Transformer Text To Speech
1.0.0
Ein TTS-System (Text-to-Speech) wandelt einen normalen Sprachtext in Sprache um; Andere Systeme machen symbolische sprachliche Darstellungen wie phonetische Transkriptionen in Sprache. Mit der jüngsten Entwicklung in Deep Learning ist es möglich, Text in eine menschlich verständliche Stimme umzuwandeln. Zu diesem Zweck wird der Text in ein neuronales Netzwerk vom Encoder-Decoder-Typ eingespeist, um ein Melspektogramm auszugeben. Dieses melspektrogramm kann nun verwendet werden, um Audio mit dem "Griffin-Lim-Algorithmus" zu generieren. Aufgrund seines Nachteils, dass es nicht in der Lage ist, eine menschliche Sprachqualität zu erzeugen, wird ein weiteres neuronales Netz namens Wavenet verwendet, das von Melspektrogramm gefüttert wird, um Audio zu produzieren, das selbst ein Mensch nicht in der Lage ist, sich auseinander zu differenzieren.
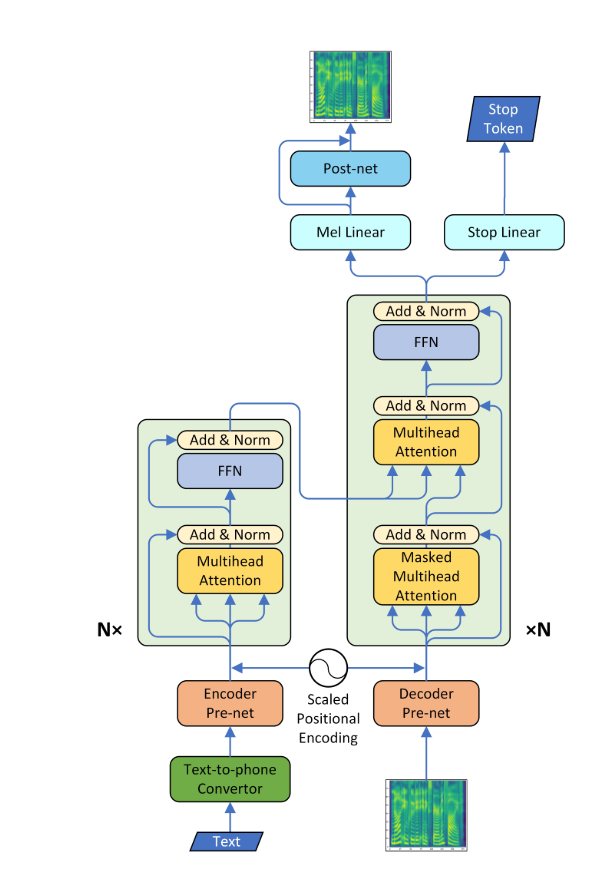
*
Das Modell wurde auf einer Untergruppe von WMT-2014 Englisch-German-Datensatz trainiert. Die Vorverarbeitung wurde vor dem Training des Modells durchgeführt.
Datensatz: https://keithito.com/lj-speech-dataset/


