VITON HD
1.0.0
***** Una nueva investigación de seguimiento de nuestro equipo está disponible en https://github.com/rlawjdghek/stableviton *****
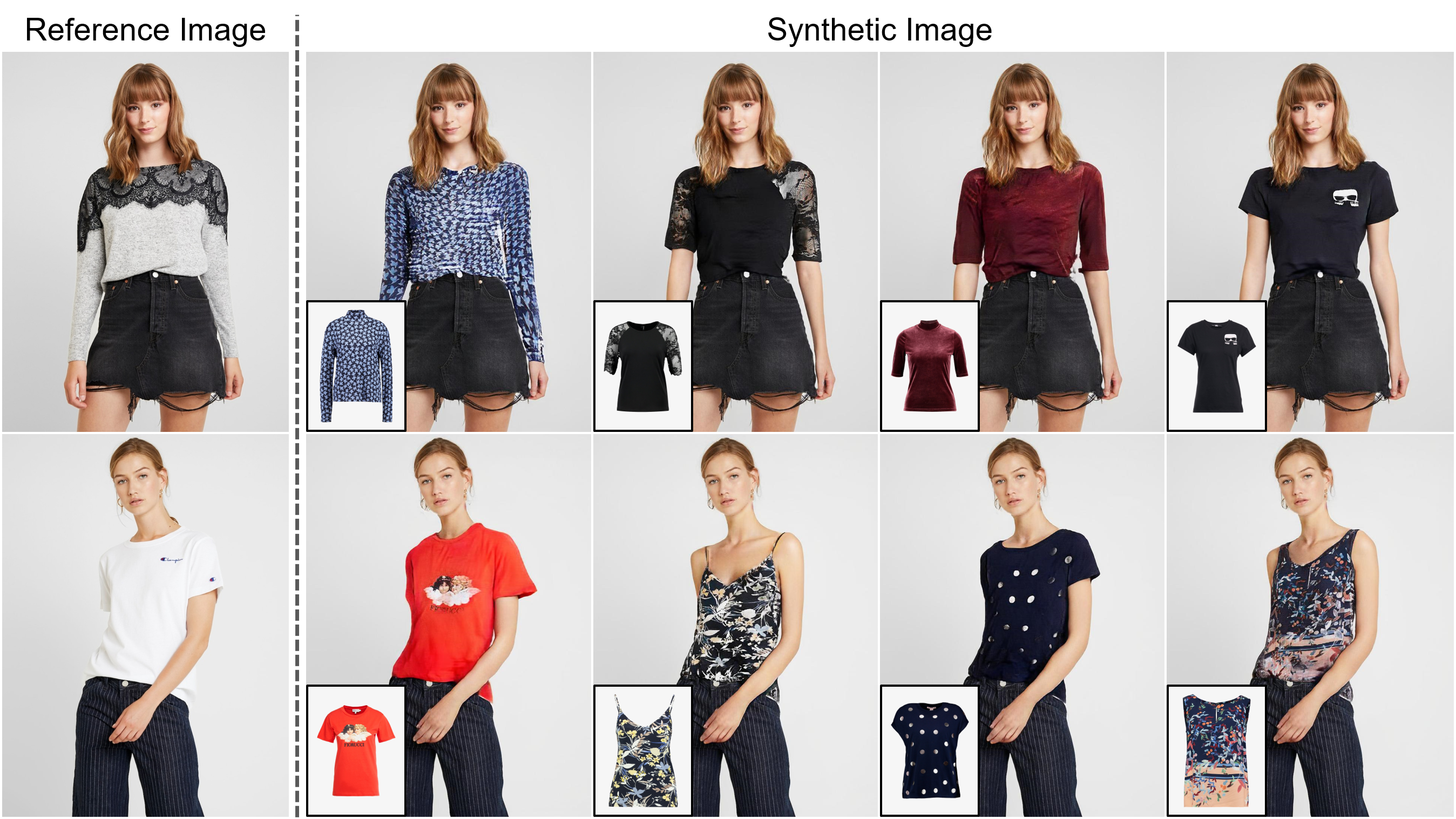
Viton-HD: prueba virtual de alta resolución a través de la normalización consciente de la desalineación
Seunghwan Choi* 1 , Sunghyun Park* 1 , Minsoo Lee* 1 , Jaegul Choo 1
1 kaist
En CVPR 2021. (* Indica una contribución igual)
Documento: https://arxiv.org/abs/2103.16874
Página del proyecto: https://psh01087.github.io/viton-hd
Resumen: La tarea de la prueba virtual basada en imágenes tiene como objetivo transferir un artículo de ropa objetivo a la región correspondiente de una persona, que comúnmente se aborda ajustando el artículo a la parte del cuerpo deseada y fusionando el artículo deformado con la persona. Si bien se han realizado un número cada vez mayor de estudios, la resolución de imágenes sintetizadas todavía se limita a bajo (por ejemplo, 256x192), que actúa como la limitación crítica contra la satisfacción de los consumidores en línea. Argumentamos que la limitación proviene de varios desafíos: a medida que aumenta la resolución, los artefactos en las áreas desalineadas entre la ropa deformada y las regiones de ropa deseadas se vuelven notables en los resultados finales; Las arquitecturas utilizadas en los métodos existentes tienen un bajo rendimiento para generar partes del cuerpo de alta calidad y mantener la nitidez de la textura de la ropa. Para abordar los desafíos, proponemos un nuevo método de prueba virtual llamado Viton-HD que sintetiza con éxito las imágenes de prueba virtuales 1024x768. Específicamente, primero preparamos el mapa de segmentación para guiar nuestra síntesis de prueba virtual, y luego ajustamos aproximadamente el artículo de ropa de destino al cuerpo de una persona determinada. A continuación, proponemos la normalización del segmento (alias) de alineación y el generador de alias para manejar las áreas desalineadas y preservar los detalles de las entradas 1024x768. A través de una comparación rigurosa con los métodos existentes, demostramos que Viton-HD supera mucho las líneas de base en términos de calidad de imagen sintetizada, tanto cualitativa como cuantitativamente.
