Transformer Text To Speech
1.0.0
Un sistema de texto a voz (TTS) convierte el texto del lenguaje normal en habla; Otros sistemas hacen que las representaciones lingüísticas simbólicas como las transcripciones fonéticas en el habla. Ahora, con el desarrollo reciente en el aprendizaje profundo, es posible convertir el texto en una voz que se puede ser humano. Para esto, el texto se alimenta a una red neuronal de tipo codificador de decodificador para generar un espectrograma MEL. Este espectrograma MEL ahora se puede usar para generar audio utilizando el "Algoritmo Griffin-Lim". Pero debido a su desventaja de que no es capaz de producir una calidad del habla como el humano, se emplea otra red neuronal llamada Wavenet, que se alimenta por el espectrograma MEL para producir audio que incluso un humano no puede diferenciar aparte.
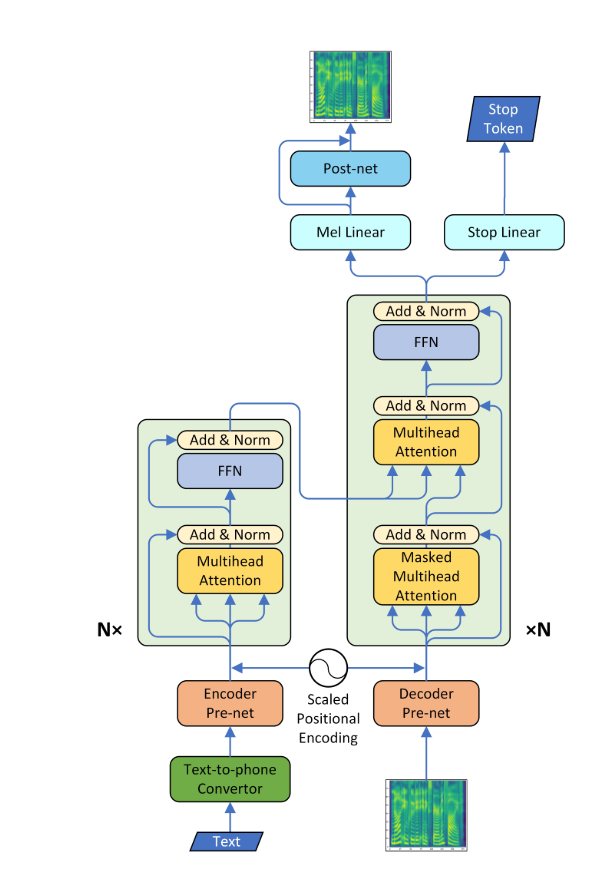
*
El modelo fue entrenado en un subconjunto de conjunto de datos en inglés WMT-2014 en inglés. El preprocesamiento se llevó a cabo antes de entrenar el modelo.
Conjunto de datos: https://keithito.com/lj-speech-dataset/


