VITON HD
1.0.0
***** Neue Follow-up-Recherche durch unser Team finden Sie unter https://github.com/rlawjdghek/stableviton *****
Viton-HD: Hochauflösendes virtuelles Versuch durch falsch ausgerichtete Normalisierung
Seunghwan Choi* 1 , Sunghyun Park* 1 , Minsoo Lee* 1 , Jaegul Choo 1
1 Kaist
In CVPR 2021. (* Zeigt einen gleichen Beitrag an)
Papier: https://arxiv.org/abs/2103.16874
Projektseite: https://psh01087.github.io/viton-hd
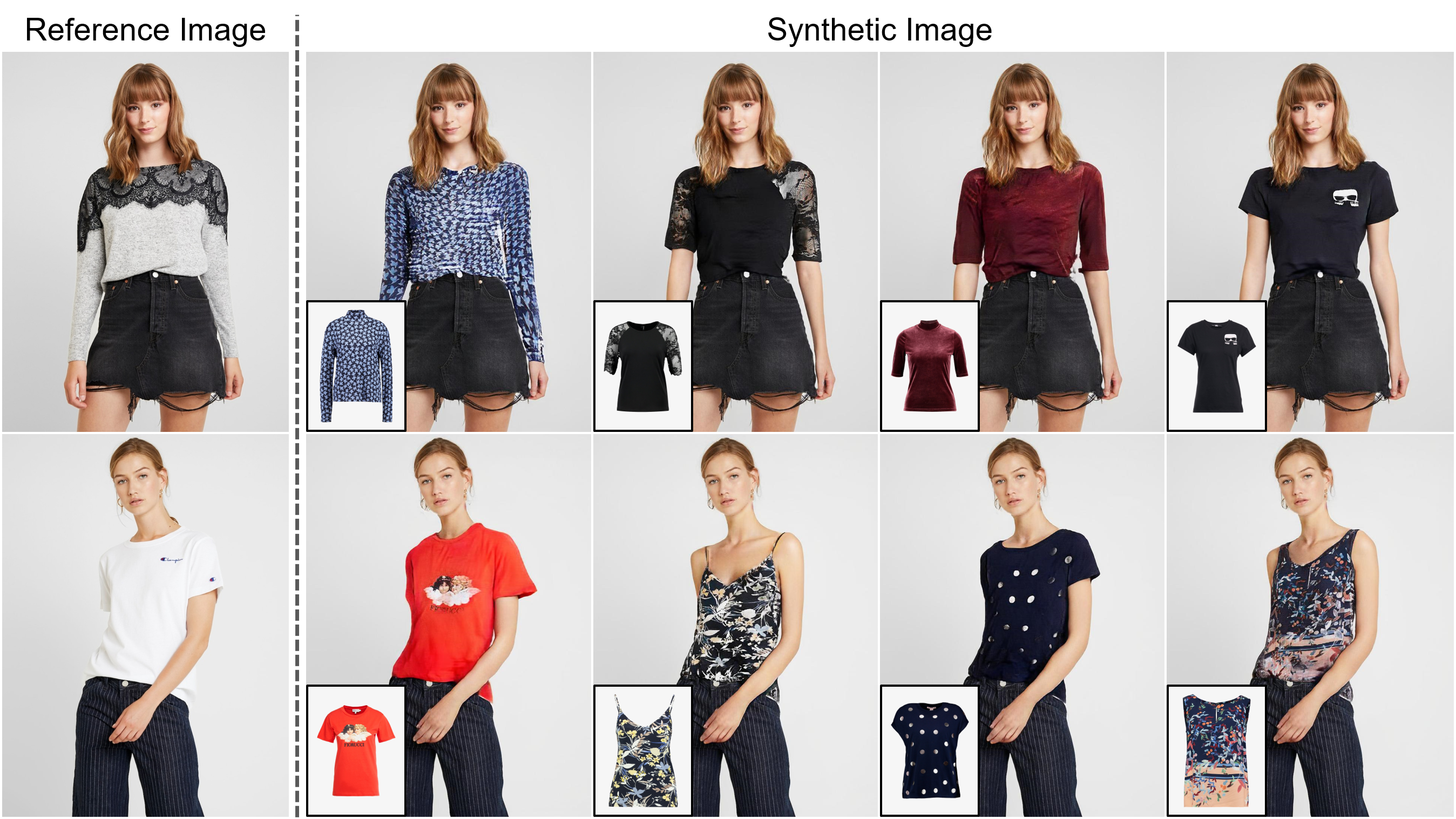
Abstract: Die Aufgabe des bildbasierten virtuellen Anprobierens zielt darauf ab, ein Zielkleidungsstück in die entsprechende Region einer Person zu übertragen, die üblicherweise durch Anpassung des Elements an den gewünschten Körperteil angepasst wird und das verzerrte Element mit der Person verschmilzt. Während eine zunehmende Anzahl von Studien durchgeführt wurde, ist die Auflösung synthetisierter Bilder nach wie vor auf niedrig (z. B. 256x192), was als kritische Einschränkung gegen zufriedenstellende Online -Verbraucher fungiert. Wir argumentieren, dass die Begrenzung aus mehreren Herausforderungen beruht: Mit zunehmender Auflösung werden die Artefakte in den falsch ausgerichteten Bereichen zwischen den verzogenen Kleidung und den gewünschten Kleidungsregionen im Endergebnissergebnisse spürbar. Die in vorhandenen Methoden verwendeten Architekturen haben eine geringe Leistung bei der Erzeugung hochwertiger Körperteile und der Aufrechterhaltung der Texturschärfe der Kleidung. Um die Herausforderungen zu bewältigen, schlagen wir eine neuartige virtuelle Probandenmethode namens Viton-HD vor, die erfolgreich 1024x768 virtuelle Try-On-Bilder synthetisiert. Insbesondere bereiten wir zuerst die Segmentierungskarte vor, um unsere virtuelle Probandensynthese zu leiten, und passen dann grob an das Ziel der Zielkleidung an den Körper einer bestimmten Person. Als nächstes schlagen wir eine Normalisierung und den Alias-Generator (Alignment-Away-Segment) für die Ausrichtung vor, um die falsch ausgerichteten Bereiche zu bewältigen und die Details von 1024x768-Eingängen zu bewahren. Durch strengen Vergleich mit vorhandenen Methoden zeigen wir, dass Viton-HD die Basislinien in Bezug auf die synthetisierte Bildqualität sowohl qualitativ als auch quantitativ stark übertrifft.