ECCV 2022 Documento de nuestro equipo (investigación de seguimiento): https://github.com/sangyun884/hr-viton Los códigos de preprocesamiento para la representación de persona-agnóstica están disponibles en https://github.com/sangyun884/hr-viton.
Clon este repositorio:
git clone https://github.com/shadow2496/VITON-HD.git
cd ./VITON-HD/
Instale Pytorch y otras dependencias:
conda create -y -n [ENV] python=3.8
conda activate [ENV]
conda install -y pytorch=[>=1.6.0] torchvision cudatoolkit=[>=9.2] -c pytorch
pip install opencv-python torchgeometry
Recopilamos 1024 x 768 un conjunto de datos de prueba virtual solo para nuestro propósito de investigación . Puede descargar un conjunto de datos preprocesado de Viton-HD Dropbox. Los pares de imágenes de la mujer y la ropa superior de la vista frontal se dividen en un entrenamiento y una prueba con 11,647 y 2,032 pares, respectivamente.
Proporcionamos redes previamente capacitadas e imágenes de muestra del conjunto de datos de prueba. Descargue *.pkl y pruebe imágenes de la carpeta Viton-HD Google Drive y los archivos Unzip *.zip . test.py supone que los archivos descargados se colocan en ./checkpoints/ y ./datasets/ Directorios.
Para generar imágenes de prueba virtuales, ejecute:
CUDA_VISIBLE_DEVICES=[GPU_ID] python test.py --name [NAME]
Los resultados se guardan en el directorio ./results/ . Puede cambiar la ubicación especificando el argumento --save_dir . Para sintetizar imágenes de prueba virtuales con diferentes pares de una persona y un artículo de ropa, edite ./datasets/test_pairs.txt y ejecute el mismo comando.
Todo el material está disponible bajo Creative Commons by-NC 4.0. Puede usar, redistribuir y adaptar el material para fines no comerciales , siempre que otorgue el crédito apropiado citando nuestro documento e indique cualquier cambio que haya realizado.
Si encuentra este trabajo útil para su investigación, cite nuestro artículo:
@inproceedings{choi2021viton,
title={VITON-HD: High-Resolution Virtual Try-On via Misalignment-Aware Normalization},
author={Choi, Seunghwan and Park, Sunghyun and Lee, Minsoo and Choo, Jaegul},
booktitle={Proc. of the IEEE conference on computer vision and pattern recognition (CVPR)},
year={2021}
}


