VITON HD
1.0.0
***** 우리 팀의 새로운 후속 연구는 https://github.com/rlawjdgheek/stableviton에서 구할 수 있습니다 *****
Viton-HD : 오정렬 인식 정규화를 통한 고해상도 가상 시도
Seunghwan Choi* 1 , Sunghyun Park* 1 , Minsoo Lee* 1 , Jaegul Choo 1
1 카이스트
CVPR 2021에서. (* 동등한 기여를 나타냅니다)
종이 : https://arxiv.org/abs/2103.16874
프로젝트 페이지 : https://psh01087.github.io/viton-hd
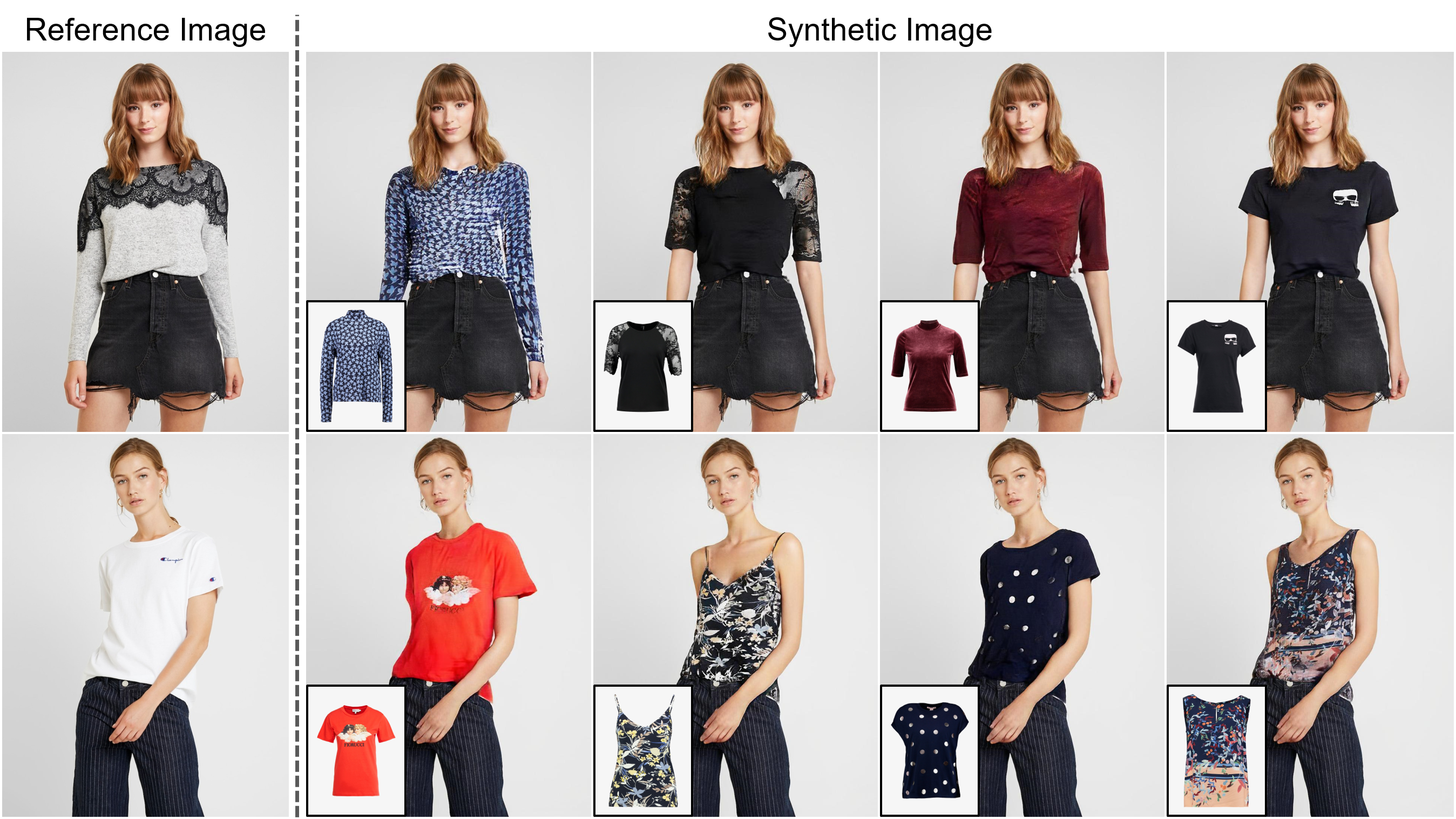
초록 : 이미지 기반 가상 트러스트 트라이언의 작업은 대상 의류 품목을 사람의 해당 영역으로 옮기는 것을 목표로하며, 이는 일반적으로 항목을 원하는 신체 부위에 장착하고 뒤틀린 항목을 사람과 융합하여 태클합니다. 점점 더 많은 연구가 수행되었지만 합성 된 이미지의 해상도는 여전히 낮은 것으로 제한되며 (예 : 256x192) 온라인 소비자를 만족시키는 데 중요한 제한으로 작용합니다. 우리는 한계가 몇 가지 도전에서 비롯된다고 주장합니다. 해상도가 증가함에 따라 뒤틀린 옷과 원하는 의류 지역 사이의 잘못 정렬 된 지역의 인공물은 최종 결과에서 눈에 띄게됩니다. 기존 방법에 사용 된 아키텍처는 고품질 신체 부위를 생성하고 옷의 질감 선명도를 유지하는 데있어 성능이 낮습니다. 도전 과제를 해결하기 위해 1024x768 가상 트리 온 이미지를 성공적으로 합성하는 Viton-HD라는 새로운 가상 시도 방법을 제안합니다. 구체적으로, 우리는 먼저 가상의 시도 합성을 안내하기 위해 세분화 맵을 준비한 다음 주어진 사람의 신체에 대상 의류 품목에 대략적으로 맞습니다. 다음으로, 잘못 정렬 된 영역을 처리하고 1024x768 입력의 세부 사항을 보존하기 위해 정렬 인식 세그먼트 (별칭) 정규화 및 별칭 생성기를 제안합니다. 기존 방법과 엄격한 비교를 통해 Viton-HD는 정 성적 및 정량적으로 합성 된 이미지 품질 측면에서 기준을 능가한다는 것을 보여줍니다.
우리 팀의 ECCV 2022 논문 (후속 연구) : https://github.com/sangyun884/hr-viton preprossing code for person-agnostic 표현은 https://github.com/sangyun884/hr-viton에서 확인할 수 있습니다.
이 저장소를 복제하십시오.
git clone https://github.com/shadow2496/VITON-HD.git
