rethinking network pruning
1.0.0
Este repositório contém o código para reproduzir os resultados e modelos de imagenet treinados, no artigo a seguir:
Repensando o valor da poda de rede. [ARXIV] [OpenReview]
Zhuang Liu*, Mingjie Sun*, Tinghui Zhou, Gao Huang, Trevor Darrell (*Igual Contribuição).
ICLR 2019. Também prêmio de melhor artigo no NIPS 2018 Workshop sobre redes neurais profundas compactas.
Várias implementações de vários métodos de poda contidas neste repositório também podem ser prontamente usadas para outros fins de pesquisa.

Nosso artigo mostra que, para a poda estruturada , o treinamento do modelo podado do zero pode quase sempre atingir um nível comparável ou mais alto de precisão do que o modelo obtido do procedimento típico de "treinamento, poda e ajuste fino" (Fig. 1) . Concluímos que para esses métodos de poda:
Nossos resultados sugerem a necessidade de avaliações de linha de base mais cuidadosas em pesquisas futuras sobre métodos de poda estruturada.
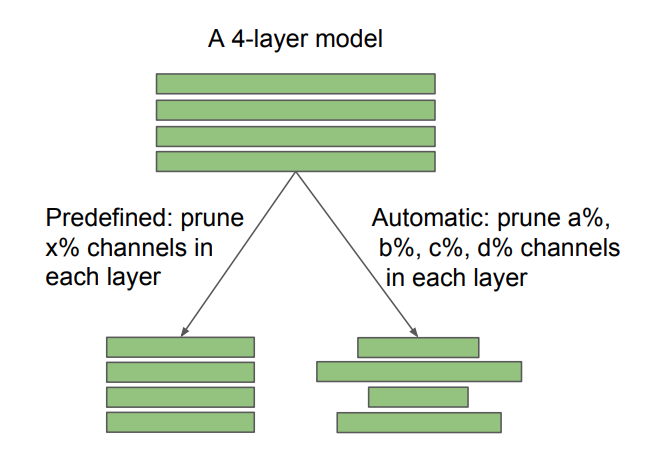
Fig 2: Diferença entre arquiteturas de destino predefinidas e descobertas automaticamente, na poda do canal. A taxa de poda X é especificada pelo usuário, enquanto A, B, C, D são determinados pelo algoritmo de poda. A poda esparsa não estruturada também pode ser vista como automática. Nossa descoberta tem implicações diferentes para métodos predefinidos e automáticos: para um método predefinido, é possível pular o pipeline tradicional de "treinamento, poda e ajuste fino" e treinar diretamente o modelo podado; Para métodos automáticos, a poda pode ser vista como uma forma de aprendizado de arquitetura.
Também comparamos com a "Hipótese de ingressos para a loteria" (Frankle & Carbin 2019) e descobrimos que, com a melhor taxa de aprendizado, a inicialização do "bilhete vencedor", conforme usado em Frankle & Carbin (2019), não traz melhorias em relação à inicialização aleatória. Para mais detalhes, consulte o nosso artigo.
Avaliamos os sete métodos de poda a seguir.
Os seis primeiros são estruturados enquanto o último não é estruturado (ou escasso). Para o CIFAR, nosso código é baseado na classificação de Pytorch e na redução da rede. Para o ImageNet, usamos o código de treinamento oficial do Pytorch Imagenet. As instruções e modelos estão em cada subpasta.
Para experimentos na hipótese do bilhete de loteria, consulte a pasta Cifar/Lottery Ticket.
Nosso ambiente de experimento é Python 3.6 e Pytorch 0.3.1.
Sinta -se à vontade para discutir artigos/código conosco por meio de questões/e -mails!
Sunmj15 em gmail.com
liuzhuangthu em gmail.com
Se você usar nosso código em sua pesquisa, cite:
@inproceedings{liu2018rethinking,
title={Rethinking the Value of Network Pruning},
author={Liu, Zhuang and Sun, Mingjie and Zhou, Tinghui and Huang, Gao and Darrell, Trevor},
booktitle={ICLR},
year={2019}
}


