BYOSC Build Your Own Scalable Chatbots
1.0.0
Ao se preparar para os exames da universidade, é provado que ter um parceiro é essencial para descobrir lacunas de conhecimento e esclarecer dúvidas específicas sobre o tema tratado durante as aulas. Embora os chatbots com base em LLMs como ChatGPT, Phind e CLOD já estejam fornecendo ajuda aos alunos, eles não podem fornecer uma ajuda/ajuda específica do material nos cursos universitários dos alunos. Propomos criar um sistema para ajustar os chatbots em material específico de cursos específicos. Graças a isso, criaremos amigos de estudo para os cursos de um estudante universitário típico, capazes de responder a dúvidas, gerar perguntas e muito mais!
É possível testar o chatbot neste link.
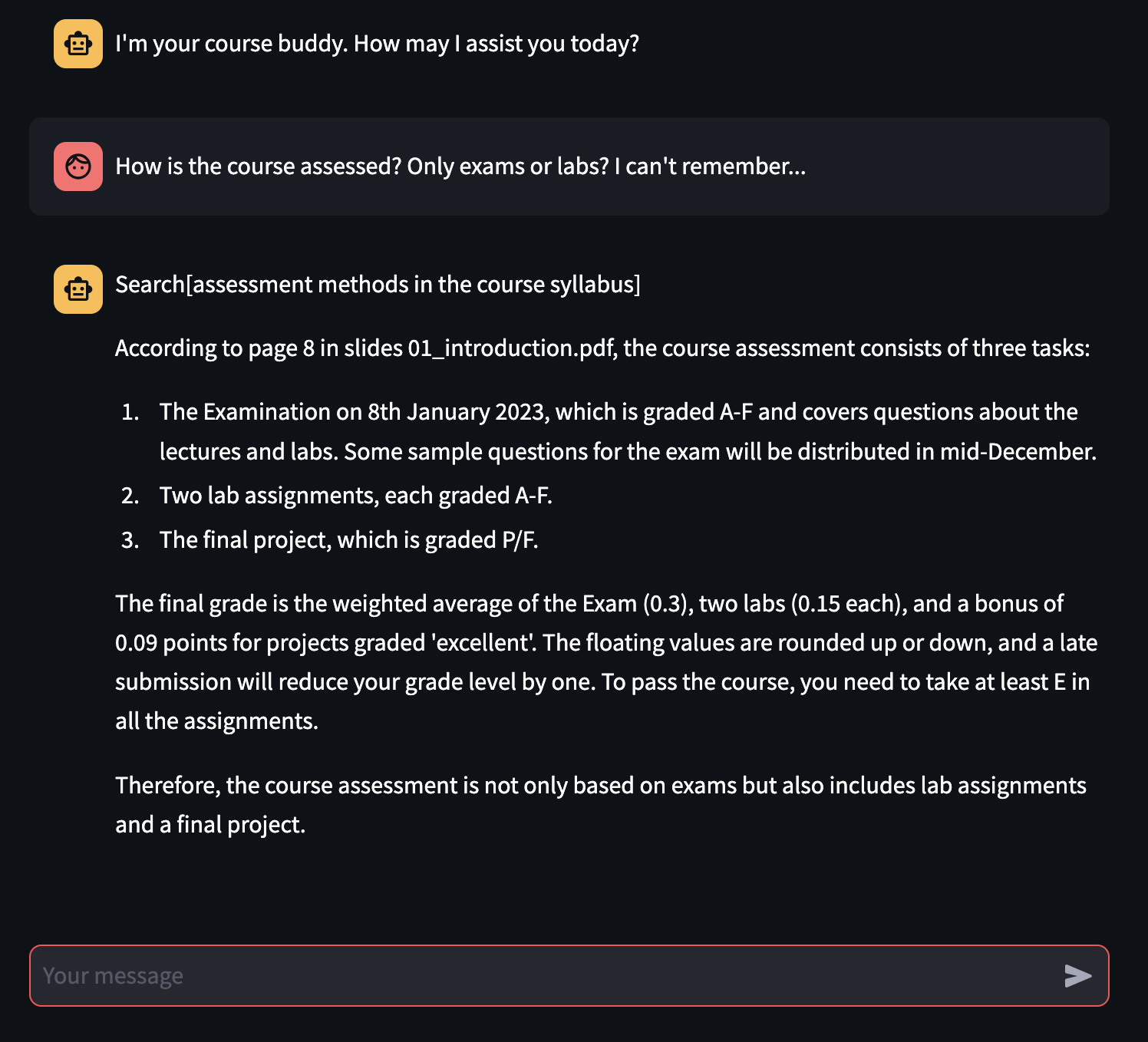
O escopo implícito do projeto (e de todo o curso) é construir uma infraestrutura escalável que possa hospedar nossos MLOPs. Por esse motivo, o pipeline monolítico tradicional de ML é dividido em três processos diferentes: pipeline de recursos , pipeline de treinamento , pipeline de inferência .
