BYOSC Build Your Own Scalable Chatbots
1.0.0
Bei der Vorbereitung auf Universitätsprüfungen hat sich erwiesen, dass ein Partner für die Entdeckung von Wissenslücken und die Klärung spezifischer Zweifel an dem während des Unterrichts behandelten Themas ist. Während Chatbots basierend auf LLMs wie ChatGPT, Phind und Clod den Schülern bereits Hilfe bieten, können sie keine Vorlesung/materiellen Hilfe für die Universitätskurse der Studenten anbieten. Wir schlagen vor, ein System zu erstellen, das Chatbots auf bestimmtes Material bestimmter Kurse feinstab. Dank dessen werden wir Lernkumpels für die Kurse eines typischen Universitätsstudenten erstellen, in der wir in der Lage sind, Zweifel zu beantworten, Fragen und mehr zu generieren!
Es ist möglich, den Chatbot unter diesem Link zu testen.
Der implizite Umfang des Projekts (und des gesamten Kurses) besteht darin, eine skalierbare Infrastruktur aufzubauen, die unsere MLOPS beherbergen kann. Aus diesem Grund ist die traditionelle monolithische ML -Pipeline in drei verschiedene Prozesse aufgeteilt: Feature -Pipeline , Trainingspipeline und Inferenzpipeline .
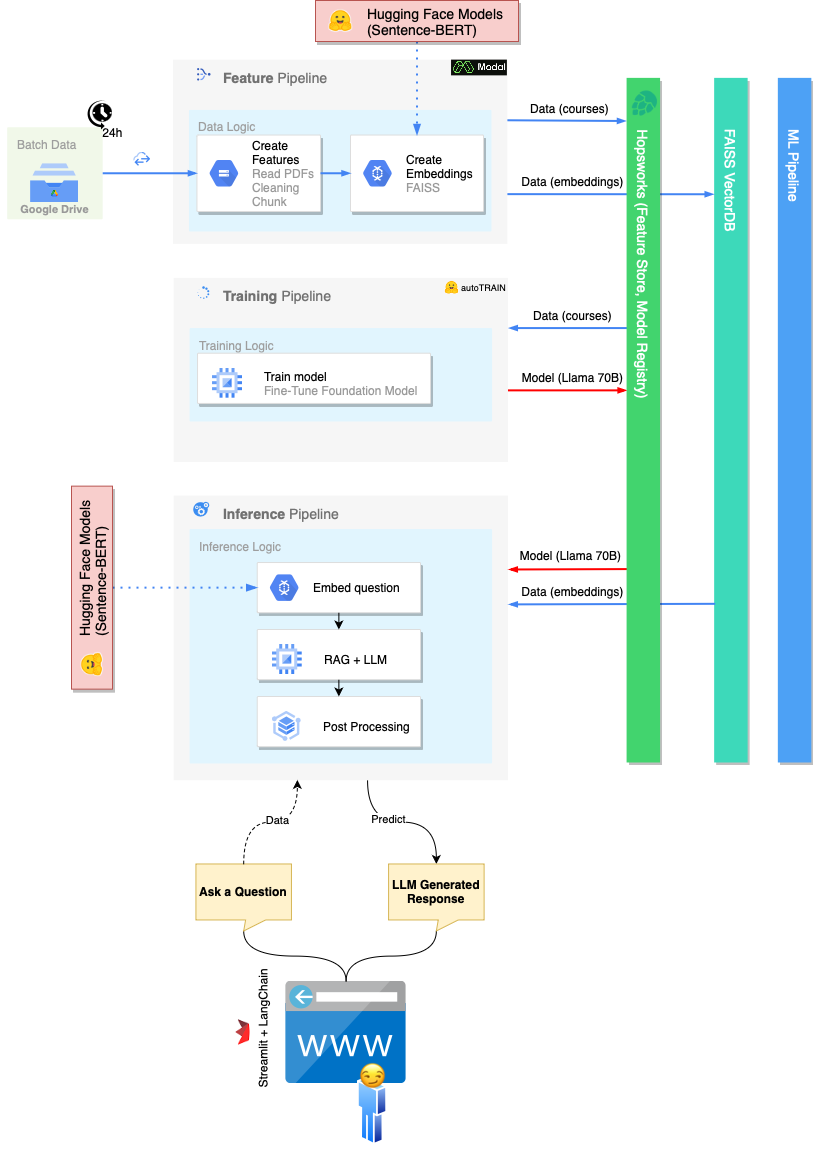
Die Feature -Pipeline ist verantwortlich für:
Es gibt verschiedene Optionen, um die Feature -Pipeline auszuführen:
FeaturePipeline/Reading.ipynb -Notizbuch ausFeaturePipeline/FeaturePipeline.py mit python3 FeaturePipeline/FeaturePipeline.py aus Eine Kopie des letzteren ist in der Datei FeaturePipeline/FeaturePipeline_modal.py geringfügig modifiziert, um sie im Modal -Hosting -Dienst mit modal [run|deploy] FeaturePipeline/FeaturePipeline.py auszuführen.