ECCV 2022 Papier unseres Teams (Follow-up-Forschung): https://github.com/sangyun884/hr-viton preprocessing codes für person-agnostic repräsentation sind unter https://github.com/sangyun884/hr-viton verfügbar.
Klonen Sie dieses Repository:
git clone https://github.com/shadow2496/VITON-HD.git
cd ./VITON-HD/
Installieren Sie Pytorch und andere Abhängigkeiten:
conda create -y -n [ENV] python=3.8
conda activate [ENV]
conda install -y pytorch=[>=1.6.0] torchvision cudatoolkit=[>=9.2] -c pytorch
pip install opencv-python torchgeometry
Wir haben nur für unseren Forschungszweck 1024 x 768 Virtual Anprover Dataset gesammelt. Sie können einen vorverarbeiteten Datensatz von Viton-HD Dropbox herunterladen. Die Frontal View Woman- und Top -Kleidungsbildpaare sind in ein Training und einen Testset mit 11.647 bzw. 2.032 Paaren aufgeteilt.
Wir stellen vorgebildete Netzwerke und Beispielbilder aus dem Testdatensatz bereit. Bitte laden Sie *.pkl und testen Sie Bilder aus dem Google Drive-Ordner von Viton-Hd und entlarven *.zip Dateien. test.py geht davon aus, dass die heruntergeladenen Dateien in ./checkpoints/ und ./datasets/ Verzeichnisse platziert werden.
Um virtuelle Anprobierbilder zu generieren, rennen Sie:
CUDA_VISIBLE_DEVICES=[GPU_ID] python test.py --name [NAME]
Die Ergebnisse werden im Verzeichnis ./results/ gespeichert. Sie können den Ort ändern, indem Sie das Argument --save_dir angeben. So synthetisieren Sie virtuelle Anprobieren von Bildern mit verschiedenen Personenpaaren und einem Kleidungsstück, bearbeiten Sie ./datasets/test_pairs.txt und führen Sie denselben Befehl aus.
Alle Materialien werden unter Creative Commons BY-NC 4.0 zur Verfügung gestellt. Sie können das Material für nichtkommerzielle Zwecke verwenden, umverteilen und anpassen , solange Sie angemessene Guthaben angeben, indem Sie unser Papier zitieren und alle von Ihnen vorgenommenen Änderungen angeben .
Wenn Sie diese Arbeit für Ihre Forschung nützlich finden, zitieren Sie bitte unser Papier:
@inproceedings{choi2021viton,
title={VITON-HD: High-Resolution Virtual Try-On via Misalignment-Aware Normalization},
author={Choi, Seunghwan and Park, Sunghyun and Lee, Minsoo and Choo, Jaegul},
booktitle={Proc. of the IEEE conference on computer vision and pattern recognition (CVPR)},
year={2021}
}


