Transformer Text To Speech
1.0.0
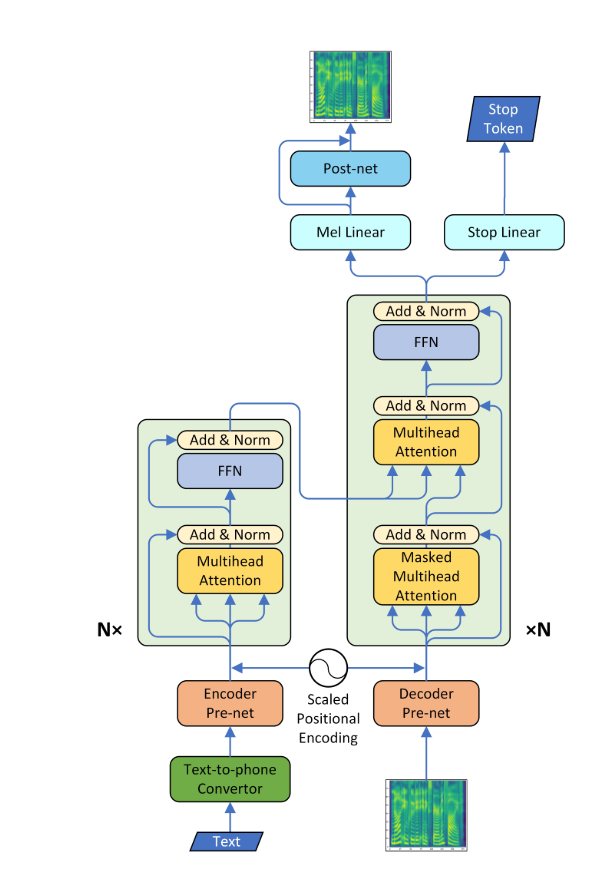
Un système de texte vocal (TTS) convertit le texte du langage normal en parole; D'autres systèmes rendent les représentations linguistiques symboliques comme les transcriptions phonétiques dans la parole. Maintenant, avec un développement récent en Deep Learning, il est possible de convertir le texte en une voix compréhensible humaine. Pour cela, le texte est introduit dans un réseau neuronal de type encodeur pour produire un spectrogramme MEL. Ce spectrogramme MEL peut désormais être utilisé pour générer l'audio à l'aide de "l'algorithme Griffin-LIM". Mais en raison de son désavantage qu'il n'est pas en mesure de produire une qualité de parole de type humain, un autre filet neuronal nommé Wavenet est utilisé, qui est alimenté par le spectrogramme de MEL pour produire l'audio qu'un humain n'est pas en mesure de se différencier.
*
Le modèle a été formé sur un sous-ensemble de l'ensemble de données anglais-allemand WMT-2014. Le prétraitement a été effectué avant d'entraîner le modèle.
Ensemble de données: https://keithito.com/lj-speech-dataset/


