Transformer Text To Speech
1.0.0
Sistem teks-ke-speech (TTS) mengubah teks bahasa normal menjadi pidato; Sistem lain membuat representasi linguistik simbolik seperti transkripsi fonetik menjadi pidato. Sekarang dengan pengembangan baru-baru ini dalam pembelajaran mendalam, dimungkinkan untuk mengubah teks menjadi suara manusia yang dapat dipahami. Untuk ini, teks dimasukkan ke dalam jaringan saraf tipe encoder-decoder untuk menghasilkan Mel-spectrogram. Mel-spectrogram ini sekarang dapat digunakan untuk menghasilkan audio menggunakan "Algoritma Griffin-Lim". Tetapi karena kerugiannya bahwa ia tidak dapat menghasilkan kualitas bicara seperti manusia, jaring saraf lain bernama Wavenet digunakan, yang diberi makan oleh Mel-Spectrogram untuk menghasilkan audio bahwa bahkan manusia tidak dapat membedakan terpisah.
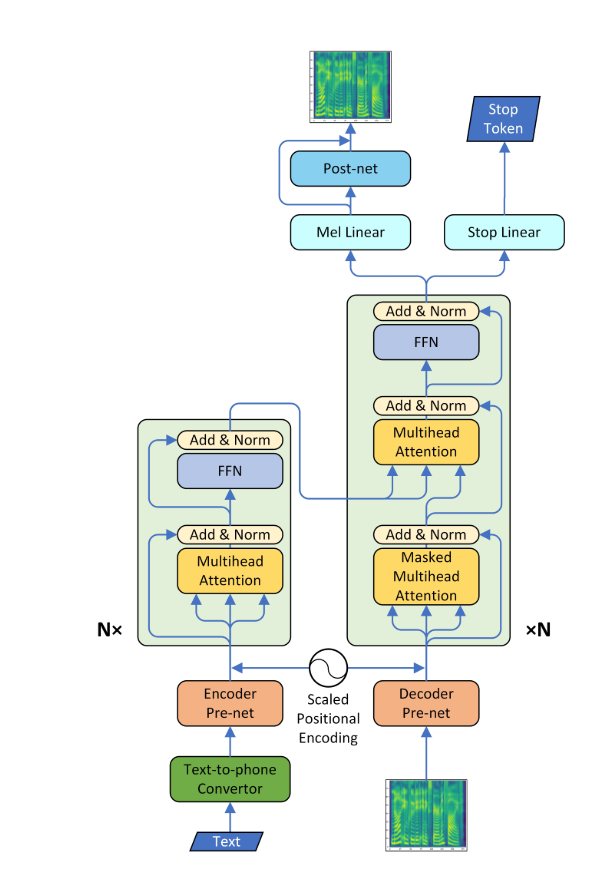
*
Model ini dilatih pada subset dataset WMT-2014 English-Jerman. Preprocessing dilakukan sebelum melatih model.
DataSet: https://keithito.com/lj-feech-dataset/


