BYOSC Build Your Own Scalable Chatbots
1.0.0
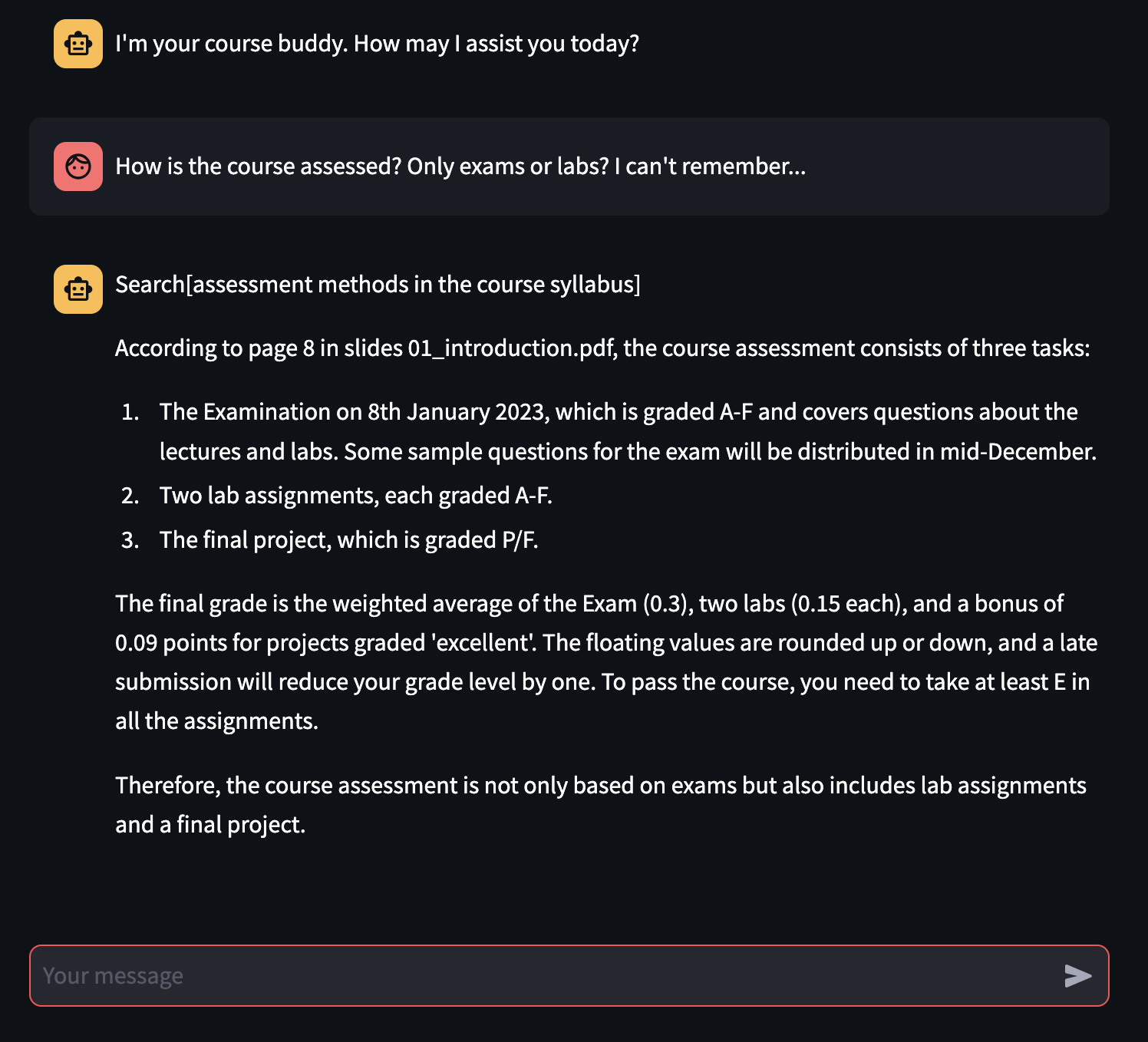
Lors de la préparation des examens universitaires, un partenaire s'est avéré essentiel pour découvrir les lacunes de connaissances et clarifier des doutes spécifiques sur le sujet traité pendant les cours. Bien que les chatbots basés sur des LLM tels que Chatgpt, Phind et CLOD fournissent déjà de l'aide aux étudiants, ils ne peuvent pas fournir une aide spécifique à des cours / matériaux sur les cours universitaires des étudiants. Nous proposons de créer un système pour affiner les chatbots sur du matériel spécifique de cours spécifiques. Grâce à cela, nous créerons des copains d'étude pour les cours d'un étudiant universitaire typique, capable de répondre aux doutes, de générer des questions et plus encore!
Il est possible de tester le chatbot sur ce lien.
La portée implicite du projet (et de l'ensemble du cours) est de construire une infrastructure évolutive qui peut héberger nos MOPL. Pour cette raison, le pipeline ML monolithique traditionnel est divisé en trois processus différents: pipeline de caractéristiques , pipeline d'entraînement , pipeline d'inférence .
