Transformer Text To Speech
1.0.0
Um sistema de texto em fala (TTS) converte texto de linguagem normal em fala; Outros sistemas tornam representações linguísticas simbólicas como transcrições fonéticas na fala. Agora, com o desenvolvimento recente em aprendizado profundo, é possível converter texto em uma voz humana. Para isso, o texto é alimentado em uma rede neural do tipo codificador decodificador para produzir um espectrograma MEL. Agora, esse espectrograma MEL pode ser usado para gerar áudio usando o "Algoritmo Griffin-Lim". Mas, devido à sua desvantagem de que não é capaz de produzir qualidade da fala humana, outra rede neural chamada WaveNet é empregada, que é alimentada pelo MEL-espectrograma para produzir áudio que mesmo um humano não é capaz de se diferenciar.
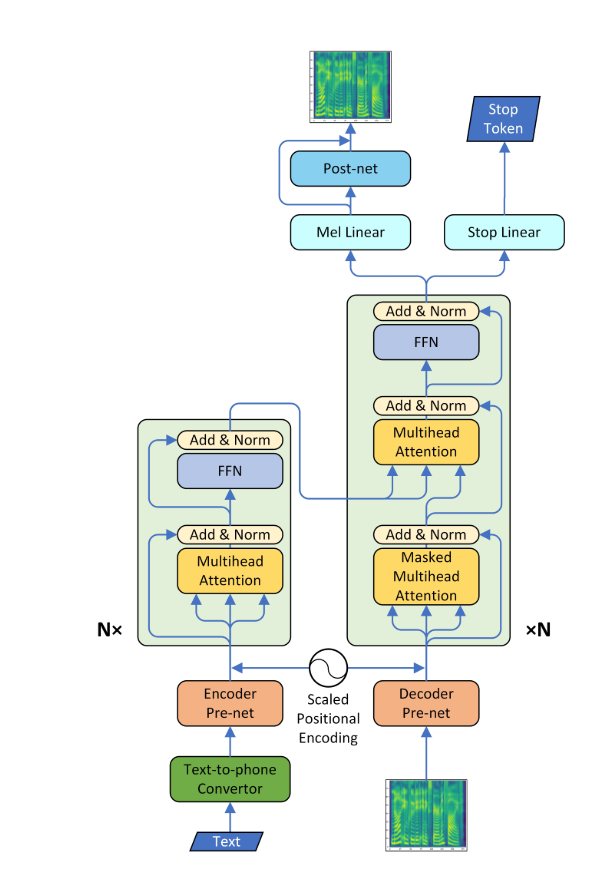
*
O modelo foi treinado em um subconjunto do conjunto de dados WMT-2014 English-Alemman. O pré -processamento foi realizado antes de treinar o modelo.
DataSet: https://keithito.com/lj-seech-dataset/


