VITON HD
1.0.0
***** A nova pesquisa de acompanhamento de nossa equipe está disponível em https://github.com/rlawjdghek/stableviton *****
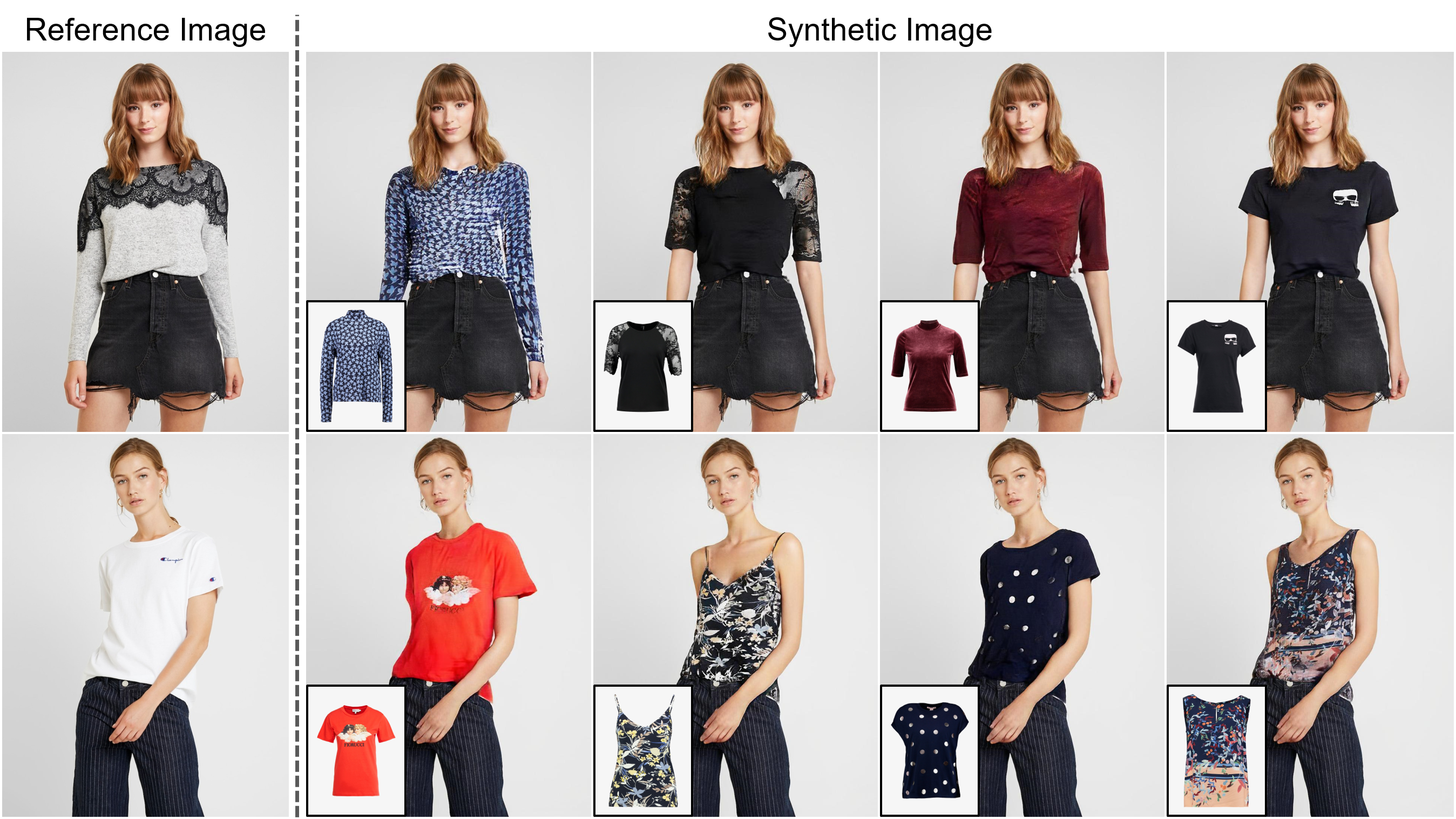
Viton-HD: Try-On virtual de alta resolução via normalização com consciência de desalinhamento
Seunghwan Choi* 1 , Sunghyun Park* 1 , Minsoo Lee* 1 , Jaegul Choo 1
1 kaist
Em CVPR 2021. (* Indica contribuição igual)
Papel: https://arxiv.org/abs/2103.16874
Página do projeto: https://psh01087.github.io/viton-hd
Resumo: A tarefa de try-on virtual baseada em imagem visa transferir um item de roupa de destino para a região correspondente de uma pessoa, que geralmente é abordada ajustando o item à parte do corpo desejada e fundindo o item distorcido com a pessoa. Embora um número crescente de estudos tenha sido realizado, a resolução de imagens sintetizadas ainda é limitada a baixa (por exemplo, 256x192), que atua como a limitação crítica contra a satisfação dos consumidores on -line. Argumentamos que a limitação decorre de vários desafios: à medida que a resolução aumenta, os artefatos nas áreas desalinhadas entre as roupas distorcidas e as regiões de roupas desejadas se tornam notáveis nos resultados finais; As arquiteturas usadas nos métodos existentes têm baixo desempenho na geração de partes do corpo de alta qualidade e na manutenção da nitidez da textura das roupas. Para enfrentar os desafios, propomos um novo método de Try-On virtual chamado Viton-HD que sintetiza com sucesso as imagens virtuais do 1024x768. Especificamente, primeiro preparamos o mapa de segmentação para orientar nossa síntese virtual de try-on e depois ajustar aproximadamente o item de roupas de destino ao corpo de uma determinada pessoa. Em seguida, propomos a normalização do segmento de consciência de alinhamento (alias) e gerador de alias para lidar com as áreas desalinhadas e preservar os detalhes das entradas 1024x768. Através de uma comparação rigorosa com os métodos existentes, demonstramos que o Viton-HD supera altamente as linhas de base em termos de qualidade de imagem sintetizada, qualitativa e quantitativa.