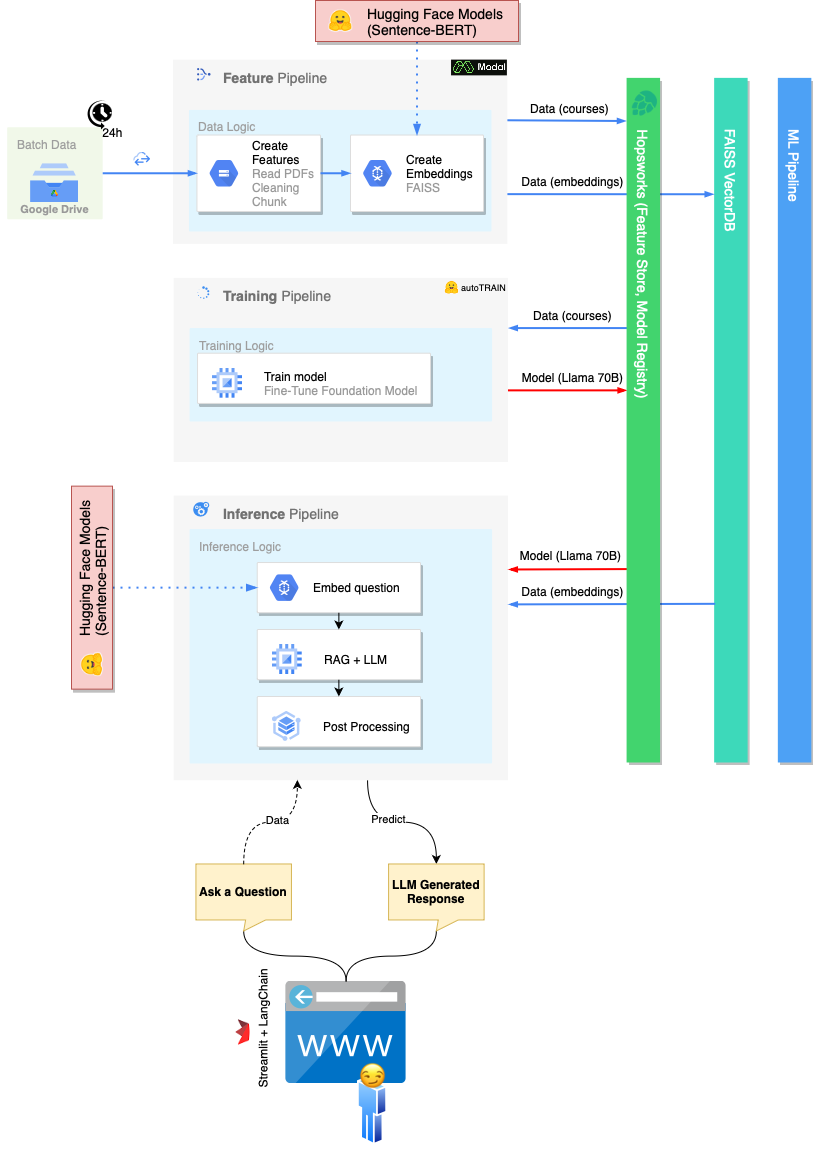
Le pipeline de fonctionnalités est en charge:
Il existe plusieurs options pour exécuter le pipeline de fonctionnalités:
FeaturePipeline/Reading.ipynb NotebookFeaturePipeline/FeaturePipeline.py à l'aide de python3 FeaturePipeline/FeaturePipeline.py Une copie de ce dernier est légèrement modifiée dans le fichier FeaturePipeline/FeaturePipeline_modal.py pour le rendre exécutable sur le service d'hébergement modal à l'aide de modal [run|deploy] FeaturePipeline/FeaturePipeline.py
Le pipeline de formation est en charge de:
Pour exécuter le pipeline d'entraînement, exécutez le Notebook TrainingPipeline/FineTuning.ipynb
Le pipeline d'inférence est en charge de:
Pour exécuter le pipeline d'inférence, exécutez streamlit run chatbot_app.py
Bien que expérimentalement le processus de réglage fin ne soit pas suffisant pour rendre le modèle fondamental systématiquement meilleur que non réglé, le chatbot compatible avec Rag est capable non seulement de répondre correctement aux questions de l'utilisateur suivant le matériel d'origine, mais il est également capable de donner (principalement) des références correctes de la réponse de la réponse, une caractéristique essentielle pour un étudiant étudiant pour un examen universitaire!
Le réglage fin ne fonctionne pas aussi bien que prévu en raison du manque de matériau utilisé et des ressources de calcul. En tant que travaux futurs, nous voulons améliorer le processus d'extraction des connaissances et utiliser plus de puissance de calcul pour résoudre les problèmes présentés dans le rapport.