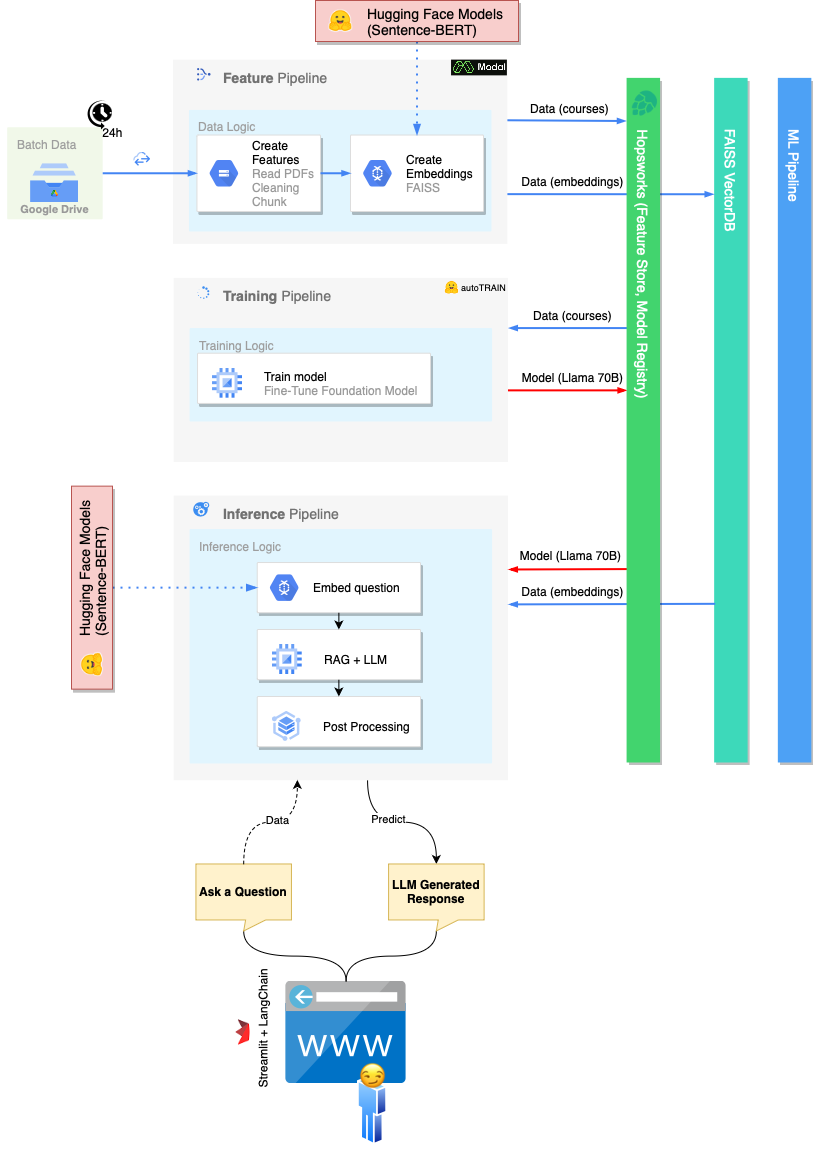
O pipeline de recursos é responsável por:
Existem várias opções para executar o pipeline de recursos:
FeaturePipeline/Reading.ipynbFeaturePipeline/FeaturePipeline.py usando python3 FeaturePipeline/FeaturePipeline.py Uma cópia deste último é ligeiramente modificada no arquivo FeaturePipeline/FeaturePipeline_modal.py para torná -lo executável no serviço de hospedagem modal usando modal [run|deploy] FeaturePipeline/FeaturePipeline.py
O pipeline de treinamento é responsável por:
Para executar o pipeline de treinamento, execute o notebook TrainingPipeline/FineTuning.ipynb
O pipeline de inferência é responsável por:
Para executar o pipeline de inferência, execute streamlit run chatbot_app.py
Embora experimentalmente, o processo de ajuste fino não seja suficiente para tornar o modelo fundamental consistentemente melhor do que um não afastado, o chatbot habilitado para rag pode não apenas responder às perguntas do usuário corretamente seguindo o material original, mas também pode fazer (principalmente) referências corretas de onde a resposta é retirada, o recurso essencial para um aluno que estuda para um exame universitário!
O ajuste fino não funciona tão bem quanto pretendido devido à falta de material usado e recursos computacionais. Como trabalho futuro, queremos melhorar o processo de extração de conhecimento e usar mais poder computacional para resolver os problemas mostrados no relatório.


