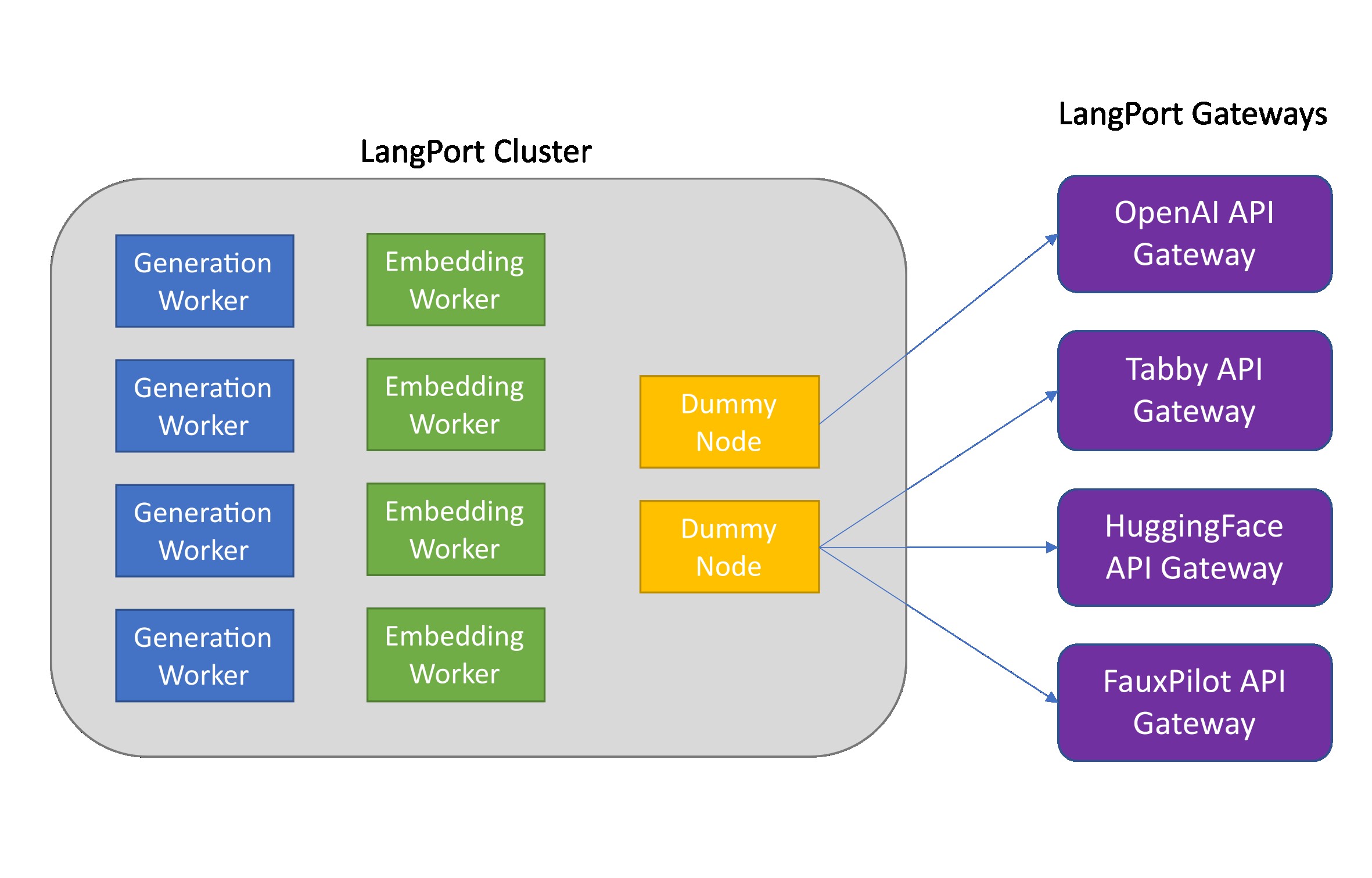
Langport es una plataforma de servicio de modelo de lenguaje de código abierto. Nuestro objetivo es construir un servicio de inferencia Super Fast LLM.
Este proyecto está inspirado en LMSYS/FASTCHAT, esperamos que la plataforma de servicio sea liviana y rápida, pero FastChat incluye otras características, como la capacitación y la evaluación, lo hacen complicado.
Las características principales incluyen:
ChatProto .pip install langporto:
pip install git+https://github.com/vtuber-plan/langport.git Si necesita GGML Generation Worker, use este comando:
pip install langport[ggml]Si quieres usar GPU:
CT_CUBLAS=1 pip install langport[ggml]git clone https://github.com/vtuber-plan/langport.git
cd langportpip install --upgrade pip
pip install -e . Es simple iniciar un servicio de API de chat local:
Primero, comience un proceso de trabajo en la terminal:
python -m langport.service.server.generation_worker --port 21001 --model-path < your model path >Luego, comience un servicio API en otra terminal:
python -m langport.service.gateway.openai_apiAhora, puede usar la API de inferencia por el protocolo Operai.
Es simple iniciar un servicio API de chat de un solo nodo:
python -m langport.service.server.generation_worker --port 21001 --model-path < your model path >
python -m langport.service.gateway.openai_apiSi necesita un servidor API de incrustaciones de un solo nodo:
python -m langport.service.server.embedding_worker --port 21002 --model-path bert-base-chinese --gpus 0 --num-gpus 1
python -m langport.service.gateway.openai_api --port 8000 --controller-address http://localhost:21002Si necesita la API de incrustaciones u otras funciones, puede implementar un clúster de inferencia distribuido:
python -m langport.service.server.dummy_worker --port 21001
python -m langport.service.server.generation_worker --model-path < your model path > --neighbors http://localhost:21001
python -m langport.service.server.embedding_worker --model-path < your model path > --neighbors http://localhost:21001
python -m langport.service.gateway.openai_api --controller-address http://localhost:21001En la práctica, la puerta de enlace puede conectarse a cualquier nodo para distribuir tareas de inferencia:
python -m langport.service.server.dummy_worker --port 21001
python -m langport.service.server.generation_worker --port 21002 --model-path < your model path > --neighbors http://localhost:21001
python -m langport.service.server.generation_worker --port 21003 --model-path < your model path > --neighbors http://localhost:21001 http://localhost:21002
python -m langport.service.server.generation_worker --port 21004 --model-path < your model path > --neighbors http://localhost:21001 http://localhost:21003
python -m langport.service.server.generation_worker --port 21005 --model-path < your model path > --neighbors http://localhost:21001 http://localhost:21004
python -m langport.service.gateway.openai_api --controller-address http://localhost:21003 # 21003 is OK!
python -m langport.service.gateway.openai_api --controller-address http://localhost:21002 # Any worker is also OK!Ejecute la generación de texto con GPU múltiple:
python -m langport.service.server.generation_worker --port 21001 --model-path < your model path > --gpus 0,1 --num-gpus 2
python -m langport.service.gateway.openai_apiEjecute la generación de texto con el trabajador GGML:
python -m langport.service.server.ggml_generation_worker --port 21001 --model-path < your model path > --gpu-layers < num layer to gpu (resize this for your VRAM) >Ejecutar OpenAI Forward Server:
python -m langport.service.server.chatgpt_generation_worker --port 21001 --api-url < url > --api-key < key > Langport se lanza bajo la licencia de software Apache.


