rethinking network pruning
1.0.0
Este repositorio contiene el código para reproducir los resultados y los modelos capacitados de Imagenet, en el siguiente documento:
Repensar el valor de la poda de red. [ARXIV] [OpenReview]
Zhuang Liu*, Mingjie Sun*, Tinghui Zhou, Gao Huang, Trevor Darrell (*contribución igual).
ICLR 2019. También premio al Mejor Papel en el Taller NIPS 2018 en redes neuronales compactas y profundas.
Las implementaciones de varios métodos de poda contenidas en este repositorio también se pueden usar fácilmente para otros fines de investigación.

Nuestro artículo muestra que para la poda estructurada , el entrenamiento del modelo podado desde cero casi siempre puede lograr un nivel de precisión comparable o más alto que el modelo obtenido del típico "entrenamiento, poda y ajuste fino" (Fig. 1) Procedimiento . Concluimos que para esos métodos de poda:
Nuestros resultados sugieren la necesidad de evaluaciones basales más cuidadosas en futuras investigaciones sobre métodos de poda estructurados.
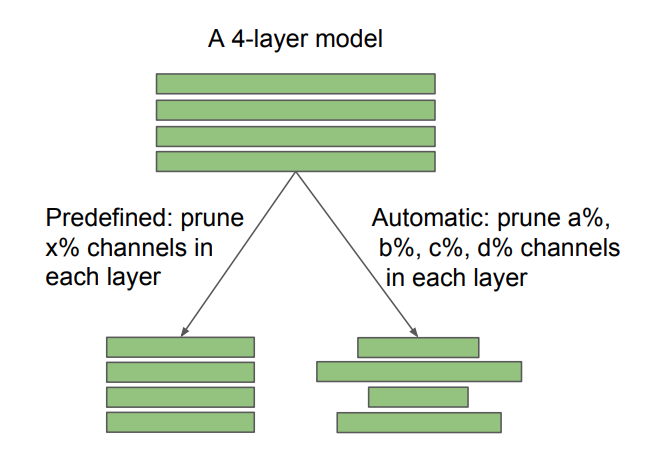
Fig. 2: Diferencia entre arquitecturas objetivo predefinidas y descubiertas automáticamente, en la poda de canales. La relación de poda X está especificada por el usuario, mientras que A, B, C, D están determinados por el algoritmo de poda. La poda escasa no estructurada también se puede ver como automática. Nuestro hallazgo tiene diferentes implicaciones para los métodos predefinidos y automáticos: para un método predefinido, es posible omitir la tubería tradicional de "entrenamiento, poda y ajuste fino" y entrenar directamente el modelo podado; Para los métodos automáticos, la poda puede verse como una forma de aprendizaje de arquitectura.
También comparamos con la "hipótesis de boletos de lotería" (Frankle y Carbin 2019), y encontramos que con una tasa de aprendizaje óptima, la inicialización de "boleto ganador" que se usa en Frankle & Carbin (2019) no trae mejoras sobre la inicialización aleatoria. Para obtener más detalles, consulte nuestro documento.
Evaluamos los siguientes siete métodos de poda.
Los primeros seis están estructurados, mientras que el último no está estructurado (o escaso). Para CIFAR, nuestro código se basa en la clasificación de Pytorch y la bola de red. Para Imagenet, utilizamos el código oficial de entrenamiento de Pytorch ImageNet. Las instrucciones y los modelos están en cada subcarpeta.
Para los experimentos sobre la hipótesis del boleto de lotería, consulte la carpeta CIFAR/Ticket de lotería.
Nuestro entorno experimental es Python 3.6 y Pytorch 0.3.1.
¡No dude en discutir los documentos/código con nosotros a través de problemas/correos electrónicos!
sunmj15 en gmail.com
Liuzhuangthu en Gmail.com
Si usa nuestro código en su investigación, cite:
@inproceedings{liu2018rethinking,
title={Rethinking the Value of Network Pruning},
author={Liu, Zhuang and Sun, Mingjie and Zhou, Tinghui and Huang, Gao and Darrell, Trevor},
booktitle={ICLR},
year={2019}
}