Artigo do ECCV 2022 por nossa equipe (pesquisa de acompanhamento): https://github.com/sangyun884/hr-viton Os códigos de pré-processamento para representação pessoal-agnóstico estão disponíveis em https://github.com/sangyun884/hr-viton.
Clone este repositório:
git clone https://github.com/shadow2496/VITON-HD.git
cd ./VITON-HD/
Instale Pytorch e outras dependências:
conda create -y -n [ENV] python=3.8
conda activate [ENV]
conda install -y pytorch=[>=1.6.0] torchvision cudatoolkit=[>=9.2] -c pytorch
pip install opencv-python torchgeometry
Coletamos 1024 x 768 conjunto de dados de try-on virtual apenas para nossa finalidade de pesquisa . Você pode baixar um conjunto de dados pré-processado do Viton-HD Dropbox. Os pares de imagens de Mulher Frontal View e Top Roupas são divididos em um treinamento e um conjunto de testes com 11.647 e 2.032 pares, respectivamente.
Fornecemos redes pré-treinadas e imagens de amostra do conjunto de dados de teste. Faça o download *.pkl e teste imagens da pasta Viton-HD Google Drive e dos arquivos descompactados *.zip . test.py pressupõe que os arquivos baixados sejam colocados em ./checkpoints/ e ./datasets/ diretórios.
Para gerar imagens virtuais, execute:
CUDA_VISIBLE_DEVICES=[GPU_ID] python test.py --name [NAME]
Os resultados são salvos no diretório ./results/ Você pode alterar o local especificando o argumento --save_dir . Para sintetizar imagens virtuais, com diferentes pares de uma pessoa e um item de roupas, edit ./datasets/test_pairs.txt e execute o mesmo comando.
Todo o material é disponibilizado sob o Creative Commons BY-NC 4.0. Você pode usar, redistribuir e adaptar o material para fins não comerciais , desde que você dê crédito apropriado citando nosso artigo e indique quaisquer alterações que você fez.
Se você achar este trabalho útil para sua pesquisa, cite nosso artigo:
@inproceedings{choi2021viton,
title={VITON-HD: High-Resolution Virtual Try-On via Misalignment-Aware Normalization},
author={Choi, Seunghwan and Park, Sunghyun and Lee, Minsoo and Choo, Jaegul},
booktitle={Proc. of the IEEE conference on computer vision and pattern recognition (CVPR)},
year={2021}
}


