VITON HD
1.0.0
***** La nouvelle recherche de suivi de notre équipe est disponible sur https://github.com/rlawjdghek/stableviton *****
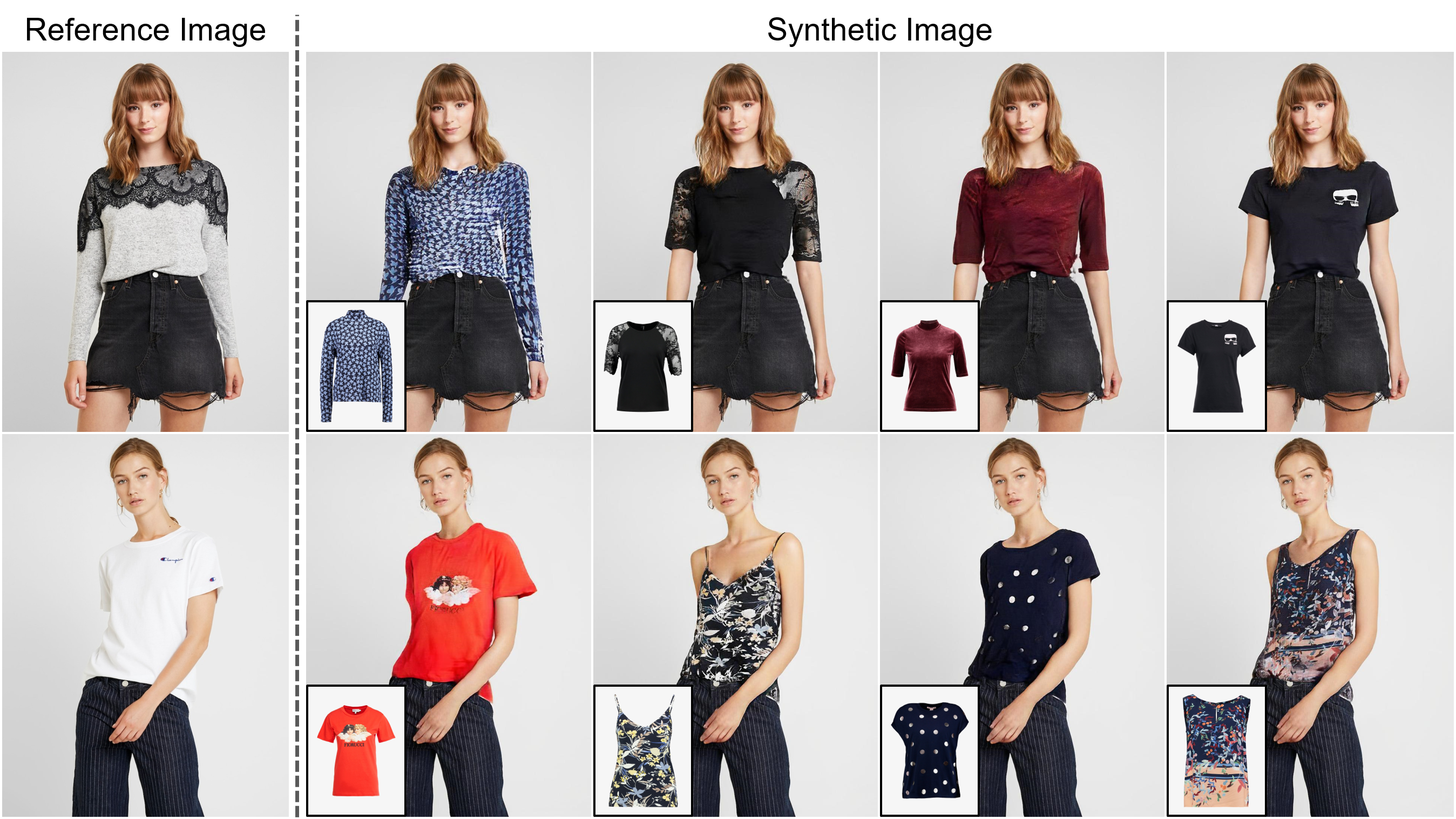
Viton-HD: essai virtuel à haute résolution via une normalisation consciente d'un désalignement
Seunghwan Choi * 1 , Sunghyun Park * 1 , Minssoo Lee * 1 , Jaegul Choo 1
1 kaist
Dans CVPR 2021. (* Indique une contribution égale)
Papier: https://arxiv.org/abs/2103.16874
Page du projet: https://psh01087.github.io/viton-hd
Résumé: La tâche de l'essai virtuel basé sur l'image vise à transférer un élément de vêtements cible sur la région correspondante d'une personne, qui est généralement abordée en ajustant l'élément à la partie du corps souhaitée et en fusionnant l'élément déformé avec la personne. Bien qu'un nombre croissant d'études aient été menées, la résolution des images synthétisées est toujours limitée à faible (par exemple, 256x192), qui agit comme la limitation critique contre la satisfaction des consommateurs en ligne. Nous soutenons que la limitation découle de plusieurs défis: à mesure que la résolution augmente, les artefacts dans les zones mal alignées entre les vêtements déformés et les régions de vêtements souhaitées deviennent visibles dans les résultats finaux; Les architectures utilisées dans les méthodes existantes ont de faibles performances dans la génération de parties du corps de haute qualité et le maintien de la netteté de la texture des vêtements. Pour relever les défis, nous proposons une nouvelle méthode d'essai virtuelle appelée Viton-HD qui synthétise avec succès 1024x768 Images d'essai virtuelles. Plus précisément, nous préparons d'abord la carte de segmentation pour guider notre synthèse d'essai virtuelle, puis ajustez à peu près l'élément de vêtements cible sur le corps d'une personne donnée. Ensuite, nous proposons un générateur de normalisation et d'alias de segment (ALIAS) Award-Aware-Aware Awarement pour gérer les zones mal alignées et préserver les détails des entrées 1024x768. Grâce à une comparaison rigoureuse avec les méthodes existantes, nous démontrons que Viton-HD dépasse fortement les lignes de base en termes de qualité d'image synthétisée à la fois qualitativement et quantitativement.