Die Trainingspipeline ist verantwortlich für:
Führen Sie zum Ausführen der Trainingspipeline die Notebook TrainingPipeline/FineTuning.ipynb aus
Die Inferenzpipeline ist verantwortlich für:
Um die Inferenzpipeline auszuführen, führen Sie streamlit run chatbot_app.py aus
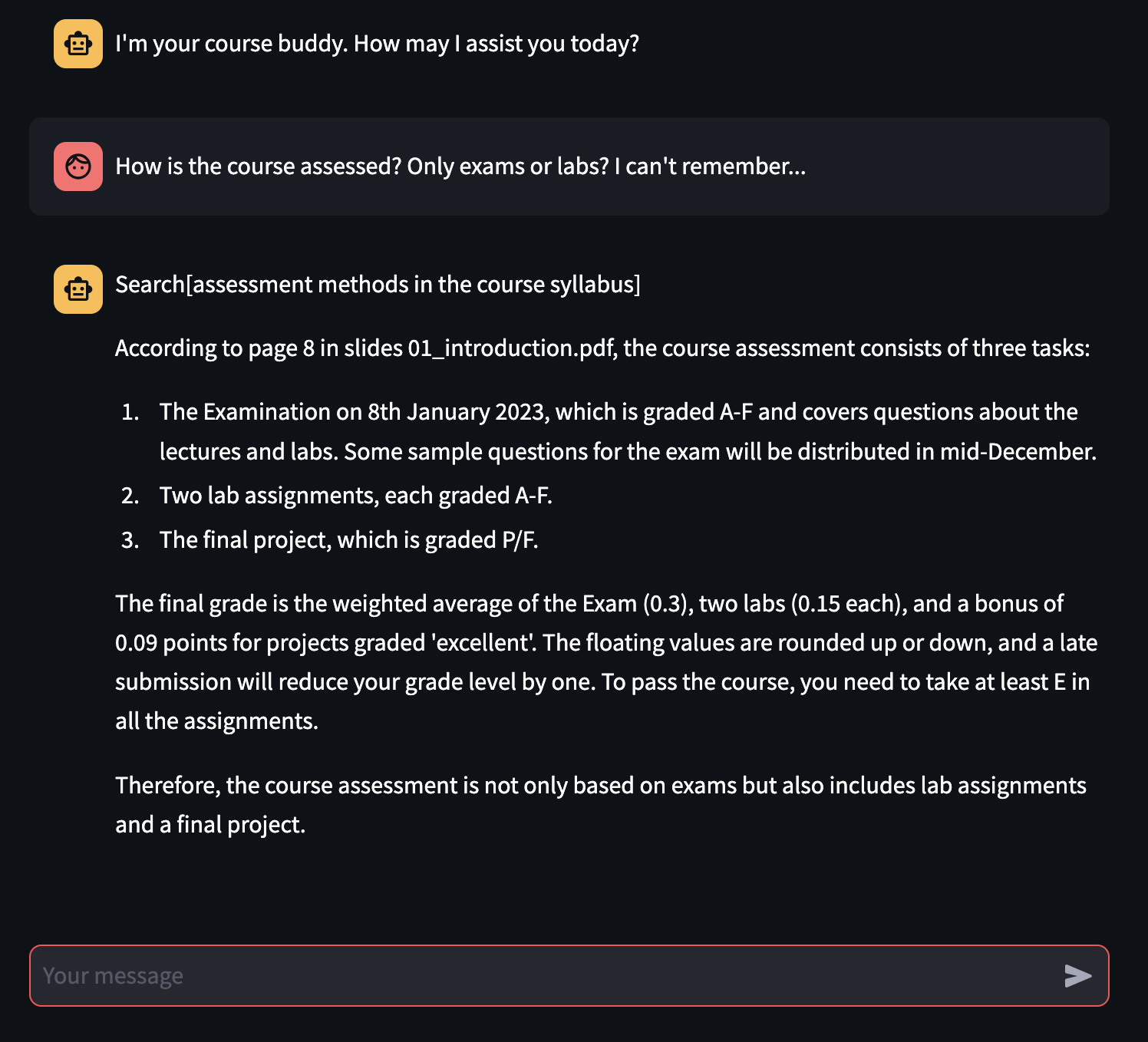
Während experimentell der Feinabstimmungsprozess nicht ausreicht, um das Grundmodell konsequent besser zu machen als ein nicht feiner abgestimmter, kann der RAG-fähige Chatbot nicht nur die Fragen des Benutzers, die dem Originalmaterial folgen, nicht nur korrekt beantworten, sondern auch in der Lage ist, (meistens) korrekte Referenzen zu geben, von denen die Antwort entnommen wird, wesentlich für eine Studienstudie für eine Universitätsuntersuchung!
Die Feinabstimmung funktioniert aufgrund des Mangels an verwendeten Materialien und den Rechenressourcen nicht so gut wie beabsichtigt. Als zukünftige Arbeit möchten wir den Prozess-Extraktionsprozess verbessern und mehr Rechenleistung verwenden, um die im Bericht angegebenen Probleme anzugehen.


