Transformer Text To Speech
1.0.0
يحول نظام النص إلى الكلام (TTS) نص اللغة العادية إلى خطاب ؛ تقدم الأنظمة الأخرى تمثيلات لغوية رمزية مثل النسخ الصوتية في الكلام. الآن مع التطور الأخير في التعلم العميق ، من الممكن تحويل النص إلى صوت يمكن فهمه للإنسان. لهذا ، يتم تغذية النص في شبكة عصبية من نوع التشفير لإخراج طيف الميل. يمكن الآن استخدام هذا الطيف الطيف لإنشاء الصوت باستخدام "خوارزمية Griffin-Lim". ولكن نظرًا لعيارها في عدم قدرتها على إنتاج جودة الكلام التي تشبه الإنسان ، يتم استخدام شبكة عصبية أخرى تدعى Wavenet ، والتي يتم تغذيتها بواسطة طيف الطيف لإنتاج صوت حتى أن الإنسان غير قادر على التمييز.
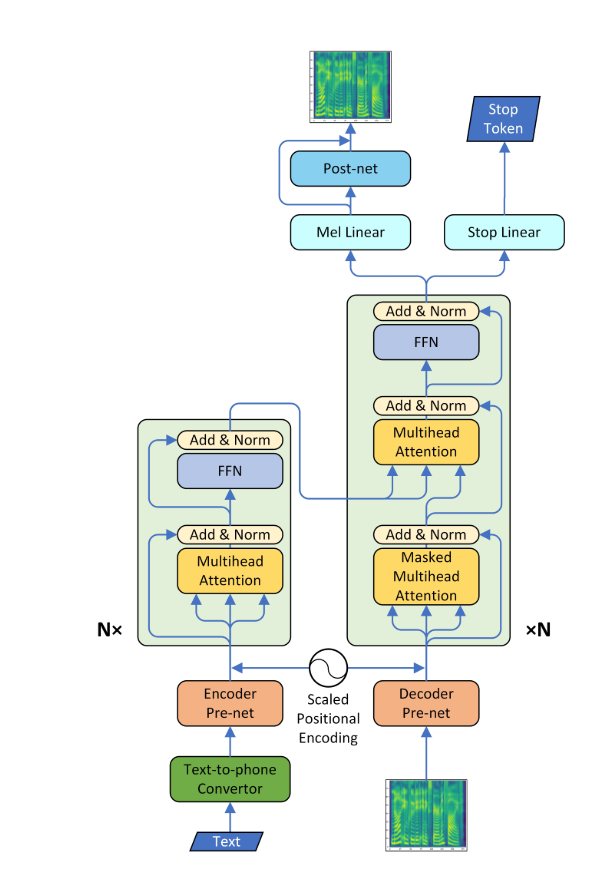
*
تم تدريب النموذج على مجموعة فرعية من مجموعة بيانات WMT-2014 الإنجليز الألمانية. تم إجراء المعالجة المسبقة قبل تدريب النموذج.
DataSet: https://keithito.com/lj-speed-dataset/