cd ./VITON-HD/
Pytorch 및 기타 종속성을 설치하십시오.
conda create -y -n [ENV] python=3.8
conda activate [ENV]
conda install -y pytorch=[>=1.6.0] torchvision cudatoolkit=[>=9.2] -c pytorch
pip install opencv-python torchgeometry
우리는 연구 목적으로 만 1024 x 768 가상 트리 온 데이터 세트를 수집했습니다. Viton-HD Dropbox에서 전처리 데이터 세트를 다운로드 할 수 있습니다. 정면 뷰 여성 및 최고 의류 이미지 쌍은 각각 11,647 및 2,032 쌍의 테스트 세트로 나뉩니다.
테스트 데이터 세트에서 미리 훈련 된 네트워크 및 샘플 이미지를 제공합니다. *.pkl 을 다운로드하고 Viton-HD Google 드라이브 폴더 및 unzip *.zip 파일에서 이미지를 테스트하십시오. test.py 다운로드 된 파일이 ./checkpoints/ 및 ./datasets/ directories에 배치된다고 가정합니다.
가상의 시도 이미지를 생성하려면 실행 :
CUDA_VISIBLE_DEVICES=[GPU_ID] python test.py --name [NAME]
결과는 ./results/ directory에 저장됩니다. --save_dir 인수를 지정하여 위치를 변경할 수 있습니다. 다른 사람과 의류 품목 쌍의 가상 시도 이미지를 합성하려면 ./datasets/test_pairs.txt 편집하고 동일한 명령을 실행하십시오.
모든 자료는 Creative Commons By-NC 4.0에서 제공됩니다. 논문을 인용 하여 적절한 크레딧을 제공하고 귀하가 한 변경 사항을 표시하는 한, 비상업적 목적 으로 자료를 사용, 재분배 및 조정할 수 있습니다.
이 작업이 귀하의 연구에 유용하다고 생각되면, 우리 논문을 인용하십시오.
@inproceedings{choi2021viton,
title={VITON-HD: High-Resolution Virtual Try-On via Misalignment-Aware Normalization},
author={Choi, Seunghwan and Park, Sunghyun and Lee, Minsoo and Choo, Jaegul},
booktitle={Proc. of the IEEE conference on computer vision and pattern recognition (CVPR)},
year={2021}
}


