Transformer Text To Speech
1.0.0
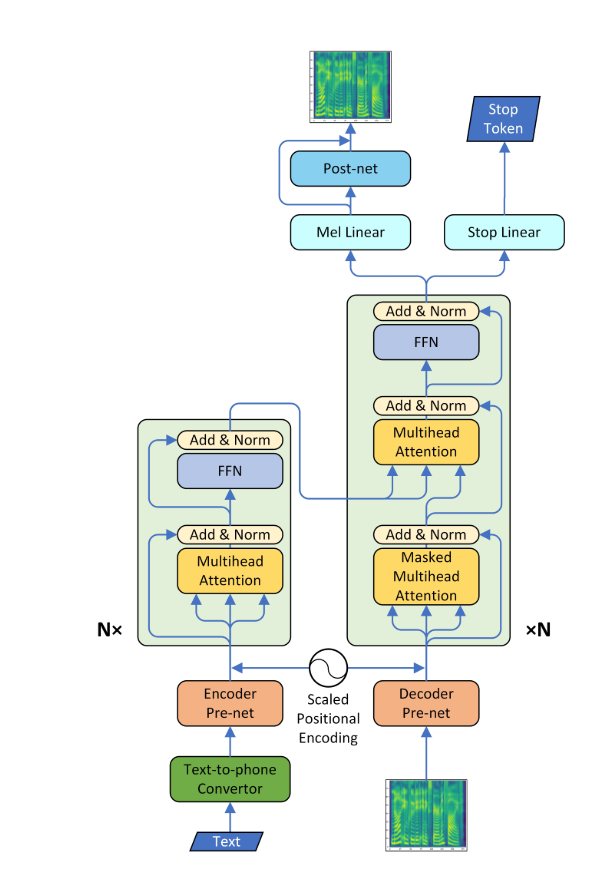
A text-to-speech (TTS) system converts normal language text into speech; other systems render symbolic linguistic representations like phonetic transcriptions into speech. Now with recent development in deep learning, it's possible to convert text into a human-understandable voice. For this, the text is fed into an Encoder-Decoder type Neural Network to output a Mel-Spectrogram. This Mel-Spectrogram can now be used to generate audio using the "Griffin-Lim Algorithm". But due to its disadvantage that it is not able to produce human-like speech quality, another neural net named WaveNet is employed, which is fed by Mel-Spectrogram to produce audio that even a human is not able to differentiate apart.
*
The model was trained on a subset of WMT-2014 English-German Dataset. Preprocessing was carried out before training the model.
Dataset : https://keithito.com/LJ-Speech-Dataset/