Document de l'ECCV 2022 de notre équipe (recherche de suivi): https://github.com/sangyun884/hr-viton Les codes de prétraitement pour la représentation de la personne-magnostique sont disponibles sur https://github.com/sangyun884/hr-viton.
Cloner ce référentiel:
git clone https://github.com/shadow2496/VITON-HD.git
cd ./VITON-HD/
Installez Pytorch et autres dépendances:
conda create -y -n [ENV] python=3.8
conda activate [ENV]
conda install -y pytorch=[>=1.6.0] torchvision cudatoolkit=[>=9.2] -c pytorch
pip install opencv-python torchgeometry
Nous avons collecté un ensemble de données Virtual Try-on 1024 x 768 pour notre objectif de recherche uniquement . Vous pouvez télécharger un ensemble de données prétraité à partir de Viton-HD Dropbox. La femme de vue frontale et les paires d'images de vêtements supérieures sont divisées en une formation et un ensemble de test avec 11 647 et 2 032 paires, respectivement.
Nous fournissons des réseaux pré-formés et des exemples d'images à partir de l'ensemble de données de test. Veuillez télécharger *.pkl et tester des images à partir du dossier Viton-HD Google Drive et des fichiers *.zip . test.py suppose que les fichiers téléchargés sont placés dans ./checkpoints/ et ./datasets/ répertoires.
Pour générer des images d'essai virtuelles, exécutez:
CUDA_VISIBLE_DEVICES=[GPU_ID] python test.py --name [NAME]
Les résultats sont enregistrés dans le répertoire ./results/ . Vous pouvez modifier l'emplacement en spécifiant l'argument --save_dir . Pour synthétiser des images d'essai virtuelles avec différentes paires d'une personne et un article de vêtements, modifiez ./datasets/test_pairs.txt et exécutez la même commande.
Tout le matériel est mis à disposition sous Creative Commons BY-NC 4.0. Vous pouvez utiliser, redistribuer et adapter le matériel à des fins non commerciales , tant que vous accordez un crédit approprié en citant notre article et en indiquant les modifications que vous avez apportées.
Si vous trouvez ce travail utile pour vos recherches, veuillez citer notre article:
@inproceedings{choi2021viton,
title={VITON-HD: High-Resolution Virtual Try-On via Misalignment-Aware Normalization},
author={Choi, Seunghwan and Park, Sunghyun and Lee, Minsoo and Choo, Jaegul},
booktitle={Proc. of the IEEE conference on computer vision and pattern recognition (CVPR)},
year={2021}
}


